【深度学习】DN-DETR:引入去噪训练以加速收敛
本文来自社区投稿,作者 CW
原文链接:https://zhuanlan.zhihu.com/p/578548914
前言:
本文介绍将为大家介绍一个目标检测模型 —— DN-DETR,其最大亮点是在训练过程中引入了去噪(DeNoising)任务,这也是 DN-DETR 取名之由来。该任务与原始 DETR 的匈牙利匹配过程是相互独立的,相当于是个 shortcut,“绕”过了后者。最终,DN-DETR 在 DAB-DETR 的基础上进一步加速了收敛,对于 COCO 数据集,仅用 12 个 epochs 就可以玩得很漂亮。
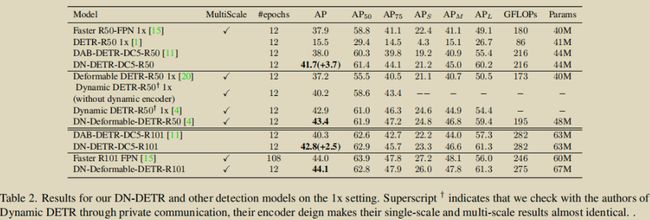
12个 epochs 的性能对比
另外,这个去噪任务仅在训练时需要,而推理时是去掉的,并不会给最终模型的实际应用带来负担。同时,这个任务的引入也不会改变模型结构,能够与 DETR 系列的模型“成为好朋友”(很好地兼容)。
此刻,CW 不由地感叹到去噪大法真是好哇!因为最近自己在 NLP 任务中对 transformer-like models 做稀疏化训练时也加入了去噪的玩法,效果是杠杠滴!另外,近來在内容生成领域大火的 Diffusion Model 也是使用去噪的思想。
来吧!接下来就请各位靓仔靓女们随 CW 来欣赏下 DN-DETR 的演出,SHOW~TIME!
慢收敛的另一凶手:
匈牙利匹配
之前 DAB-DETR 声称找到了 DETR 慢收敛的“罪魁祸首”—— 没有提供位置先验的 learnable queries(in Decoder)。然而,DN-DETR 却犀利地指出,导致 DETR 慢收敛的凶手其实还藏有一个 —— 匈牙利匹配。

“哦?作为 DETR 亮点之一的匈牙利匹配居然是慢收敛的凶手!?”炼丹界的群众们不禁惊呼。
是的,没错!由于匈牙利匹配的离散性和模型训练的随机性,导致了 query 对 gt 的匹配变成了一个动态的、不稳定的过程。我们知道,匈牙利算法是一种全局最优的思想,计算出的 cost 矩阵只要有些许差异,其匹配结果就可能大相径庭。
于是,就同一张图片来说,在不同的训练周期(epoch),同一个 query 通常会匹配到不同的 gt,也就是说它的目标在频繁地切换,特别是在训练的早期。这使得模型的优化有二义性,进而造成优化困难、不稳定,最终的结果就是收敛慢。
进一步理解
Decoder queries 的学习
那么,如何解这个困局呢?作者认为,我们首先得结合当前困局对 decoder queries 的学习有更进一步的理解。
何谓“结合当前困局” & “更进一步”?
根据之前工作的结论:我们已经知道 decoder queries 可以看作是 content + position 两部分的结合,而对于 position 部分的学习,可拆解为是在学习先验位置(anchor point/box) + 偏移量(offset, 包含位置 & 尺度)。
那么,“结合当前困局”即 结合匈牙利匹配的不稳定性 从而形成的“更进一步”的理解就是:匈牙利匹配的不稳定性导致偏移量的学习变得十分困难。
那么为何是导致偏移量的学习变得困难呢?
因为先验位置是“先验”,它是本身就“相对固定”(由于它是可学习的 embedding 向量,因此并非绝对固定)的,它的位置与 gt 有偏差没关系,可以利用偏移量去“弥补”。
从代码实现的角度来看,它是一个全局统计量,学习的是整个数据集 gt 位置的分布规律,单个 query-gt 配对的改变对其并不会造成太大影响(甚至 DAB-DETR 对 transformer 第一层输入的 anchor box 取消了梯度,让初始的 anchor box 均匀分布在图片中,之所以能 match 到目标,主要还是靠学习偏移量去逼近 gt box)。
相反,偏移量是针对单个 query-gt 匹配对而言的,匹配对的频繁切换对于偏移量的学习来说简直是灾难..
你想想,明明在上一个 epoch 说好了 query_a 与 gt_a 匹配,于是基于此学到了对应的偏移量;但是突然“峰回路转”,下一个 epoch 中 query_a 居然跑去和 gt_b 结伴而抛弃了 gt_a,这时候偏移量又得重新大调整,心累呀..
OK,我们已经“结合当前困局”& “更进一步”地理解了 decoder queries 的学习,接下来就该针对偏移量的学习来突破当前困境了!
DeNoising(DN)大法好
we leverage a denoising task as a training shortcut to make relative offset learning easier, as the denoising task bypasses bipartite matching.
如上文所述,作者的破局大招就是去噪大法 —— 在 DETR 训练时引入去噪任务。
以上有两个词 CW 觉得十分精妙!那就是:shortcut & bypass。
前者象征着这是一个加速措施,是一条捷径;后者则简单直接地说明了这招和二分匹配(bipartite matching)不是耦合的,可以“绕”过它,是一条旁路。干净而漂亮,beautiful 是不是!
