深入CGroup框架--基础篇
CGroup 全称是 Control Group,顾名思义,它是用来做“控制”的。控制什么东西呢?当然是资源的使用了。那它都能控制哪些资源的使用呢?本章主要进行总结,主要涉及到以下方面
- what:什么是cgroup以及cgroup的内核实现
- why: 能解决什么问题
- How: 如何使用cgroup
1. 什么是cgroup
cgroup是Linux下的一种将进程按组进行管理的机制,在用户层看来,cgroup技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个subsystem关联,树的作用是将进程分组,而subsystem的作用就是对这些组进行操作。cgroup主要包括下面几部分:
- 任务(
task):在cgroups中,任务就是系统的一个进程。 - 控制族群(
coontrol group): 就是一组按照某种标准划分的进程。Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。 - subsytem: 就是一个内核模块,他被关联到一颗cgroup树之后,就会在树的每个节点(进程组)上做具体的操作。Linux支持12种subsystem,比如限制CPU的使用时间,限制使用的内存,统计CPU的使用情况,冻结和恢复一组进程等。
- hierarchy: 一个hierarchy可以理解为一棵cgroup树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem关联。
对于其框架如下图所示
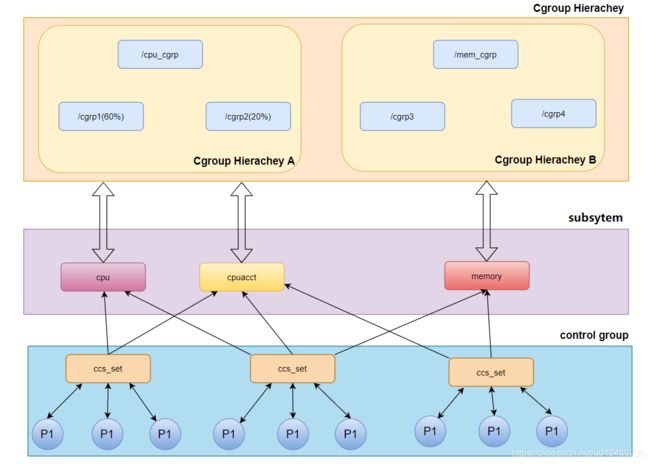
我们把每种资源叫做子系统,比如CPU子系统,内存子系统。为什么叫做子系统呢,因为它是从整个操作系统的资源衍生出来的。然后我们创建一种虚拟的节点,叫做cgroup,然后这个虚拟节点可以扩展,以树形的结构,有root节点,和子节点。这个父节点和各个子节点就形成了层级(hierarchiy)。每个层级都可以附带继承一个或者多个子系统,就意味着,我们把资源按照分割到多个层级系统中,层级系统中的每个节点对这个资源的占比各有不同。
支持的 subsystem 如下( cat /proc/cgroups)
blkio- 可对块设备的输入/输出访问设定限制。cpu- 可以调整控制组群任务的完全公平调度程序(CFS)调度程序的参数。它与cpuacct控制器在相同的挂载中一起挂载。cpuacct- 创建控制组群中任务使用的 CPU 资源自动报告。它与cpu控制器在相同的挂载中一起挂载。cpuset- 可以用来限制控制组任务只在指定的 CPU 子集中运行,并指示任务仅在指定内存节点上使用内存。devices- 可控制控制组群中任务访问设备。freezer- 可以用来挂起或恢复控制组群中的任务。memory- 可以用来设置控制组群中任务使用的内存限值,并生成有关这些任务使用的内存资源的自动报告。net_cls- 使用类标识符(classid)的标签网络数据包可让 Linux 流量控制器(tc命令)识别来自特定控制组群任务的数据包。net_cls的子系统net_filter(iptables),也可以使用此标签对此类数据包执行操作。net_filter标签带有防火墙标识符(fwid),允许 Linux 防火墙(通过iptables命令)识别来自特定控制组群任务的数据包。net_prio- 设置网络流量的优先级。pids- 可为控制组群中的很多进程及其子进程设定限制。perf_event- 可使用perf性能监控和报告工具对任务进行分组。rdma- 可以在控制组群中设置 Remote Direct Memory Access/InfiniBand 特定资源的限制。hugetlb- 可用于根据控制组群中的任务限制大量虚拟内存页面的使用。
