Vision Transformers for Dense Prediction论文笔记
文章目录
- Vision Transformers for Dense Prediction, ICCV, 2021
- 一、背景介绍
- 二、网络结构
- 三、实验结果
-
-
- 1.语义分割实验
- 2.消融实验
-
Vision Transformers for Dense Prediction, ICCV, 2021
一、背景介绍
本篇论文主要提出一种网络,基于Transformer去进行密集预测。
众所周知,对于密集预测任务,常见的网络架构为Encoder+Decoder结构。当Encoder提取的特征有损时,Decoder很难去进行恢复。但是目前常用的卷积网络架构常常使用下采样方式,**逐步增加感受野,将低级特征分组为抽象的高级特征,同时确保网络的内存和计算需求保持易于处理。**但是,下采样有一个明显的缺点,特征分辨率和粒度(我感觉这里的粒度像是细粒度特征)在模型的更深层特征丢失,在Decoder中难以恢复。虽然,特征分辨率和粒度对于图像分类这种任务可能影响不大,但是对于密集预测任务如语义分割而言却是极为重要的。
目前为了缓解特征和粒度的丢失,不少方法被提出来,如以更高的输入分辨率进行训练(如果计算预算允许)、扩张卷积 [51] 以快速增加感受野而无需下采样、适当放置从编码器的多个阶段到解码器的跳过连接,或者,更多最近,通过在整个网络中并行连接多分辨率表示。 作者认为这些方法始终没有脱离使用卷积,故作者想要使用Transformer,如ViT来进行特征提取。
作者认为与全卷积网络不同,视觉转换器主干在计算初始化图像嵌入后放弃显示下采样操作,并在所有处理阶段保持具有恒定维度的表示。此外,他在每个阶段都有一个全局感受野。
二、网络结构
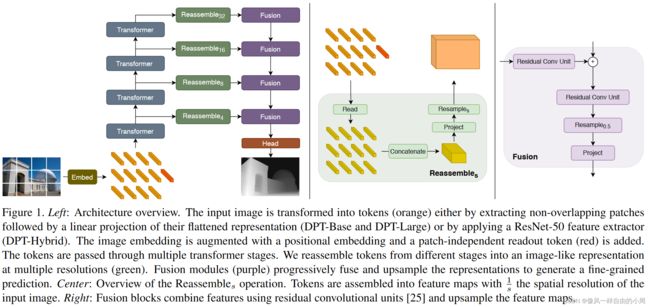
还是类似Swin Transformer有着上下采样操作。
Encoder部分就是直接使用的VIT,不同点在于作者令patch大小为16x16,输入维度为768(ViT-Base)和1024(ViT-Large)。作者这样解释道说768已经大于等于16x16x3了,这也就意味着可以保留对任务有益的信息。
Decoder部分,作者分别先选取ViT中的四个Transformer block的输出,通过Ressemble模块先把特征转化为卷积能够处理的特征,之后进行上采样或下采样,然后通过Fusion模块将这4个层的特征连接起来。这样便得到最终的输出了,但最终的输出尺寸大小并不是输入图片的原图大小,而是原图的一半。后续会根据具体任务添加不同的Head。
Ressemble模块分为三个部分Read,这个部分就是对于readout token如何处理,因为接下来要通过Concatenate模块将Transformer Block的输出转化为卷积能够处理的特征,故需要从原来的 R N p + 1 × D R^{N_p+1\times D} RNp+1×D变成 R N p × D R ^{N_p\times D} RNp×D。关于readout token如何处理作者提出了三种解决方案:
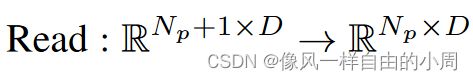
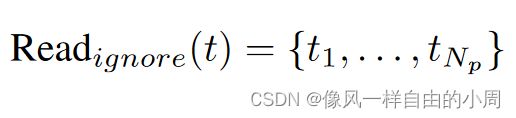
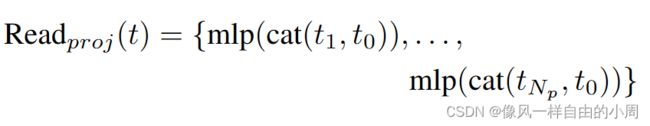