总的来说,DN 任务就是:
feeds ground-truth bounding boxes with noises into Transformer decoder and trains the model to reconstruct the original boxes
输入是通过对 gt 加噪而获得,输出是为了去重构原来的 gt。
同时,由于所加的噪声都很小,因此模型也比较容易根据这些噪声输入去预测对应的 gt,从而降低了学习的难度。并且,学习的目标很明确,通过哪个 gt 加噪而来的输入,就会负责预测对应的那个 gt,这也避免了匈牙利匹配中存在的二义性现象。

OK,根据以上所述,我们知道,DN 任务的输入可以通过对 gt box 增加一些扰动(比如对 x、y、w、h 4 个分量都加上较小的值)来构造。但是,之前的工作为我们揭示了 decoder query 包含着 content & position 两部分,而现在这样就相当于只对 position 部分进行了加噪。
于是,为了更大程度地激发 DN 大法的威力,作者还同时对 content 部分也进行了加噪,比如将原来的 gt label(类别)替换为其它 label 做为输入,输出则是为了去重构原来的 gt label。
另外,为了兼容之前 DAB-DETR 的架构与流程,DN 任务加噪的 content & position 部分(对应 decoder embeddings & learnable anchors)会分别和匈牙利匹配任务的对应部分拼接(concat)起来,作为 transformer 的输入。
接下来的 4 个小节,CW 会具体地解析 DN 大法的各个关键操作是怎么做的。
noised labes: 对 gt labels 加噪
既然前面刚提到对 content 部分加噪,那么就先拿这部分来“开刀”吧。这部分的思想前面已经提过了,但在具体实现中,我们还需要做一些改造。
由于 gt label 是一个数字,因此当然不能是将这个数字改为另一个数字就完事了。我们可以参考 query 的 position 部分,它是一个 embedding 向量,所以在这里我们也可以把加噪的 label 编码为 embedding 向量。这个做法也类似于 NLP 中常用的 word embedding 套路:根据 1 个整型数值到 embedding 矩阵中去“查表”(look up)从而得到对应的向量。
于是,我们需要在模型中设置一个 embedding matrix,由其来对加噪的 gt label 进行编码得到对应的 class embedding。
另外,考虑到对原始 DETR 的匈牙利匹配任务的友好性,作者还在 class embedding 部分拼接(concat)了指示向量 indicator,用以甄别 query 到底是做去噪任务还是匹配任务。
这么一来,原来做匈牙利匹配任务的那部分 query 的 content 部分也需要改造下,让它的值初始化为 'non-object',这个值应当不小于类别数 num_classes,因为做去噪任务的 query 的 content 部分是由真实的 gt label 而来,其值域会是 [0,num_classes−1] 。当然了,要记得将这个 non-object class 也通过 embedding matrix 去编码,从而得到对应的 embedding 向量。
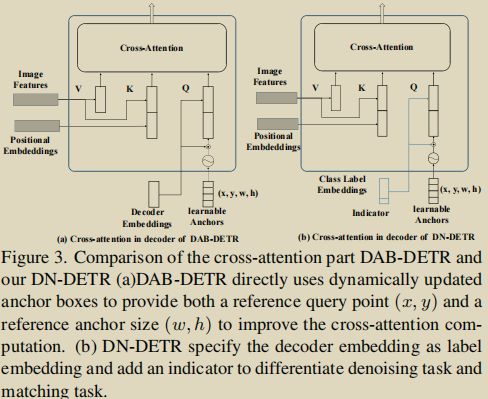
noised boxes:对 gt boxes 加噪
这部分是对 query 的 position 部分加噪。DN-DETR 承袭了 DAB-DETR,position 部分就是 4d anchor box:x、y、w、h (注意,对于以下内容,默认这 4 个分量都归一化到 [0,1] )。自然地,要做的就是对这 4 个分量都加上细微的“扰动”。
总的来说,这部分的加噪可以概括为:中心点位移 & 尺度缩放。
中心点位移
首先从均匀分布中采样1个扰动参数 λ1∈(0,1) ,然后分别计算中心点 x,y 对应的偏移量为 |Δx|=λ1x , |Δy|=λ1y 。由于 x=w2 , y=h2 ,于是扰动后能保证中心点 (x±Δx,y±Δy) 还位于原框内。
尺度缩放
同样地,从均匀分布中采样1个扰动参数 λ2∈(0,1) ,然后也是分别计算宽高 w,h 对应的偏移量 |Δw|=λ2w , |Δh|=λ2h,最终得到缩放后的宽高 (1±λ2)w,(1±λ2)h 。也就是说,宽高会缩放至原来的 0~2 倍。
对于以上两个扰动参数不同值所带来的效果,作者也做了实验进行探索:

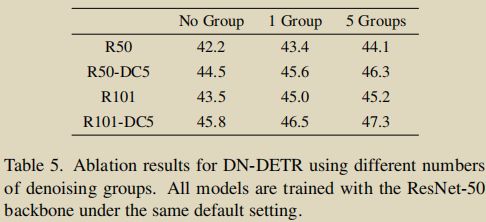
dn groups:
将 one-to-many 范式引入到 DETR 训练中
通过以上内容,我们知道在 DN 任务中,gt -> query 是 one-to-one 的,与 DETR 的匈牙利匹配一样。但是,为了更充分地利用 DN 任务去提升模型的学习效率,我们可以让模型对于每个 gt 在不同程度的噪声下都拥有“纠错”能力,从而使模型更明确 query & gt 的对应关系,也就是更能知道什么样的 query 该负责预测哪个 gt。
基于此,作者设置了 dn groups,即多个去噪组,每个 gt 在每组都会由一个噪声 query(noised label & noised box) 负责去预测。在每组内,gt -> query 依然是 one-to-one 的关系;但综合所有组来看,gt -> query 就是 one-to-many 的关系了。
咦!这套路是不是很熟悉,以往那批老家伙 —— 基于 CNN 的目标检测方法(Faster R-CNN, YOLOv3, RetinaNet, FCOS, etc.)几乎都是这么干的,也就是每个 gt 都由多个样本去负责预测。这种玩法天然地导致了它们都离不开 NMS,因为在推理时对于同一个目标会有多个重叠框。
然而!在这里并不会导致这个现象,DN-DETR 依然可以抛弃 NMS,为什么呢?
