LSTM原理,参数,实现中文新闻分类代码实现
目录
环境以及第三方库版本
LSTM模型
遗忘门(决定上一时刻的单元状态有多少要保存到当前时刻)
输入门(决定当前网络状态输入有多少需要保存到单元状态)
输出门(控制当前状态单元有多少需要输出到当前输出值)
nn.LSTM()参数介绍
LSTM输入
LSTM输出
LSTM实例
参考
环境以及第三方库版本
- 本人采用的基于pytorch框架下的lstm网络进行讲解。
- 使用的第三方库如图所示。
Name: torch Version: 1.8.0
Name: torchvision Version: 0.9.0
Name: torchtext Version: 0.12.0
Name: jieba Version: 0.42.1
LSTM模型
涉及LSTM,我们一定会讲述到RNN(循环神经网络),LSTM是一个特殊的RNN网络。下面为一个RNN的示例图。RNN会不断循环,而且随着输入数据的增加,会将上一次的状态传递到下一个输入,直到输入结束或者训练结束,最终的输出即为预测结果。但RNN仅保留最近的信息,所以RNN对过去的单元状态关注度不高,提取有用时序信息较少。而且RNN只有短期记忆而没有长期记忆。RNN使用反向传播及时更新权重,容易遭受梯度爆炸的影响,较难收敛。RNN如果使用ReLu激活函数,则会受到死亡ReLu单元的影响。 导致停止学习等问题。
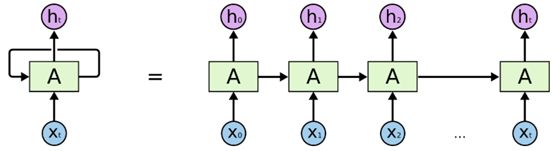
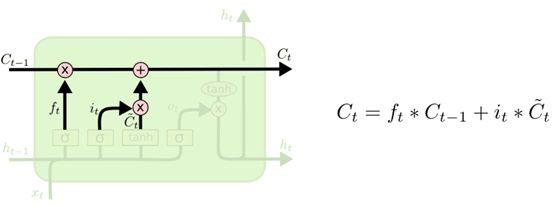
LSTM是RNN模型的一个变体,LSTM单个循环结构有四个状态—— t-1,t时刻的单元状态和t-1,t的输出。相对于RNN更能够保持持久的单元状态从而不受到改变,而且可以自主决定状态和信息需要遗忘或者传递。
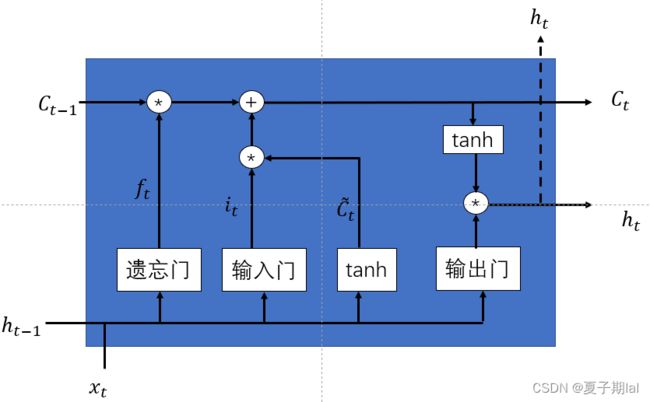
遗忘门(决定上一时刻的单元状态有多少要保存到当前时刻)
输入:上一层的输出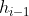 和输入
和输入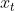
输出:
备注:但在这里不知道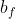 是什么。为遗忘门输出结果,即为根据上一时刻的输出保存的状态信息。后续了解到是偏置权重,当bias=True的时候存在)
是什么。为遗忘门输出结果,即为根据上一时刻的输出保存的状态信息。后续了解到是偏置权重,当bias=True的时候存在)
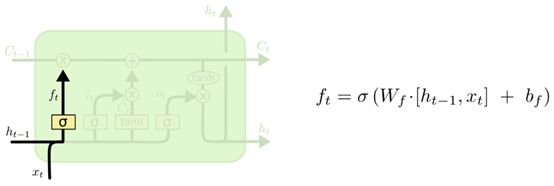
输入门(决定当前网络状态输入有多少需要保存到单元状态)
输入: 上一层的输出和输入
其他的参数![]() 为权重矩阵,
为权重矩阵,![]() 如上同理。
如上同理。
输出:输入通过输入门后保留的信息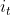 和当前时刻暂存状态的
和当前时刻暂存状态的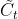

输出门(控制当前状态单元有多少需要输出到当前输出值)
输入:上一个时刻的单元状态![]() ,遗忘门输出,输入门输出,单元状态的输出
,遗忘门输出,输入门输出,单元状态的输出
输出:当前LSTM单元的的状态
nn.LSTM()参数介绍
下文主要介绍的是nn.lstm()输入和输出参数。
class lSTM(Module):
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False)- input_size – 输入数据的大小,每个单词的长度(指定的词向量的维度),或者我们可以理解为输入特征的数量
- hidden_size —— 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数。
- num_layers —— recurrent layer的数量,默认等于1。这里的话是隐藏层的层数。
- bias —— Default: True。偏置如果为True的话,我们就可以用偏置权重bias weights b_ih and b_hh。默认为True。
- batch_first ——默认为False,将batch放在第一维,此时输入输出的各个维度含义为 (seq_length,batch,input_size)。如果batch_first=True,此时为 (batch,seq_length,input_size)