按照资源的划分,系统被划分成了不同的子系统(subsystem),正如我们上面列出的cpu, cpuset, blkio…每种资源独立构成一个subsystem.
可以将cgroup的架构抽象的理解为多根的树结构,一个hierarchy代表一棵树,树上绑定一个或多个subsystem.而树的叶子则是cgroup,一个cgroup具体的限制了某种资源。一个或多个cgroup组成一个css_set。简单来讲,就是一个资源限制集合(css_set)对一种subsystem(cpu,devices)的限制条件只能有一个,这是显然的吧…最终的task(进程)同css_set关联,从而达到限制资源的目的
可以通过查看当前系统支持哪些subsystem
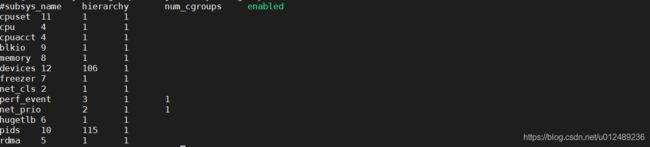
从左到右,字段的含义分别是:
- subsys_name: subsystem的名字
- hierarchy: subsystem所关联到cgroup树的ID,如果多个system关联到同一颗cgroup,那么它们的那个字段将一样。比如这里的cpu和cpuacct就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为0:
- 当前subsystem没有和任何cgroup树绑定
- 当前subsystem已经和cgroup v2的树绑定
- 当前subsystem没有被内核开启
- num_cgroups: subsystem所关联的cgroup树中进程组的个数,也即树上节点的个数
- enabled: 1表示开启,0表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制subsystem的开启)
2. cgroup解决什么
从实现角度来看,cgroups实现了一个通用的进程分组框架,不同资源的具体管理工作由各cgroup子系统来实现,当需要多个限制策略比如同时针对cpu和内存进行限制,则同时关联多个cgroup子系统即可。实现 cgroups 的主要目的是为不同用户层面的资源管理提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化,cgroups 提供了四大功能:
- 资源限制:cgroups 可以对任务是要的资源总额进行限制。比如设定任务运行时使用的内存上限,一旦超出就发 OOM。
- 优先级分配:通过分配的 CPU 时间片数量和磁盘 IO 带宽,实际上就等同于控制了任务运行的优先级。
- 资源统计:cgoups 可以统计系统的资源使用量,比如 CPU 使用时长、内存用量等。这个功能非常适合当前云端产品按使用量计费的方式。
- 任务控制:cgroups 可以对任务执行挂起、恢复等操作。
3. 源码分析
3.1. 数据结构
先从进程的角度,来剖析cgroups相关的数据结构之间的关系
task_struct结构
在 Linux 中,管理进程的数据结构是 task_struct,其中与 cgroups 有关的是如下两个成员:
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
| 成员 | 含义 |
|---|---|
| cgroups | 指向了一个css_set结构,而css_set存储了与进程相关的cgroups信息 |