CW 在前言里就提到了,DN 大法在模型训练时,没有破坏原来的匈牙利二分匹配 one-to-one 的逻辑,并且在推理时是去掉的,它只是在训练时打辅助 —— 帮助 DETR 更明确 query & gt 的对应关系。于是,在推理时,DN-DETR 输出的依然是基于匈牙利二分匹配的结果。
以下是 dn groups 的效果:
attention mask: 防止作弊
关于 DN 大法本身,CW 基本已经啰嗦完了。但是,前面提到过,DN 任务的噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起喂到 transformer 中的。在 transformer 中,它们会经过 attention 交互(你看看我,我看看你),这样问题就大了!
啊...你还没反应过来!?
噪声 queries 可是通过 gt “稍微”改造而来,那么它们其实是包含着大量 gt 信息的(出生年月日、哪里人、是否单身等等)。于是,如果匈牙利匹配任务的 queries 看到了它们,那就会“偷懒”,导致学习效果大打折扣。
幸亏,一直以来,attention 里都有 mask 这个神器可以防止作弊。因此,在这里我们需要“有针对性”地去设计这个 attention mask。
怎么个有针对性法?
首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
其次,不同 dn group 的 queries 也不能相互看到。为何?因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
接着,同一个 dn group 的 queries 呢?没关系!尽情看吧。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries 吗?Em.. 大方点,看吧!毕竟前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
总的来说,attention mask 的设计归纳为:
匈牙利匹配任务的 queries 不能看到 DN任务的 queries
DN 任务中,不同组的 queries 不能相互看到
其它情况均可见
noised labes, noised boxes & attention mask 做为 DN 大法的“三剑客”,作者对它们的 KPI 完成情况也进行了发布:
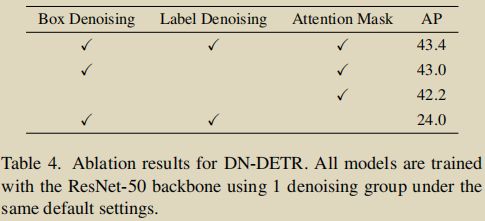
IS(InStability)指标
DN-DETR 吹得头头是道,能够帮助 query & gt 的匹配更稳定、避免二义性等等,那么实际效果究竟如何?怎么去评估?又怎么量化呢?
其实也不难。作者的做法是计算模型的预测结果在相邻 epoch 之间的不一致性,称作 IS 指标。
具体来说,对于一张图片,记第 i 个 epoch 模型解码出来的预测结果 Oi={O0i,O1i,O2i,...,ON−1i},其中 N 代表预测的物体数量。同时记图片中的物体 T={T0,T1,T2,...,TM−1},其中 M 代表图片中的物体数量。
在第 i 个 epoch 的二分匹配结果出来后,就可以计算一个“匹配索引向量” Vi={V0i,V1i,V2i,...,VN−1i} 来表示匹配结果:

于是,IS 指标就是:
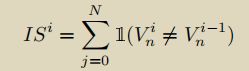
对于以上式子中求和的每项,只有当 Vni≠Vni−1 时才取值 1,否则取值 0。也就是说,每一项都在计算每个预测结果匹配到的真实物体与上一个 epoch 匹配到的是否一致,不一致就计数 1。
基于 IS 指标,DN 大法被评估出来的效果如下:

以上是在整个数据集中对所有图片去平均的统计结果
实验结果:神级辅助的效果
另外,作者在 paper 也提供了一些实验结果用以举证 DN 大法是对于 DETR 是“神级辅助”。
首先来个综合大比拼:
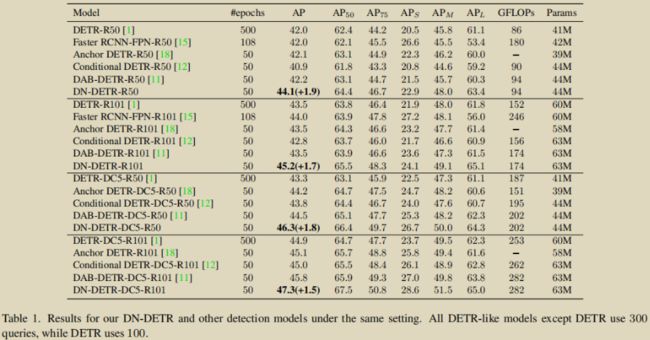
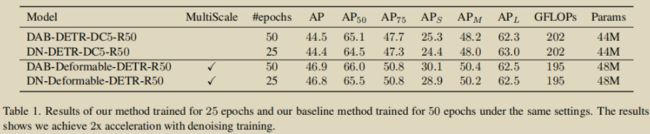
接下来,来个 ResNet-50 backbone 分赛区:
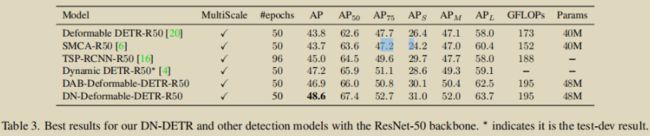
当然,以上有 Deformable DETR 的不少功劳。
作为 DAB-DETR 的优秀后继者,DN-DETR 也不忘“问候”下自己的老大哥:
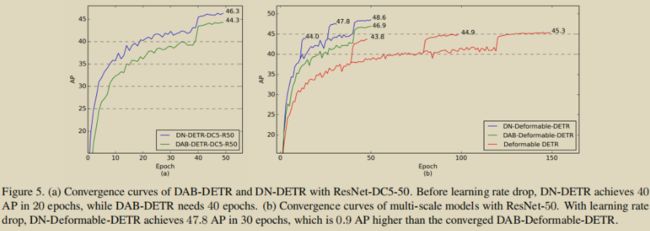
(DAB-DETR: 老弟呀!本是同根生,相煎何太急...)