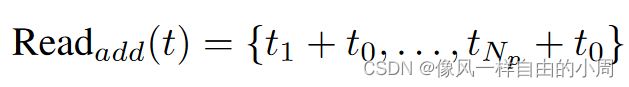
Concatenate模块就比较简单了,之前Transformer Block输出特征维度是 R N p × D R^{N_p\times D} RNp×D,而卷积需要的特征维度是类似于 H × W × C H\times W\times C H×W×C,这就需要进行转化了,因为Transformer Block输出特征始终令token个数 N p = H W / p 2 N_p=HW/p^2 Np=HW/p2。故只需要reshape类似的操作即可。接下来便是需要进行上下采样得到不同尺度的特征了,这里作者使用了卷积进行下采样,反卷积进行上采样(密集预测常见做法,因为ViT每个Transformer Block模块输出特征尺寸一样,且 p = 16 p=16 p=16,故需要使用其它方法进行上下采样,这里作者是基于卷积,而Swin Transformer却不是基于卷积)。
最后就是不同尺度的特征融合模块Fusion了。这个模块内容就简单很多了,其中的Residual Conv Unit模块就是一个残差卷积模块。Resample模块使用的是线性插值。
class ResidualConvUnit(nn.Module):
"""Residual convolution module."""
def __init__(self, features):
"""Init.
Args:
features (int): number of features
"""
super().__init__()
self.conv1 = nn.Conv2d(
features, features, kernel_size=3, stride=1, padding=1, bias=True
)
self.conv2 = nn.Conv2d(
features, features, kernel_size=3, stride=1, padding=1, bias=True
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
"""Forward pass.
Args:
x (tensor): input
Returns:
tensor: output
"""
out = self.relu(x)
out = self.conv1(out)
out = self.relu(out)
out = self.conv2(out)
return out + x
class FeatureFusionBlock(nn.Module):
"""Feature fusion block."""
def __init__(self, features):
"""Init.
Args:
features (int): number of features
"""
super(FeatureFusionBlock, self).__init__()
self.resConfUnit1 = ResidualConvUnit(features)
self.resConfUnit2 = ResidualConvUnit(features)
def forward(self, *xs):
"""Forward pass.
Returns:
tensor: output
"""
output = xs[0]
if len(xs) == 2:
output += self.resConfUnit1(xs[1])