| cg_list | 将使用同一个css_set的进程链接在一起 |
css_set 结构
struct css_set {
//引用计数,gc使用,如果子系统有引用到这个css_set,则计数+1
atomic_t refcount;
//所有的`css_set`组成一个`hash`表
struct hlist_node hlist;
//将所有的task连起来。mg_tasks代表迁移的任务
struct list_head tasks;
struct list_head mg_tasks;
//将这个css_set对应的cgroup连起来
struct list_head cgrp_links;
//默认连接的cgroup
struct cgroup *dfl_cgrp;
//包含一系列的css(cgroup_subsys_state),css就是子系统,这个就代表了css_set和子系统的多对多的其中一面
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
内存迁移的时候产生的系列数据
struct list_head mg_preload_node;
struct list_head mg_node;
struct cgroup *mg_src_cgrp;
struct cgroup *mg_dst_cgrp;
struct css_set *mg_dst_cset;
struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];
/* all css_task_iters currently walking this cset */
struct list_head task_iters;
/* dead and being drained, ignore for migration */
bool dead;
/* For RCU-protected deletion */
struct rcu_head rcu_head;
}
| 成员 | 含义 |
|---|---|
| refcount | 该css_set的引用计数,因为一个css_set可以被多个进程共用,只要这些进程的cgroups信息相同。比如:在所有已经创建的层级里面都在同一个cgroup里的进程 |
| hlist | 是嵌入的hlist_node,用于把所有的css_set组成一个hash表,这样内核可以快速查找特定的css_set |
| tasks mg_tasks |
tasks是将所有引用此css_set的进程连接成链表, mg_tasks 列出属于这个 cset 但在 * 迁出或迁入的过程 |
| cgrp_links | 指向一个由struct cg_cgroup_link组成的链表 |
| subsys | 是一个指针数组,存储一组指向cgroup_subsys_state的指针。一个cgroup_subsys_state就是进程与一个特定的子系统相关的信息。通过这个指针,进程就可以获得相应的cgroups控制信息了。 |
cgroup_subsys_state
这个结构最重要的就是存储的进程与特定子系统相关的信息。通过它,可以将task_struct和cgroup连接起来了:task_struct->css_set->cgroup_subsys_state->cgroup
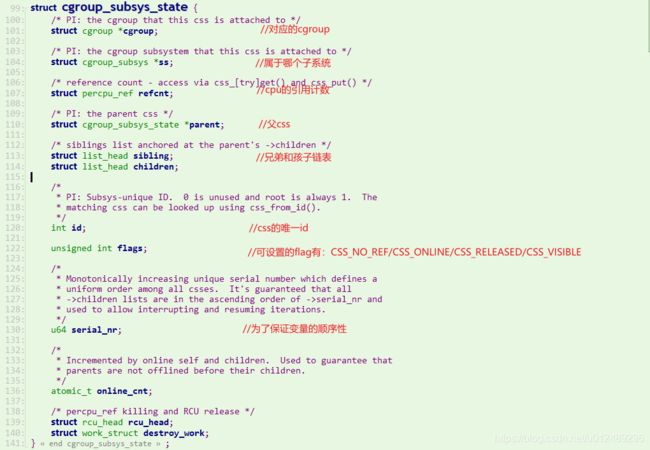
cgroup_subsys