Re-thinking
对于 DN-DETR 的玩法,CW 就讲到这里。每次在了解完一项工作的方法后,我都会“刷新”一下头脑,重新“审视”下这个工作的方法,比如:能否和自己以往了解过的方法联系起来、这项工作有无不妥或者可以改进的地方、自己的一些想法能否注入到这个方法中去等等。
先讲联系:
很明显,这里把 one-to-one & one-to-many 的学习范式给联系起来了,但最终却保持为 one-to-one 的推理,免去了后处理,着实有趣。另外,这也可以看作是和以往 objection detection 的做法联系在了一起。还有,CW 还嗅出了些许自监督的味道,难免容易联想到掩码(语言 or 图像)模型,毕竟它们的动作实都可看作是“还原”。
再谈不妥 or 改进:
容易发现,这个 one-to-many 的 DN 游戏只有正样本,如果为 gt 分配一些负样本,特别是难以甄别的负样本,让模型学到正负样本之间的边界,那么是否就可能进一步明确 query & gt 的对应关系,从而更有效地辅助匈牙利匹配去消除二义性?
最后谈想法:
CW 从代码实现中发现,DN task 的噪声是从均匀分布采样的,并且是在所有 dn groups 均匀采样,同时也缺乏对每个 dn group 有“针对性”的设置。这里有两个方向可以去探索。首先,如果使用其它分布的噪声会有怎样的效果(其实 paper 中也有提到)?第二,如何对不同的 group 做针对性设置,同时在每个 group 内保持相同的设置。
另外,关于 label denoising 部分,其实喂进去的会有真实标签,甚至大部分都是(根据上面 Figure 6 那张图, λ1 为 0.2 最佳)。
那么,这相当于在一定程度上“绑定了”gt box 周围的 positions(noised boxes)与 真实 class label 的关系,我觉得这也是能够使 query & gt 的匹配关系更确定的原因之一。这么说来,感觉有点作弊.. .
通过 Figure 6 可以发现, λ1 设置为 0.8 的时候效果其实已经很接近不做 label denoising 了(对应 λ1=0)。CW 不免“阴险”地好奇道:λ1=1 会是什么效果呢?(作者为何没有放出对应的实验结果?hhh~)
关于这部分,还有一点,就是 indicator 的设置,CW 在代码实现中也没有发现对它有显式地使用,区分去噪任务的 queries 与匈牙利匹配的 queries 也不需要靠它(在后文源码解析部分你们就可以清楚地看到),paper 中亦没有相关实验去分析它的作用与效果,so, 也只能靠各位去探究了。
核心源码解析
WOW~ 又到了最不无聊的部分了!
由于 DN-DETR 沿用了 DAB-DETR 的代码实现,因此本文只会解析关于去噪(dn)部分的代码,主要包括:
对原始 DETR queries 的改动
如何添加噪声 以及 分配去噪任务的标签
如何在 transformer 输入端兼容去噪任务与匈牙利匹配任务的 queries
如何在 transformer 输出端分离去噪任务与匈牙利匹配任务的输出结果
计算 loss 前需要对去噪任务的输出结果做哪些预处理
去噪任务的 loss(分类 loss & 回归 loss)
CW 再次强调哦,以下每节均是针对去噪任务而言,不涉及原始 DETR 的匈牙利匹配任务。
如果不了解 DAB-DETR 的实现,可以参考下 CW 上一篇文章中的代码解析部分:
https://zhuanlan.zhihu.com/p/560513044
对原始 DETR queries 的改动
以下展示的 prepare_for_dn() 这个方法会在 DN-DETR 的前向过程(forward() 方法)中被调用。
总的来说,这里面做的就是:在训练时,构造去噪任务的 queries(CW 在这里简称为加噪) 以及为它们分配标签,然后将这些噪声 queries 与匈牙利匹配任务的 queries 拼接(concat)起来,最后一并送入到 transformer 中一起玩。
以下部分还未涉及到去噪部分的 queries,为了让去噪任务与匈牙利匹配任务兼容,需要对后者的 queries 也做些改动。主要是将 queries 的 content 部分(以下代码中的 tgt)初始化为 non-object class,并且加入值为 0 的 indicator 向量用作指示这部分 queries 是做匈牙利匹配任务的。
def prepare_for_dn(dn_args, embedweight, batch_size, training, num_queries, num_classes, hidden_dim, label_enc):
"""
prepare for dn components in forward function
Args:
dn_args: (targets, args.scalar, args.label_noise_scale,
args.box_noise_scale, args.num_patterns) from engine input
embedweight: positional queries as anchor
training: whether it is training or inference
num_queries: number of queries
num_classes: number of classes
hidden_dim: transformer hidden dimenstion
label_enc: label encoding embedding
Returns: input_query_label, input_query_bbox, attn_mask, mask_dict
"""
if training:
# targets 是 List[dict],代表1個 batch 的標籤,其中每個 dict 是每張圖的標籤
# scalar 代表的是 dn groups,去噪的組數,默認是 5
targets, scalar, label_noise_scale, box_noise_scale, num_patterns = dn_args
else:
num_patterns = dn_args
if num_patterns == 0:
num_patterns = 1
''' 原始 DETR 匹配任务的 content & position queries '''
# content 部分
# 用於指示匹配(matching)任務的向量
indicator0 = torch.zeros([num_queries * num_patterns, 1]).cuda()
# label_enc 是 nn.Embedding(),其 weight 的 shape 是 (num_classes+1, hidden_dim-1)
# 第一維之所以是 num_classes+1 是因為以下 tgt 的初始化值是 num_classes,因此要求 embedding 矩陣的第一維必須有 num_classes+1;
# 而第二維之所以是 hidden_dim-1 是因為要留一個位置給以上的 indicator0
# 由于去噪任务的 label noise 是在 gt label(0~num_classes-1) 上加噪,
# 因此这里 tgt 的初始化值是 num_classes,代表 non-object,以区去噪任(dn)务和匹配(matching)任务
# (hidden_dim-1,)->(num_queries*num_patterns,hidden_dim-1)
tgt = label_enc(torch.tensor(num_classes).cuda()).repeat(num_queries * num_patterns, 1)
# (num_queries*num_patterns,hidden_dim)
tgt = torch.cat([tgt, indicator0], dim=1)