output = self.resConfUnit2(output)
output = nn.functional.interpolate(
output, scale_factor=2, mode="bilinear", align_corners=True
)
return output
三、实验结果
由于我只对语义分割比较熟悉,故只看了语义分割的相关实验,当然消融实验也看了。
在此,先说一下因为论文通过最后一个Fusion输出的特征图只有原图的1/2,故需要添加Head将特征图上采样到原图大小。
head = nn.Sequential(
nn.Conv2d(features, features, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(True),
nn.Dropout(0.1, False),
nn.Conv2d(features, num_classes, kernel_size=1),
Interpolate(scale_factor=2, mode="bilinear", align_corners=True), # 上采样两倍
)
self.auxlayer = nn.Sequential(
nn.Conv2d(features, features, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(True),
nn.Dropout(0.1, False),
nn.Conv2d(features, num_classes, kernel_size=1),
)
1.语义分割实验
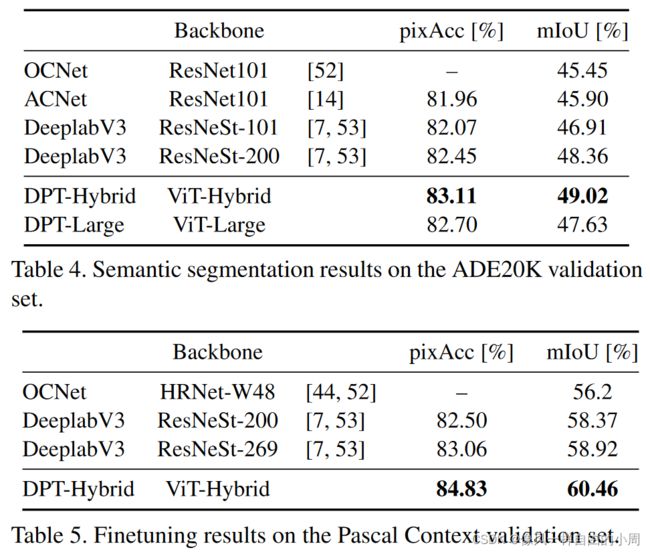
其中ViT-Large因为数据集相对较小,故性能相对较差。此外,在Table 5中作者在小数据集上进行了微调结果还是挺不错的。下面的可视化结果可以发现DPT 倾向于产生更清晰和更细粒度的对象边界描绘,并且在某些情况下预测也不会那么混乱。
2.消融实验
这里面有个实验我是比较感兴趣的,就是Inference resolution。下面我们来看看消融实验都干了些啥。
- Skip connections: 作者探讨了ViT不同层的输出,得到结果发现从包含低级特征的层以及包含高级特征的更深层中挖掘特征是有益的。
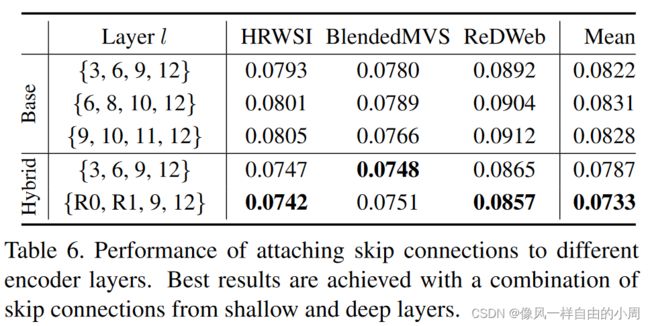
-
Readout token: 作者方案中提供了三种readout token处理方式,效果如下。

-
Backbones:

-
Inference speed:
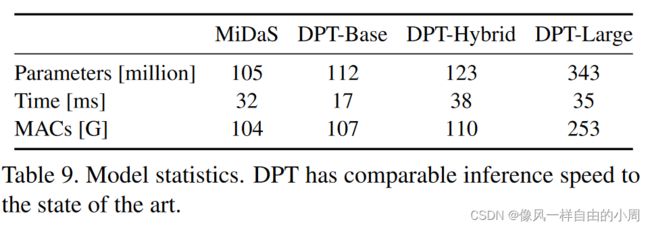
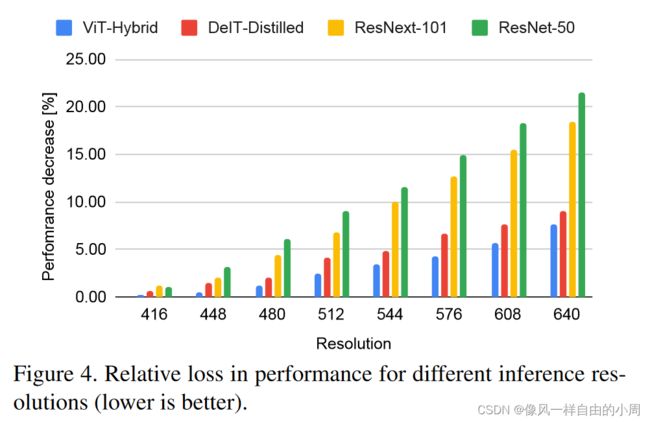
- Inference resolution: 虽然全卷积架构在其最深层可以具有较大的有效感受野,但靠近输入的层是局部的并且具有较小的感受野。因此,当以与训练分辨率明显不同的输入分辨率执行推理时,性能会受到严重影响。另一方面,Transformer 编码器在每一层都有一个全局感受野。我们推测这会降低 DPT 对推理分辨率的依赖。为了检验这个假设,我们绘制了在高于 384 × 384 像素训练分辨率的分辨率下执行推理时不同架构的性能损失。我们在图 4 中绘制了相对于在训练分辨率下执行推理的性能的相对性能下降。我们观察到,随着推理分辨率的增加,DPT 变体的性能确实下降得更加优雅。