- task_struct: 每个进程的数据结构task_struct,通过css_set可以描述当前进程和哪些cgroup关联,以及关联的子系统有哪些,对于每个进程而言,每个类型的子类型最多关联一个cgroup
- css_set: css_set和一个或几个task相关联,描述一个任务属于哪些cgroup,每个进程中,都对应有一个css_set结构体,css_set其实就是cgroup_subsys_state对象的集合,而每个cgroup_subsys_state代表一个subsystem
- cgrp_links: 用来将 css_set 和 cgroup 做关联
一个进程对应css_set,一个css_set存储了一组进程跟各个子系统相关的信息,但是这些信息有可能不是从一个cgrroup那里获得,因为一个进程可以同时属于几个cgroup,只要这些cgroup不在同一级别
3.2. cgroup的初始化
CGroup需要early_init,start_kernel调用cgroup_init_early在系统启动时进行CGroup初始化,其源码为kernel/cgroup.c,其主要是在系统启动时进行CGroup早期初始化

CGroup的起点是start_kernel->cgroup_init,进入CGroup的初始化,主要注册cgroup文件系统和创建、proc文件,初始化不需要early_init的子系统

procfs 代码可以在 fs/proc/ 子目录中找到。如果您打开 fs/proc/base.c ,您会发现两个非常相似的数组 - tgid_base_stuff 和 tid_base_stuff 。它们都分别为 /proc/PID/ 和 /proc/PID/TID/ 内部的文件注册了文件操作函数
static const struct pid_entry tid_base_stuff[] = {
#ifdef CONFIG_CGROUPS
ONE("cgroup", S_IRUGO, proc_cgroup_show),
#endif
}
3.3 核心框架
在 cgroup_init_early 和 cgroup_init 中,会有下面的循环使用for_each_subsys kernel/cgroup.c 源文件中的一个宏定义,正好扩展成基于 cgroup_subsys 数组的 for 循环。这个数组的定义为
#define for_each_subsys(ss, ssid) \
for ((ssid) = 0; (ssid) < CGROUP_SUBSYS_COUNT && \
(((ss) = cgroup_subsys[ssid]) || true); (ssid)++)
for_each_subsys会循环cgroup_subsys数组cgroup_subsys数组在宏SUBSYS中定义
#define SUBSYS(_x) [_x ## _cgrp_id] = &_x ## _cgrp_subsys,
struct cgroup_subsys *cgroup_subsys[] = {
#include 数组中的项在cgroup_subsys.h中
#if IS_ENABLED(CONFIG_CPUSETS)
SUBSYS(cpuset)
#endif
#if IS_ENABLED(CONFIG_CGROUP_SCHED)
SUBSYS(cpu)
#endif
#if IS_ENABLED(CONFIG_CGROUP_CPUACCT)
SUBSYS(cpuacct)
#endif
#if IS_ENABLED(CONFIG_BLK_CGROUP)
SUBSYS(io)
#endif
当我们把 cpuset、cpu 等参数传给 SUBSYS 宏时,其实是在定义 cpuset_cgrp_subsys、cp_cgrp_subsys。确实如此,在 kernel/cpuset.c 源文件中你可以看到这些结构体的定义:
struct cgroup_subsys cpuset_cgrp_subsys = {
.css_alloc = cpuset_css_alloc,
.css_online = cpuset_css_online,
.css_offline = cpuset_css_offline,
.css_free = cpuset_css_free,
.can_attach = cpuset_can_attach,
.cancel_attach = cpuset_cancel_attach,
.attach = cpuset_attach,
.post_attach = cpuset_post_attach,
.bind = cpuset_bind,
.fork = cpuset_fork,
.legacy_cftypes = files,
.early_init = true,
};
因此,cgroup_init_early 函数中的最后一步是调用 cgroup_init_subsys 函数完成早期子系统的初始化,下面的早期子系统将被初始化:
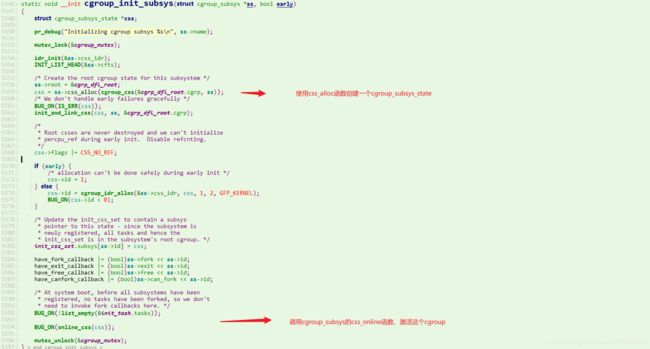
对于 CPU 来讲,css_alloc 函数就是 cpu_cgroup_css_alloc。这里面会调用 sched_create_group 创建一个 struct task_group。在这个结构中,第一项就是 cgroup_subsys_state,也就是说,task_group 是 cgroup_subsys_state 的一个扩展,最终返回的是指向 cgroup_subsys_state 结构的指针,可以通过强制类型转换变为 task_group。