- dropout —— 如果不为0,就在除了最后一层的其它层都插入Dropout层,默认为0。加入dropout层是避免过拟合。
- bidirectional —— 默认为False,即为单向的LSTM传递。否则为双向的LSTM。
LSTM输入
nn.lstm(input, (h_0, c_0))- input —— 输入数据,其维度为(seq_len, batch, input_size) 如果batch_first=True的时候,形状为(batch, seq_len , input_size)
- seq_len: 句子长度,即一个句子的最大长度。一般会包括
和 。这个值同时也就是time_steps,它代表了RNN内部的cell的数量。但是我们在数学建模中这个seq_len约等于运用前面seq_len去预测下一时刻的输出。 - batch:就是你一次传入的句子的数量。
- input_size: 每个单词向量的长度,这个必须和你前面定义的网络结构保持一致,我们这里一般是词嵌入的维度。在数学建模中,input_size一般是特征的个数。
- seq_len: 句子长度,即一个句子的最大长度。一般会包括
备注
比如数据为data = 1,2,3,4,5,6,7,8,9。我们设置seq_len为3,数据变成了[1,2,3][2,3,4][3,4,5]等等依次类推。但是在pytorch中用默认的dataloader的话在__init__(super,self)中默认为1。使用这里我们用Field方法解决。
假如你的一个句子中只有2个单词,但是要求输入10个单词,这个时候可以一般我们使用embedding的层的时候会帮助我们设置好的。如果有其他需求我们则用
torch.nn.utils.rnn.pack_padded_sequence()或者torch.nn.utils.rnn.pack_sequence()来对句子进行填充或者截断。
- h_0 —— 维度形状为 (num_layers * num_directions, batch, hidden_size):
- 结合下图应该比较好理解第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的
bidirectional决定,如果为False,则等于1;反之等于2。 - batch:同上
- hidden_size: 隐藏层节点数
- 结合下图应该比较好理解第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的
- c_0 —— 维度形状为 (num_layers * num_directions, batch, hidden_size),各参数含义和h_0 类似
- 备注:如果不设置h_0和c_0的时候,默认为全都为0。
LSTM输出
Outputs: output, (h_n, c_n)- output: 维度为 (seq_len, batch, num_directions * hidden_size)
- 这个输出tensor包含了LSTM模型最后一层每个time step的输出特征,比如说LSTM有两层,那么最后输出的是第二层LSTM每个time step对应的输出。如果num_layers为只有一层的话,那就是第一层输出结果。
- h_n:(num_layers * num_directions, batch, hidden_size),
- 只会输出最后的time step的隐状态结果。
- Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size) and similarly for c_n.
- c_n :(num_layers * num_directions, batch, hidden_size),只会输出最后time step的cell状态结果。
- 备注:我们一般不需要h_n和c_n,最后一般需要的是output[:,-1,:]的结果,这个意思即为我们获取的是最后的time-step的结果,tensor的形状为(seq_len, num_directions*hidden_size)
LSTM实例
运用的是参考pytorch入门到实践的LSTM中文分类代码。
具体代码在github有源码。欢迎指正和修改。具体可以定位到第七章的7.1.3部分。数据位于data/chap7目录。
关于深度学习pytorch实践的有关代码
参考
长短期记忆神经网络(LSTM)介绍以及简单应用分析
理解Pytorch中LSTM的输入输出参数含义
pytorch官方网站关于lstm参数介绍
Pytorch中如何理解RNN LSTM的input(重点理解seq_len/time_steps) - 知乎