ASRT语音识别系统部署及模型训练笔记
ASRT语音识别系统部署及模型训练笔记
前言
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub上。
GitHub地址:nl8590687/ASRT_SpeechRecognition
国内Gitee镜像地址:AI柠檬/ASRT_SpeechRecognition
文档地址:ASRT语音识别工具文档
本文主要是记录一下我在参考文章:教你如何使用ASRT训练中文语音识别模型 并完成部署和训练过程中的操作步骤。文章作者比较惜字如金,文中很多细节之处没有细讲,我在windows上进行部署的时候踩了比较多的坑,特此记录下。
1. 硬件条件:
总所周知,跑神经网络,要用到英伟达的显卡。
本人硬件参数:
以下是官方配置建议,我的显卡肯定不达标,但我想着最多训练久一点[捂脸]。

2. 下载源代码
按照如图所示步骤即可直接下载最新源代码压缩包。

下载完成后,需要进行解压。之后,如果GitHub仓库上如果代码有更新,重复上述步骤即可。
我的解压路径:
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition

3. 运行环境搭建
3.1 操作系统安装CUDA、cuDNN
训练模型请安装好Nvidia GPU驱动和CUDA、cuDNN。
3.1.1 安装步骤
安装过程略过。参考文章:Windows 安装 CUDA/cuDNN
3.1.2 查看CUDA版本:
nvcc -V

3.1.3 查看cuDNN版本:
进入 cuda 的安装路径, C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include,找到 cudnn_version.h 选中,以记事本方式打开。

这里,我的是8.8.1
3.2 安装Anaconda
3.2.1 安装步骤
安装步骤略过,参考文章:anaconda的安装和使用
3.2.2 查看conda版本信息:
Anaconda PowerShell控制台中输入以下命令:
conda info

我的conda版本是23.1.0
4. 项目部署
4.1 conda创建python虚拟环境
首先请确保Anaconda 创建python3.10的虚拟环境。
4.1.1 操作步骤
我给asrt单独创建了一个名为:asrt_env的虚拟环境:
Anaconda PowerShell控制台中输入以下命令:
conda create -n asrt_env python=3.10
4.1.2 查看虚拟环境基本信息
Anaconda PowerShell控制台中输入以下命令:
conda env list
conda activate asrt_env
conda info

4.2 为ASRT项目安装依赖包
4.2.1 安装依赖包:
Anaconda PowerShell控制台中,我们激活asrt_env虚拟环境,并cd到ASRT项目下,通过
requirements.txt为其安装依赖包:
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_v_1_3_0
pip install -r requirements.txt
这是一个漫长的安装过程,甚至经常因为网速慢导致下载失败。
4.2.2 踩坑记录:
我在安装tensorflow-gpu时失败了好几次,因为我conda使用的是清华源,下载tensorflow-gpu及其缓慢:

后来网上找到了提速的办法:
关掉原本的控制台,重新通过asrt_env进入ASRT项目目录,
单独先使用中科大的镜像将tensorflow-gpu安装好:
conda env list
conda activate asrt_env
pip --default-timeout=1000000 install -U -i https://pypi.mirrors.ustc.edu.cn/simple/ --upgrade tensorflow-gpu==2.8.4

然后重新安装requirements.txt内的包:
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
pip install -r requirements.txt

4.3 下载数据集
4.3.1 下载数据集目录
- 语音文件:wav格式的文件,diff文件头 采样频率16 kHz, 采样位数16 bits, 256 samples, 2 bytes 长度 (是不是raw格式都可以,只要能够正确读取内容即可);
- **标签文件:txt格式,**语音数据文件的文本标签。
在ASRT根目录下运行以下命令以下载推荐的默认数据集(包括语音和标签文件)的目录:
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
python download_default_datalist.py
根据提示即可完成下载,在对应的数据列表目录中即可看到下载的数据列表。

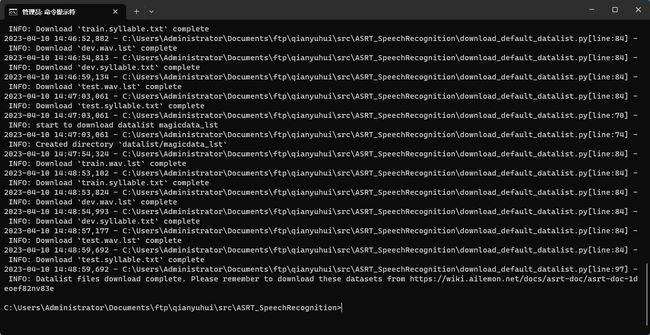
下载成功后,在/datalist/目录下的文件为AI柠檬博主整理好的数据集目录(包括语音和标签文件),对应的数据集仍需另外下载。