在 task_group 结构中,有一个成员是 sched_entity,前面我们讲进程调度的时候,遇到过它。它是调度的实体,也即这一个 task_group 也是一个调度实体。
接下来,online_css 会被调用。对于 CPU 来讲,online_css 调用的是 cpu_cgroup_css_online。它会调用 sched_online_group->online_fair_sched_group。

在这里,对于每个CPU,取消每个CPU的运行队列rq,也取出 task_group 的 sched_entity,然后通过 attach_entity_cfs_rq 将 sched_entity 添加到运行队列中。
对于内存来讲,css_alloc 函数就是 mem_cgroup_css_alloc。这里面会调用 mem_cgroup_alloc,创建一个 struct mem_cgroup。在这个结构中,第一项就是 cgroup_subsys_state,也就是说,mem_cgroup 是 cgroup_subsys_state 的一个扩展,最终返回的是指向 cgroup_subsys_state 结构的指针,我们可以通过强制类型转换变为 mem_cgroup。
在 cgroup 初始化完毕之后,接下来就是创建一个 cgroup 的文件系统,用了配置和操作 cgroup。cgroup 是一种特殊的文件系统。它的定义如下:

当我们 mount 这个 cgroup 文件系统的时候,会调用 cgroup_mount->cgroup1_mount
3.4 子系统
3.4.1 cpu
对于该子系统,主要是用来调整控制组群任务的完全公平调度程序(CFS)调度程序的参数,那么是如何来调控呢?kernel/sched/core.c定义了cpu_cgrp_subsys结构体,需要进行early_init,核心中已经分析过

这里重点分析一下cpu_files,在实际使用中打开了shares/rt_runtime_us/rt_perios_us,实际的配置中会使用这个

- 其中shares是针对CFS进程的,rt_runtime_us/rt_perios_us是针对RT进程的
- cfs_perios_us/cfs_quota_us是设置CFS进程占用的CPU带宽。
对于Android一个配置,根目录下面对应的是前台应用,bg_non_interactive对应的是后台应用
/dev/cpuctl/cpu.shares 1024
/dev/cpuctl/cpu.rt_runtime_us 950000
/dev/cpuctl/cpu.rt_period_us 1000000
/dev/cpuctl/bg_non_interactive/cpu.shares 52
/dev/cpuctl/bg_non_interactive/cpu.rt_runtime_us 10000
/dev/cpuctl/bg_non_interactive/cpu.rt_period_us 1000000
从上面的数据可以看出,默认分组与bg_non_interactive分组cpu.share值相比接近于20:1。由于Android中只有这两个cgroup,也就是说默认分组中的应用可以利用95%的CPU,而处于bg_non_interactive分组中的应用则只能获得5%的CPU利用率。
- cpu.shares:保存了整数值,用来设置cgroup分组任务获得CPU时间的相对值
举例来说,cgroup A和cgroup B的cpu.share值都是1024,那么cgroup A 与cgroup B中的任务分配到的CPU时间相同,如果cgroup C的cpu.share为512,那么cgroup C中的任务获得的CPU时间是A或B的一半。
- cpu.rt_runtime_us:主要用来设置cgroup获得CPU资源的周期,单位为微妙。
- cpu.rt_period_us:主要是用来设置cgroup中的任务可以最长获得CPU资源的时间,单位为微秒。设定这个值可以访问某个cgroup独占CPU资源。最长的获取CPU资源时间取决于逻辑CPU的数量
比如cpu.rt_runtime_us设置为200000(0.2秒),cpu.rt_period_us设置为1000000(1秒)。在单个逻辑CPU上的获得时间为每秒为0.2秒。 2个逻辑CPU,获得的时间则是0.4秒。
从上面数据可以看出,默认分组中单个逻辑CPU下每一秒内可以获得0.95秒执行时间。bg_non_interactive分组下单个逻辑CPU下每一秒内可以获得0.01秒。
3.4.2 cpuacct
创建控制组群中任务使用的 CPU 资源自动报告,kernel/sched/cpuacct.c中定义cpuacct_cgrp_subsys子系统结构体:

