SpringCloud 微服务随机掉线排查过程
一、背景
我们的业务共使用 11 台(阿里云)服务器,使用 SpringcloudAlibaba 构建微服务集群, 共计 60 个微服务, 全部注册在同一个 Nacos 集群。
流量转发路径:nginx -> spring-gateway -> 业务微服务。
使用的版本如下:
-
spring-boot.version:2.2.5.RELEASE
-
spring-cloud.version:Hoxton.SR3
-
spring-cloud-alibaba.version:2.2.1.RELEASE
-
java.version:1.8
二、案发
春节放假期间收到反馈,网页报错服务未找到(gateway 找不到服务的报错提示)。查看 nacos 集群列表,发现个别服务丢失 (下线)。
这个问题每几天出现一次, 出现时间不固定, 每次掉线的服务像是随机选的几个。服务手动 kill+restart 后能稳定运行 2-3 天。
2.1 排查和解决
怀疑对象一:服务器内存爆了
进阿里云控制台查看故障机器近期的各项指标,但是发现故障机器的指标有重要的几项丢失。内存使用率、CPU 使用率、系统负载均不显示。
控制台看不了只好进服务器内查看各指标,free -m 查看内存无异常。提交阿里工单。授权阿里工程师帮忙修复控制台显示问题,怀疑这个问题对业务有影响。
控制台修复后掉线问题依然存在。
怀疑对象二:CPU满载
能感觉到执行命令很流畅,所以感觉不是这个原因。top 查看后很正常。
怀疑对象三:磁盘满了
虽然概率很小,但是 du -sh * 看一下,发现磁盘容量还能用到公司倒闭。
怀疑对象四:网络有问题
-
服务器那三个基本故障暂时排除后,最大怀疑对象就是网络。毕竟服务掉线肯定是服务端一段时间内接收不到客户端心跳包,所以把客户端踢下线了。
-
通过 telnet,mtr -n *.*.*.*,netstat -nat |grep "TIME_WAIT" | wc -l 这些命令也只能看个大概。
-
echo "1" > /proc/sys/net/ipv4/tcp_tw_reuse 修改内核参数,开启 TIME_WAIT socket 复用能力,提升实例的网络发送请求性能。
-
查看 nacos 客户端(微服务)的日志,在前面案发里提到没有日志记录。
怀疑对象五:Nacos 集群服务端故障
-
查看 nacos 集群部署的那几台服务器, 查看服务器基础指标 (内存、CPU、磁盘等),未发现异常 (毕竟还有几十个微服务都很正常工作)。
-
查看 nacos 服务端日志,发现确实有主动下线服务操作。那就奇怪了,这个机器上的有些服务还在正常工作,为什么会随机下线几个服务呢?
怀疑对象六:微服务占用资源太多
后来仔细想想,这个怀疑对象是不是有点离谱了?
因为部署脚本都是同一个,而且负载均衡也是一样的。
但其他机器的这个服务都好好的。
1. 调大每个微服务的内存占用。
2. 添加堆栈打印。
3. 等待一段时间后,异常依然存在,并且没有堆栈打印?因为进程好好的并没退出。
4. google 搜索 nacos 服务掉线,找到一篇看起来极其靠谱的文章。
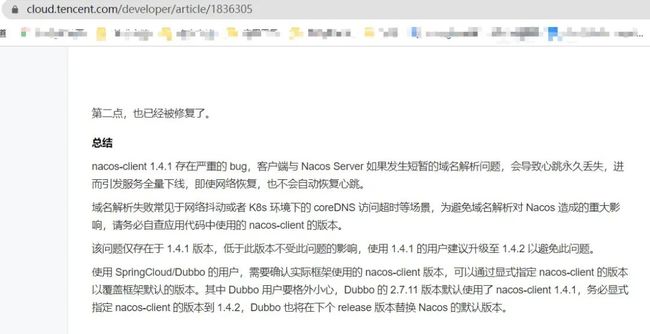
5. 上文提到我使用的 springcloud 版本,恰好这个版本的 nacos-client 版本就是 1.4.1, 于是立马测试升级。

6. 观察几天后,发现问题依旧,只能将探查方向继续转回微服务本身。
7. 用 arthas 进行勘测各项指标,发现所有正常的服务各指标均正常。
8. 想到服务掉线大概率是因为心跳包丢失,怀疑是心跳线程因为某些原因被杀死了。
9. 翻看 nacos-client 源码,找到心跳函数(nacos2.x 不是这个),使用 arthas 监听心跳包,尝试能找到心跳丢失的证据,贴上当时的记录。