以thchs30为例,主要有6个文件,3个.txt,3个.lst

.txt文件是语音文件的文本标签列表:

.lst文件是语音文件的存储路径列表:

4.3.2下载数据集
(1) 下载
目录下好了,然后就是去下载几十个G的语音数据集了。
点击链接数据格式与可用的数据集
即可跳转到一些语音数据集的下载链接页面,一共8个压缩包,把他们全部下下来:

经过漫长的下载过程,下下来之后是这样的。我在ASRT根目录下创建了/data/speech_data/文件夹,把压缩包都放到了这里。

(2) 解压
a. 整体批量解压
下载完成之后,我们使用WinRAR解压进行批量解压(一定要按照我的说的步骤操作!):

解压也是一个漫长的过程,解压后如图:
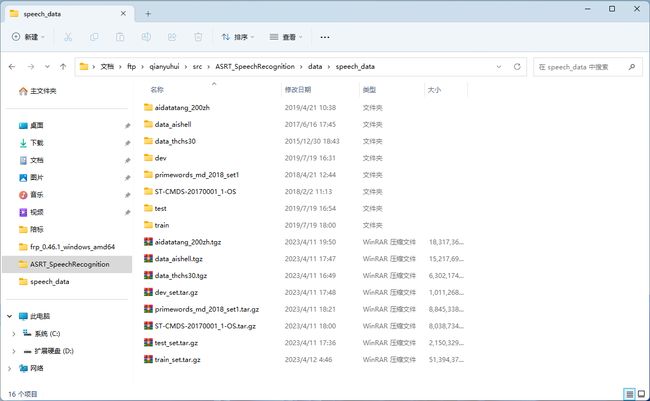
整体解压完成后,会看到数据集data_thchs30、primewords_md_2018_set1、ST-CMDS-20170001_1-OS已经全部解压完毕;aidatatang_200zh、data_aishell目录下依然有.tar.gz文件需要继续解压;dev、test、train都属于MagicData数据集,需要创建一个名为magicdata的文件夹,然后把dev、test、train都移进去。
b. 继续解压aidatatang_200zh
aidatatang_200zh 的数据集需要额外继续解压。
分别进入
speech_data/aidatatang_200zh/corpus/dev/
speech_data/aidatatang_200zh/corpus/test/
speech_data/aidatatang_200zh/corpus/train/
继续用WinRAR解压:

c. 继续解压data_aishell
data_aishell的数据集需要额外继续解压。
进入speech_data/data_aishell/wav继续用WinRAR解压:

d. magicdata数据集的单独处理操作
dev、test、train都属于MagicData数据集,需要创建一个名为magicdata的文件夹,然后把dev、test、train都移进去:
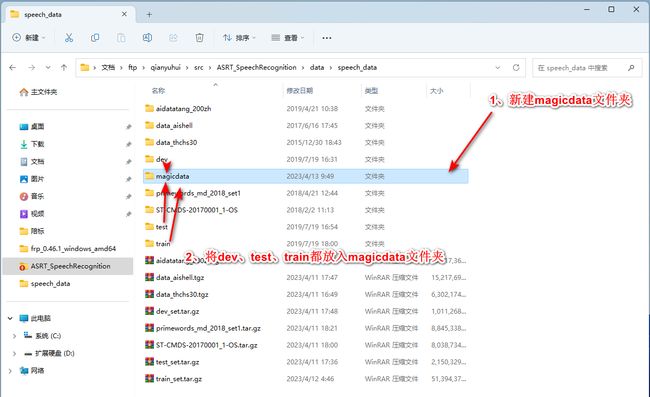

注意:
- 在Windows系统上使用WinRAR不要选择“解压到XXX(压缩包名)”,一定要选择“解压到当前文件夹”。
- 关于数据集文件的路径树,可以直接参考datalist目录下的*.lst和*.txt文件中的内容进行排放。datalist和 data。
- 下载后的文件解压,目录对应如下:
/data/speech_data/data_thchs30/train/*.wav
/data/speech_data/data_thchs30/dev/*.wav
/data/speech_data/data_thchs30/test/*.wav
/data/speech_data/ST-CMDS-20170001_1-OS/*.wav
- magicdata的三个压缩包:dev、test、train的解压路径如下所示:



4.4 修改配置文件
4.4.1 构建目录与数据集文件的关联
ASRT项目的配置文件主要是位于根目录下的asrt_config.json,用代码编辑器打开。
asrt_config.json用于配置相关语音数据集目录、语音文件和标签文件(data_list、data_path、label_list),可按需修改。如图,需要修改data_path的路径。