其中legacy_cftypes的files是cpuacct子系统的精髓

要理解每个统计信息的含义就绕不开struct cpuacct这个结构体


3.4.3 cpuset
cpuset提供了一种灵活配置CPU和Memory资源的机制。Linux中已经有配置CPU资源的cpu子系统和Memory资源的memory子系统。kernel/cpuset.c中定义了子系统cpuset结构体如下:

cpuset在Android的应用主要差异就是不同组配置不同的cpus,根据进程类型细分。可以看出优先级越高的进程可以占用的cpu越多。
/dev/cpuset/cpus 0-7
/dev/cpuset/background/cpus 0
/dev/cpuset/foreground/cpus 0-6
/dev/cpuset/system-background/cpus 0-3
/dev/cpuset/top-app/cpus 0-7
只有根节点的mem_exclusive使能,其他都未使能
/dev/cpuset/mem_exclusive 1
/dev/cpuset/background/mem_exclusive 0
/dev/cpuset/foreground/mem_exclusive 0
/dev/cpuset/system-background/mem_exclusive 0
/dev/cpuset/top-app/mem_exclusive 0
3.4.4 devices
主要是用来控制控制组群中任务访问设备,其定义的子系统结构体(security/device_cgroup)为:


3.4.5 hugetlb
可用于根据控制组群中的任务限制大量虚拟内存页面的使用其定义的子系统结构体(mm/hugetlb_cgroup.c)为
![]()
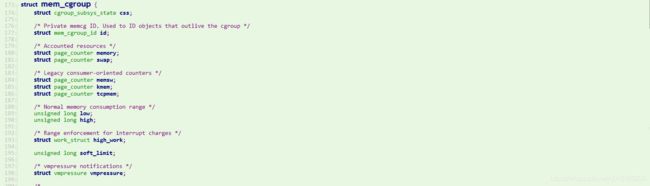
3.4.6 memory
可以用来设置控制组群中任务使用的内存限值,并生成有关这些任务使用的内存资源的自动报告,mm/memcontrol.c中定义了memory子系统memory_cgrp_subsys如下

4. 如何使用
cgroup 机制不只是针对 Linux 内核的需求而创建的,更多的是用户空间层面的需求。要使用 cgroup ,需要先创建它。我们可以通过两种方式来创建。
-
第一种方法是在
/sys/fs/cgroup目录下的任意子系统中创建子目录,并将任务的 pid 添加到tasks文件中,这个文件在我们创建子目录后会自动创建。 -
第二种方法是使用
libcgroup库提供的工具集来创建/销毁/管理cgroups(在 Fedora 中是libcgroup-tools)。
对于具体的使用方法,单独一章进行学习。
5. 总结
内核中 cgroup 的工作机制,其主要过程如下:
- 系统初始化的时候,初始化 cgroup 的各个子系统的操作函数,分配各个子系统的数据结构
- mount cgroup 文件系统,创建文件系统的树形结构,以及操作函数
- 写入 cgroup 文件,设置 cpu 或者 memory 的相关参数,这个时候文件系统的操作函数会调用到 cgroup 子系统的操作函数,从而将参数设置到 cgroup 子系统的数据结构中
- 写入 tasks 文件,将进程交给某个 cgroup 进行管理,因为 tasks 文件也是一个 cgroup 文件,统一会调用文件系统的操作函数进而调用 cgroup 子系统的操作函数,将 cgroup 子系统的数据结构和进程关联起来
- 对于 cpu 来讲,会修改 scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。对于内存的 cgroup 设定,只有在申请内存的时候才起作用
6. 参考文档
cgroup实现方式
趣谈Linux操作系统
Android/Linux下CGroup框架分析及其使用
Android进程线程调度之cgroups
第 1 章 控制群组简介