# position 部分
# (num_queries,4)->(num_query*num_patterns,4)
refpoint_emb = embedweight.repeat(num_patterns, 1)去噪任务的标签
接下来,就真正开始对去噪部分“动手”了,首先是为噪声 queries 分配标签:
''' 训练期间,引入去噪任务相关的部分'''
if training:
''' 计算一些索引,以便后续计算 loss 时用作 query & gt 的匹配 '''
# list 中的每個都是值為 1 shape 為 (num_gt_img,) 的張量
# 注意,每個張量的 shape 不一定一樣,因為每張圖片的 gt 數量不一定一致
known = [(torch.ones_like(t['labels'])).cuda() for t in targets]
# 该 batch 里每张图中各 gt 在圖片中的 index
# torch.nonzero() 返回的是張量中值不為0的元素的索引,list 中的每個張量 shape 是 (num_gt_img,1)
know_idx = [torch.nonzero(t) for t in known]
# 该 batch 中各圖片的 gt 數量
known_num = [sum(k) for k in known]
# 对 gt 在整个 batch 中计算索引
# (num_gts_batch,) 其中每個值都是1
unmask_bbox = unmask_label = torch.cat(known)
# (num_gts_batch,1)
known_indice = torch.nonzero(unmask_label + unmask_bbox)
# (num_gts_batch,)
known_indice = known_indice.view(-1)
# “复制”到所有去噪组
# (num_gts_batch,)->(scalar,num_gts_batch)->(scalar*num_gts_batch)
known_indice = known_indice.repeat(scalar, 1).view(-1)
''' 准备 gt labels & gt boxes '''
# gt labels
# (num_gts_batch,)
labels = torch.cat([t['labels'] for t in targets])
# gt boxes
# (num_gts_batch,4)
boxes = torch.cat([t['boxes'] for t in targets])
# 每張圖片的 batch 索引,這個變量用於代表各圖片是第幾張圖
# (num_gts_batch,)
batch_idx = torch.cat([torch.full_like(t['labels'].long(), i) for i, t in enumerate(targets)])
# 将以上“复制”到所有去噪组
# (num_gts_batch,4)->(scalar*num_gts_batch,4)
known_bboxs = boxes.repeat(scalar, 1)
# (num_gts_batch,)->(scalar*num_gts_batch,)
known_labels = labels.repeat(scalar, 1).view(-1)
# (num_gts_batch,)->(scalar*num_gts_batch,)
known_bid = batch_idx.repeat(scalar, 1).view(-1)
# 用於在 gt labels上加噪
known_labels_expaned = known_labels.clone()
# 用於在 gt boxes 上加噪
known_bbox_expand = known_bboxs.clone()很直观,标签的分配就是将所有 gt(包括 labels & boxes)在 S 个去噪组(dn group)中的每个都 copy 一份,比如1个 batch 中 gt 的数量为 num_gt,那么总的标签数量就是 num_gt x S。
对 gt labels 加噪
标签制作完毕,是时候开始加噪了,先来对 gt labels 加噪(类别“翻转”)。
''' 对 gt labels 加噪 '''
# noise on the label
# label_noise_scale 是用於 gt classes 的噪聲概率,默認是 0.2,即有20%的噪聲比例
if label_noise_scale > 0:
# (scalar*num_gts_batch,) 從均勻分佈中採樣
p = torch.rand_like(known_labels_expaned.float())
# (scalar*num_gts_batch,)
chosen_indice = torch.nonzero(p < (label_noise_scale)).view(-1) # usually half of bbox noise
# paper 中的 'flip' 操作,隨機選擇任意的類別作為噪聲類別
new_label = torch.randint_like(chosen_indice, 0, num_classes) # randomly put a new one here
# 在 dim0 中使用 chosen_indice 作為 index,new_label 作為值
known_labels_expaned.scatter_(0, chosen_indice, new_label)
m = known_labels_expaned.long().to('cuda')
# 加噪後的類別標籤對應的 embedding 向量
# (scalar*num_gts_batch)->(scalar*num_gts_batch,hidden_dim-1)
input_label_embed = label_enc(m)
# 用於指示去噪(dn)任務的向量
# (scalar*num_gts_batch,1)
indicator1 = torch.ones([input_label_embed.shape[0], 1]).cuda()
# 作为去噪任务的 content quries
# add dn part indicator
# (scalar*num_gts_batch,hidden_dim)
input_label_embed = torch.cat([input_label_embed, indicator1], dim=1)逻辑很简单,首先,从均匀分布中采样噪声,使得每个 gt 都有一定机率将其类别“翻转”(替换)为其它类别(根据代码实现,其实翻转后有可能是原类别);然后,计算翻转后的 embedding 向量;最后,加入值为 1 的 indicator 指示向量,用以和匈牙利匹配任务的 quries 作区分。
对 gt boxes 加噪
紧接着,对 gt boxes 加噪(中心位移 & 尺度缩放):
''' 对 gt boxes 加噪 '''
# noise on the box
# box_noise_scale 是用於 gt boxes 的 scale 超參(paper 中的 lambda),默認是 0.4
if box_noise_scale > 0:
# 噪聲偏移量,作用在 gt boxes 上以實現中心點位移以及尺度縮放
# (scalar*num_gts_batch,4)
diff = torch.zeros_like(known_bbox_expand)
# bbox 中心點坐標: w/2,h/2
diff[:, :2] = known_bbox_expand[:, 2:] / 2
# bbox 寬高: w,h
diff[:, 2:] = known_bbox_expand[:, 2:]
# 在原 gt boxes 上加上偏移量,并且保证加噪后框的中心点在原来的框内
# torch.rand_like(known_bbox_expand) * 2 - 1.0 的值域是 [-1,1)
known_bbox_expand += torch.mul((torch.rand_like(known_bbox_expand) * 2 - 1.0), diff).cuda() * box_noise_scale