(1) 相对路径的写法:
因为我把数据集文件都放在更目录下的data目录下(与datalist同级),因此这里我参考data_list和lable_list的写法,采用相对路径的写法定位到speech_data:

(2) 绝对路径的写法:
Json中的绝对路径需要用【\】表示:

4.4.2 模型训练参数调整:
训练参数主要在 train_speech_model.py文件中修改。

具体参数详见文章:教你如何使用ASRT训练中文语音识别模型
我这边主要是改了batch_size, 默认是16我改成了8,降低GPU的工作压力。
4.5 训练模型
接下来就是运行项目,开始训练项目:
Anaconda PowerShell控制台中输入以下命令:
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
python train_speech_model.py

训练过程中会在/save_models/ 目录下对应的模型名称里保存了很多模型参数文件。


PS: AI柠檬博主曾经训练了几个版本,放在Github上,如果你并不需要训练自己的定制语音库,我们可以直接前往下载。
4.6 评估模型准确率
接下来的我们主要介绍【评估模型准确率】和【语音识别测试】。由于我的显卡条件并不好,训练需要花费较长时间(打算升级下我的显卡[捂脸])。这里我直接使用AI柠檬博主已经训练好的最新版本(1.3.0)模型参数文件,进行演示。(注意:经过我的实操,1.3.0的模型参数文件,不适用python3.10,适用于3.9,其他版本如6、7、8未测试)
模型评估主要是 evaluate_speech_model.py文件。
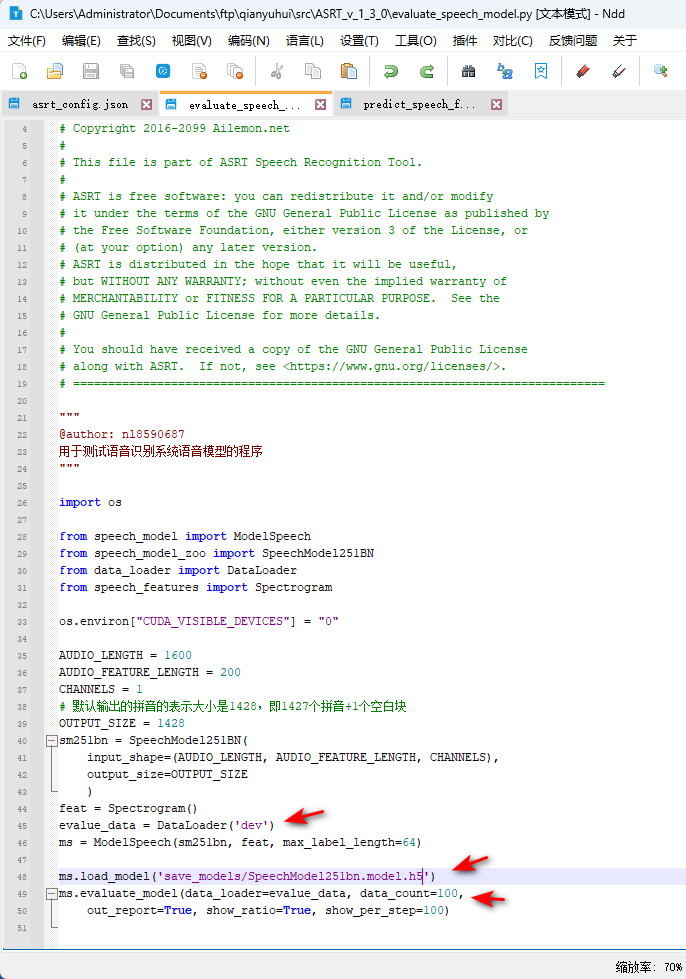
第48行代码:load_model()方法中,需要指定模型参数文件(.h)路径。
第45行代码:test_model() 这里,需要传入的参数为要测试准确率的数据集类型,可选的有训练集(train)、验证集(dev)和测试集(test),图中的【dev】意为:让模型在开发/验证集(dev集)上评估模型的准确率;
第49行代码:data_count参数设定要测试的数据量,例如:100,即随机处连续抽取100个数据进行错误率的计算,如果填“-1”则使用全部测试数据集的数据量,默认为-1;
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
python evaluate_speech_model.py

4.7 语音识别测试
语音识别使用predict_speech_file.py文件:

第47行代码:load_model()方法中,需要指定模型参数文件(.h)路径。
第48行代码:recognize_speech_from_file()函数里面,填写我们需要识别的录音文件的文件名路径。
完毕后,运行代码,查看识别结果。
conda env list
conda activate asrt_env
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
python predict_speech_file.py
5. 常见问题去哪找:
FAQ常见问题答疑