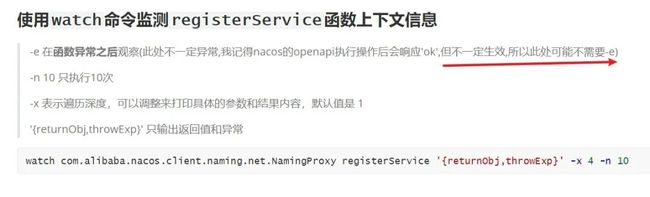
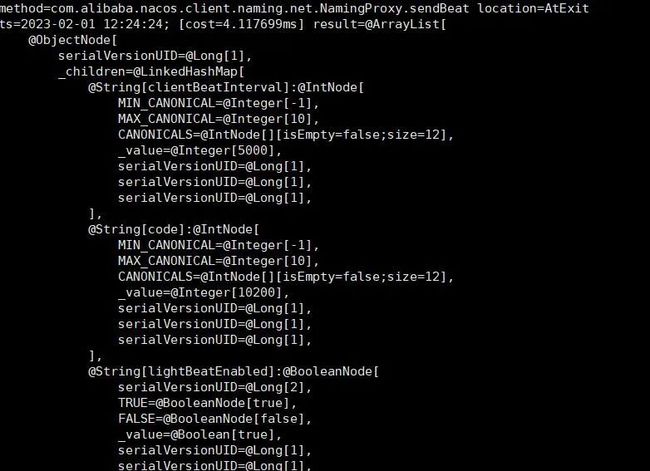
10. 当异常再次发生,arthas 监听卡死,无任何记录和响应。
11. 无奈更换思路,写一个监听服务掉线的程序,期望可以在工作时间内及时获取到异常。
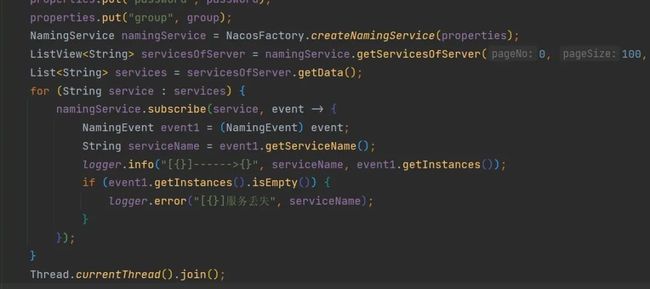
12. 终于在工作时间捕获到异常,第一时间进入服务器内查看情况。
![]()
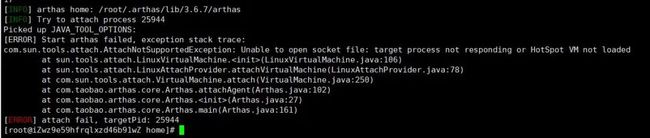
13. 确认服务器基础项没问题后,使用 arthas 查看服务进程堆栈情况,但是 arthas 无法进入进程。
14. 用 jstat 查看 GC 情况,显示很正常。
![]()
15. 用 jmap/jstack 输出堆栈 jstack -l 25944 >heap.txt,但是提示无法进入进程。无奈使用添加 - F(这个参数的堆栈少了很多信息),jstack -F -l 25944 >heap.txt
16. 查看堆栈文件上万行记录,眼都看花了但是没有死锁也没有发现异常。
17. 此时发现监听程序提示服务上线了?检查后发现确实掉线的几个微服务自动恢复了,心想这就难排查了。
18. 尝试复现 Bug,此时离第一次案发已经过去一周多,必须尽快处理好这个 Bug 否则可能得被迫离职了。
19. 当第二次发生异常的时候,使用同样的方式 arthas 无法进入 ->...->jstack 输出堆栈。奇迹发生了,服务又恢复正常了。
20. 思考 / 猜测:因为 JVM 死了(假死),所以导致进程中的一切内容,包括心跳线程、日志等都 hold 住。
21. Google 搜索关键词 JVM 停止(假死)排查,终于找到一个极其靠谱的回答。
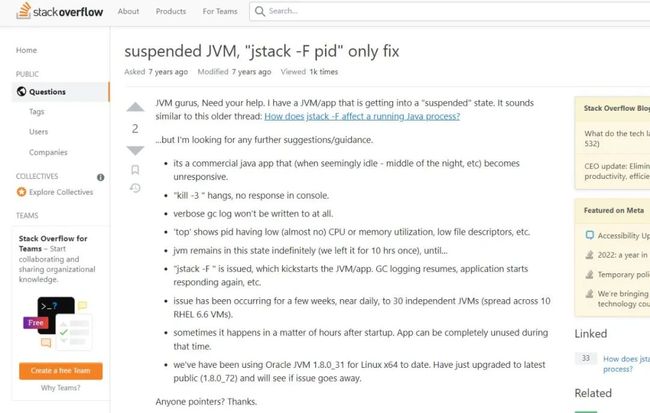
22. 连忙查看对比使用的几个机器内核版本号 uname -r。
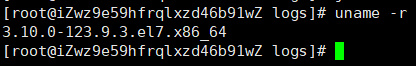

23. 那个低版本的就是故障机器,确认相关信息后,联系阿里云提交工单。
24. 升级完内核并重启机器后,观察两天至今这个问题不存在了。谁能想到这个问题居然是因为 Linux 内核的 Bug 引起的?!不得不佩服第一个发现这个 Bug 的大佬。
完结感言
这个问题折磨了一周多,每日如鲠在喉!调试过程也是苦乐参半,乐的是突然有了调试思路,苦的是思路是一条死胡同,还好最终结果是满意的。
作为一名程序员,还是要时刻保持一颗探索的心,学海无涯!