known_bbox_expand = known_bbox_expand.clamp(min=0.0, max=1.0)
# 原 gt boxes 是 [0,1] 归一化的数值,于是这里进行反归一化
# (scalar*num_gts_batch,4)
input_bbox_embed = inverse_sigmoid(known_bbox_expand)其实就是在 gt boxes(x、y、w、h)加上偏移量,从而实现中心点位移以及尺度缩放,同时还保证了偏移后中心点仍然在原来的框内。
将 batch 中所有图片的
queries 数量“对齐”到一致
在去噪任务中,由于每张图片的 gt 数量不一致,而在每个 dn group 中 query 与 gt 是一对一的,从而导致每张图片的 queries 数量不一致,无法组成 1 个 batch 的 tensor。
因此,我们需要进行 'padding',将每张图片的 queries 数量都 pad 到一致:
''' padding: 使得该 batch 中每張圖都擁有相同數量的 noised labels & noised boxes '''
# 該 batch 中一張圖最多的 gt 數量
single_pad = int(max(known_num))
# 将以上“扩展”到所有去噪组
pad_size = int(single_pad * scalar)
padding_label = torch.zeros(pad_size, hidden_dim).cuda()
padding_bbox = torch.zeros(pad_size, 4).cuda()
''' 將去噪(dn)任務和匹配(matching)任務的 queries 拼接在一起 '''
# (batch_size,pad_size + num_queries*num_patterns,hidden_dim)
input_query_label = torch.cat([padding_label, tgt], dim=0).repeat(batch_size, 1, 1)
# (batch_size,pad_size + num_queries*num_patterns,4)
input_query_bbox = torch.cat([padding_bbox, refpoint_emb], dim=0).repeat(batch_size, 1, 1)
''' 由于以上 input_query_label & input_query_bbox 是 padded 的,
因此要将每张图片真实有效的 noised lables(前面的 input_label_embed) & noised boxes(前面的 input_bbox_embed) 放到正确的位置上 '''
# map in order
map_known_indice = torch.tensor([]).to('cuda')
if len(known_num):
# 将 gt 在其所在圖片中排序,以计算索引
# 以下 List 中每个 tensor 的值域是 [0,num_gt_img-1]
# (num_gts_batch,)
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num])
# 计算出去噪任务中真实有效的(非 padding 的) queries 对应的索引
# 給每個去噪組加上一個對應的 offset,使得不同去噪組的 indices 可區分
# i 的值域是 [0, scalar-1],以上 map_known_indice 的值域是 [0,single_pad-1],
# 因此以下计算出的 map_known_indice 的值域不會超過 pad_size(即 single_pad * scalar)
# (num_gts_batch*scalar,)
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(scalar)]).long()
if len(known_bid):
# 將去噪任务中真实有效的 noised lables & noised boxes “塞”到正确的位置上
# known_pid 和 map_known_indice 的 shape 都是 (scalar*num_gts_batch),一一對應
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed既然涉及到 padding 操作,那么就一定要谨慎地区分开 padding 和 非 padding 的部分,以上关于索引部分(即 map_known_indice 那部分)的计算很是关键,各位客官不妨细品。
attention mask 的设计
attention mask 的设计在 DN-DETR 中很是关键,如果没有这一 part,那模型会成为通过作弊而拿到高分的坏家伙,并不能真正学到东西。
''' 设置 attention mask 以防作弊 '''
# 去噪任务 & 匹配任务 的 queries 总数
tgt_size = pad_size + num_queries * num_patterns
# (i,j) = True 代表 i 不可見 j
attn_mask = torch.ones(tgt_size, tgt_size).to('cuda') < 0
# match query cannot see the reconstruct
# 令匹配任務的 queries 看不到做去噪任務的 queries,因為後者含有真實標籤的信息
attn_mask[pad_size:, :pad_size] = True
# reconstruct cannot see each other
# 对于去噪任务的 queries,只有同组内的相互可见,避免跨组泄露真實標籤的信息,
# 因为每组中,gt 和 query 是 one-to-one 的。
# 于是,在同一组内,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息
for i in range(scalar):
if i == 0:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
if i == scalar - 1:
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
else:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True首先,最重要的是要保证匈牙利匹配任务的 queries 不能看到去噪任务的 queries,因为后者包含了真实标签的信息;其次,对于同是去噪任务的 queries,也要避免跨组泄露信息。
返回兼容去噪任务
与匈牙利匹配任务的处理结果
最后就是将以上处理的结果作为 transformer 的输入,这个结果兼容了去噪任务与匈牙利匹配任务,同时也考虑了训练与推理时的差异。
mask_dict = {
'known_indice': torch.as_tensor(known_indice).long(), # (scalar*num_gts_batch,) 每个 gt 在整个 batch 中的索引
'batch_idx': torch.as_tensor(batch_idx).long(), # (num_gts_batch,) 每个 gt 所在图片的 batch 索引
'map_known_indice': torch.as_tensor(map_known_indice).long(), # (num_gts_batch*scalar,) 噪声 queries(非 padding 的) 的索引
'known_lbs_bboxes': (known_labels, known_bboxs), # (scalar*num_gts_batch,), (scalar*num_gts_batch,4)
'know_idx': know_idx, # List[Tensor]: 其中每個 Tensor 的 shape 是 (num_gt_img,1) 每个 gt 在其图片中的索引
'pad_size': pad_size # 该 batch 中噪声 queries 的数量(包括 padding 的)
}
# 推理时仅有原始 DETR 匹配任务的 queries
else:
# (num_queries*num_patterns,hidden_dim)->(batch_size,num_queries*num_patterns,hidden_dim)
input_query_label = tgt.repeat(batch_size, 1, 1)
# (num_query*num_patterns,4)->(batch_size,num_query*num_patterns,4)
input_query_bbox = refpoint_emb.repeat(batch_size, 1, 1)
attn_mask = None
mask_dict = None
# 將 batch 對應的維度置換到第二維(dim1),以適配 transformer 的輸入
# (num_queries,batch,hidden_dim)
input_query_label = input_query_label.transpose(0, 1)
# (num_queries,batch,4)
input_query_bbox = input_query_bbox.transpose(0, 1)
return input_query_label, input_query_bbox, attn_mask, mask_dict分离去噪任务
与匈牙利匹配任务的输出
由于在 transformer 输入端将去噪任务与匈牙利匹配任务的 queries 拼接到了一起,因此在输出端需要将它们分离,以便计算各自的 loss。
def dn_post_process(outputs_class, outputs_coord, mask_dict):
"""
post process of dn after output from the transformer
put the dn part in the mask_dict
"""
# 分離 去噪(dn)任務 和 原始 DETR 匹配(matching)任務 的預測結果
if mask_dict and mask_dict['pad_size'] > 0:
# 取出去噪任務的預測結果
# (num_layers,batch,pad_size,num_classes)
output_known_class = outputs_class[:, :, :mask_dict['pad_size'], :]
# (num_layers,batch,pad_size,4)
output_known_coord = outputs_coord[:, :, :mask_dict['pad_size'], :]
# 將去噪任務的預測結果記錄到 mask_dict
mask_dict['output_known_lbs_bboxes'] = (output_known_class, output_known_coord)
# 讓 outputs_class & outputs_coord 保持為原始 DETR 匹配任務的預測結果,與原始 DETR 架構兼容
outputs_class = outputs_class[:, :, mask_dict['pad_size']:, :]
outputs_coord = outputs_coord[:, :, mask_dict['pad_size']:, :]
return outputs_class, outputs_coord去噪任务的输出结果被放到 mask_dict 中,而 outputs_class & outputs_coord 保留为匈牙利匹配任务的输出,从而兼容了原模型的架构。
计算 loss 前的预处理
如果你认真地看了前面部分,就知道对于去噪任务的 queries 是做了 padding 的。于是,计算 loss 前我们需要把 padding 部分去掉,仅对真实有效的那些 queries 的输出结果计算 loss。
def prepare_for_loss(mask_dict):
"""
Prepare dn components to calculate loss
Args:
mask_dict: a dict that contains dn information
"""
# (num_layers,batch,pad_size,num_classes), (num_layers,batch,pad_size,4)
output_known_class, output_known_coord = mask_dict['output_known_lbs_bboxes']
# (num_dn_groups*num_gts_batch,), (num_dn_groups*num_gts_batch,4)
known_labels, known_bboxs = mask_dict['known_lbs_bboxes']
# (num_dn_groups*num_gts_batch,) 非 padding 部分的 queries 索引
map_known_indice = mask_dict['map_known_indice']
# (num_dn_groups*num_gts_batch,) 將所有 gt 在 batch 中排序的索引
known_indice = mask_dict['known_indice']
# (num_gts_batch,) 每個 gt 所在圖片的 batch 索引(即是該 batch 中的第幾張圖)
batch_idx = mask_dict['batch_idx']
# (num_dn_groups*num_gts_batch,) 所有去噪組每個 gt/queries 所在圖片的 batch 索引
bid = batch_idx[known_indice]
# 過濾,僅保留非 padding 部分的 queries 對應的預測結果
if len(output_known_class) > 0:
# (num_layers,num_dn_groups*num_gts_batch,num_classes)
output_known_class = output_known_class.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2)
# (num_layers,num_dn_groups*num_gts_batch,4)
output_known_coord = output_known_coord.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2)
num_tgt = known_indice.numel()
return known_labels, known_bboxs, output_known_class, output_known_coord, num_tgt注意,以上返回的输出结果包含了 transformer 所有层的输出,所以最外层维度是 num_layers。
dn loss
准备工作都做完了,现在可以开始计算 loss 了。loss 包含分类和回归两部分,其中分类损失是 Focal loss,回归损失包含 L1 loss 和 GIoU loss。
loss 会对 transformer 每层的输出都计算,整体逻辑封装在以下方法中:
def compute_dn_loss(mask_dict, training, aux_num, focal_alpha):
"""
Compute dn loss in criterion.
Args:
mask_dict: a dict for dn information
training: training or inference flag
aux_num: aux loss number
focal_alpha: for focal loss
"""
losses = {}
# 先計算 transformer 最後一層預測結果對應的 loss
if training and 'output_known_lbs_bboxes' in mask_dict:
# 過濾掉 padding 部分的 queries 的預測結果,使得 gt 與 query 預測結果一一對應
# labels & bboxs: (num_dn_groups*num_gts_batch,), (num_dn_groups*num_gts_batch,4)
# output_class & output_coord: (num_layers,num_dn_groups*num_gts_batch,num_classes), (num_layers,num_dn_groups*num_gts_batch,4)
known_labels, known_bboxs, output_known_class, output_known_coord, num_tgt = prepare_for_loss(mask_dict)
# dn task 的分類損失:focal loss
losses.update(tgt_loss_labels(output_known_class[-1], known_labels, num_tgt, focal_alpha))
losses.update(tgt_loss_boxes(output_known_coord[-1], known_bboxs, num_tgt))
else:
losses['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
losses['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
# 再計算 transformer 除最後一層外其餘每層預測結果對應的 loss
if aux_num:
for i in range(aux_num):
# dn aux loss
if training and 'output_known_lbs_bboxes' in mask_dict:
l_dict = tgt_loss_labels(output_known_class[i], known_labels, num_tgt, focal_alpha)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
l_dict = tgt_loss_boxes(output_known_coord[i], known_bboxs, num_tgt)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses接下来具体看下分类损失和回归损失的实现。
分类损失
def tgt_loss_labels(src_logits_, tgt_labels_, num_tgt, focal_alpha, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
if len(tgt_labels_) == 0:
return {
'tgt_loss_ce': torch.as_tensor(0.).to('cuda'),
'tgt_class_error': torch.as_tensor(0.).to('cuda'),
}
# 增加 batch 維度
# (num_dn_groups*num_gts_batch,num_classes)->(1,num_dn_groups*num_gts_batch,num_classes)
# (num_dn_groups*num_gts_batch,)->(1,num_dn_groups*num_gts_batch)
src_logits, tgt_labels = src_logits_.unsqueeze(0), tgt_labels_.unsqueeze(0)
# 製作 one-hot 類別標籤
# (1,num_dn_groups*num_gts_batch,num_classes+1)
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2] + 1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, tgt_labels.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:, :, :-1]
# 返回的 focal loss 是先在 src_logits.shape[1] 求 mean,然後 sum(),最後除以 num_tgt,
# 這裡乘以 src_logtis.shape[1](等於 num_tgt) 代表這個 loss_ce 是所有類別均攤到每個 query 的損失
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_tgt, alpha=focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'tgt_loss_ce': loss_ce}
# accuracy 計算的是準確率(默認是 top1),以百分比表示
# 這個 tgt_class_error 則表示錯誤率,僅用作 log,不參與梯度計算
losses['tgt_class_error'] = 100 - accuracy(src_logits_, tgt_labels_)[0]
return losses其中,focal loss 的实现如下:
def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
"""
Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
alpha: (optional) Weighting factor in range (0,1) to balance
positive vs negative examples. Default = -1 (no weighting).
gamma: Exponent of the modulating factor (1 - p_t) to
balance easy vs hard examples.
Returns:
Loss tensor
"""
# 將原始 logit 轉換為 0~1 概率
prob = inputs.sigmoid()
# 計算二元交叉熵損失
# (1,num_dn_groups*num_gts_batch,num_classes)
ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
# focal loss 的套路:降低置信度高的樣本(包括正負樣本)的權重,對原始 BCE loss 加權
p_t = prob * targets + (1 - prob) * (1 - targets)
loss = ce_loss * ((1 - p_t) ** gamma)
# 對正負樣本加權
if alpha >= 0:
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
loss = alpha_t * loss
return loss.mean(1).sum() / num_boxes回归损失
def tgt_loss_boxes(src_boxes, tgt_boxes, num_tgt,):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
if len(tgt_boxes) == 0:
return {
'tgt_loss_bbox': torch.as_tensor(0.).to('cuda'),
'tgt_loss_giou': torch.as_tensor(0.).to('cuda'),
}
''' L1 loss '''
# (num_dn_groups*num_gts_batch,4)
loss_bbox = F.l1_loss(src_boxes, tgt_boxes, reduction='none')
# losses = {}
# losses['tgt_loss_bbox'] = loss_bbox.sum() / num_tgt
# 所有回歸量(x,y,w,h)均攤到每個 query 的 loss(這裡的 num_tgt 是 num_dn_groups * num_gts_batch,代表所有去噪組 queries 的總數)
losses = {'tgt_loss_bbox': loss_bbox.sum() / num_tgt}
''' GIoU loss '''
loss_giou = 1 - torch.diag(
# (n_src_boxes,n_tgt_boxes)
box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(tgt_boxes)
)
)
losses['tgt_loss_giou'] = loss_giou.sum() / num_tgt
return losses其实分类和回归损失的实现和 DAB-DETR 的一致,没有太多可说的,比较无聊,只不过在这里为了故事的完整性所以也一并抛出来给大家啰嗦一下,嘻嘻~
源码解析就到此为止咯~ 整体还是很好懂的,没有什么反人类的操作,比较白话文,可能就是开头涉及许多索引的计算看起来比较不友好,我觉得可能主要是变量命名的关系吧。
总结
CW 觉得,DN-DETR 之所以能够加速,一方面是因为去噪任务中 query 与 gt 是确定性关系,而 DETR 的匈牙利匹配是一个动态匹配的过程,每个 query 在不同 epoch 可能会频繁切换对应的目标 gt。同时,这个去噪任务不依赖于 DETR 的匈牙利匹配,相当于接了条“捷径”,让模型知道每个 query 应该“拥抱”哪个 gt。
另一方面,多个 dn groups 的设置,相当于引入了 one-to-many(label->samples)的学习方式,因为每个 gt 在每个 dn group 都会对应到一个样本,所以总的来说每个 gt 都会有多个样本去负责预测。从梯度贡献的角度来看,这会使模型学习得更加充分,而在原始 DETR 中,gt 与 样本仅仅是 one-to-one 的。
近几年看到的许多模型,都让我 feel 到“还原”这种玩法着实强大好使,比如近来自监督里比较热门的 MLM(Masked Language Modeling)& MIM(Masked Image Modeling)。
无论是 去噪(dn)or 掩码(mask)的玩法,本质上都是一种还原的行为。这种还原的玩法也颇有意思:模型在原数据样本上“搞破坏”,然后去预测原来的样本。自己“为难”自己,也不失为一种不无聊的风格。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码