python最大分词_中文分词--最大正向与逆向匹配算法python实现
最大匹配法:最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。例如:词典中最长词为“中华人民共和国”共7个汉字,则最大匹配起始字数为7个汉字。然后逐字递减,在对应的词典中进行查找。
下面以“我们在野生动物园玩”为例详细说明一下正向与逆向最大匹配方法:
1、正向最大匹配法:
正向即从前往后取词,从7->1,每次减一个字,直到词典命中或剩下1个单字。
第1次:“我们在野生动物”,扫描7字词典,无
第2次:“我们在野生动”,扫描6字词典,无
。。。。
第6次:“我们”,扫描2字词典,有
扫描中止,输出第1个词为“我们”,去除第1个词后开始第2轮扫描,即:
第2轮扫描:
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
。。。。
第6次:“在野”,扫描2字词典,有
扫描中止,输出第2个词为“在野”,去除第2个词后开始第3轮扫描,即:
第3轮扫描:
第1次:“生动物园玩”,扫描5字词典,无
第2次:“生动物园”,扫描4字词典,无
第3次:“生动物”,扫描3字词典,无
第4次:“生动”,扫描2字词典,有
扫描中止,输出第3个词为“生动”,第4轮扫描,即:
第4轮扫描:
第1次:“物园玩”,扫描3字词典,无
第2次:“物园”,扫描2字词典,无
第3次:“物”,扫描1字词典,无
扫描中止,输出第4个词为“物”,非字典词数加1,开始第5轮扫描,即:
第5轮扫描:
第1次:“园玩”,扫描2字词典,无
第2次:“园”,扫描1字词典,有
扫描中止,输出第5个词为“园”,单字字典词数加1,开始第6轮扫描,即:
第6轮扫描:
第1次:“玩”,扫描1字字典词,有
扫描中止,输出第6个词为“玩”,单字字典词数加1,整体扫描结束。
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”
2、正向python代码实现
1 #-*- coding: utf-8 -*-
2 """
3 Created on Thu Jul 19 08:57:56 20184
5 @author: Lenovo6 """
7
8 test_file = 'train/train.txt'#训练语料
9 test_file2 = 'test/test.txt'#测试语料
10 test_file3 = 'test_sc/test_sc_zhengxiang.txt'#生成结果
11
12 def get_dic(test_file): #读取文本返回列表
13 with open(test_file,'r',encoding='utf-8',) as f:14 try:15 file_content =f.read().split()16 finally:17 f.close()18 chars =list(set(file_content))19 returnchars20
21 dic =get_dic(test_file)22 defreadfile(test_file2):23 max_length = 5
24
25 h = open(test_file3,'w',encoding='utf-8',)26 with open(test_file2,'r',encoding='utf-8',) as f:27 lines =f.readlines()28
29 for line in lines:#分别对每行进行正向最大匹配处理
30 max_length = 5
31 my_list =[]32 len_hang =len(line)33 while len_hang>0 :34 tryWord =line[0:max_length]35 while tryWord not indic:36 if len(tryWord)==1:37 break
38 tryWord=tryWord[0:len(tryWord)-1]39 my_list.append(tryWord)40 line =line[len(tryWord):]41 len_hang =len(line)42
43 for t in my_list:#将分词结果写入生成文件
44 if t == '\n':45 h.write('\n')46 else:47 h.write(t + " ")48
49 h.close()50
51 readfile(test_file2)
3、逆向最大匹配算法
逆向即从后往前取词,其他逻辑和正向相同。即:
第1轮扫描:“在野生动物园玩”
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“野生动物园玩”,扫描6字词典,无
。。。。
第7次:“玩”,扫描1字词典,有
扫描中止,输出“玩”,单字字典词加1,开始第2轮扫描
第2轮扫描:“们在野生动物园”
第1次:“们在野生动物园”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
第3次:“野生动物园”,扫描5字词典,有
扫描中止,输出“野生动物园”,开始第3轮扫描
第3轮扫描:“我们在”
第1次:“我们在”,扫描3字词典,无
第2次:“们在”,扫描2字词典,无
第3次:“在”,扫描1字词典,有
扫描中止,输出“在”,单字字典词加1,开始第4轮扫描
第4轮扫描:“我们”
第1次:“我们”,扫描2字词典,有
扫描中止,输出“我们”,整体扫描结束。
逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩
4、逆向python代码实现
1 #-*- coding: utf-8 -*-
2 """
3 Created on Thu Jul 19 08:57:56 20184
5 @author: Lenovo6 """
7 test_file = 'train/train.txt'
8 test_file2 = 'test/test.txt'
9 test_file3 = 'test_sc/test_sc.txt'
10
11 defget_dic(test_file):12 with open(test_file,'r',encoding='utf-8',) as f:13 try:14 file_content =f.read().split()15 finally:16 f.close()17 chars =list(set(file_content))18 returnchars19
20 dic =get_dic(test_file)21 defreadfile(test_file2):22 max_length = 5
23
24 h = open(test_file3,'w',encoding='utf-8',)25 with open(test_file2,'r',encoding='utf-8',) as f:26 lines =f.readlines()27
28 for line inlines:29 my_stack =[]30 len_hang =len(line)31 while len_hang>0 :32 tryWord = line[-max_length:]33 while tryWord not indic:34 if len(tryWord)==1:35 break
36 tryWord=tryWord[1:]37 my_stack.append(tryWord)38 line = line[0:len(line)-len(tryWord)]39 len_hang =len(line)40
41 whilelen(my_stack):42 t =my_stack.pop()43 if t == '\n':44 h.write('\n')45 else:46 h.write(t + " ")47
48 h.close()49
50 readfile(test_file2)
5、正确率,召回率和F值
正确率、召回率和F值是目标的重要评价指标。
正确率 = 正确识别的个体总数 / 识别出的个体总数
召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
编写评价程序:首先对生成的文本和gold文本每行通过切分形成词汇表,然后对两个词汇表从第一个词开始比较:
如果当前词汇相同,表明结果正确,且之前的词汇拼成的字符串长度相等;
如果当前词汇不同,结果错误,不断取词汇拼字符串直到两个字符串长度相同;
依次对每行进行处理,计算出f值。
评价程序实现如下:
1 #-*- coding: utf-8 -*-
2 """
3 Created on Fri Jul 27 15:32:46 20184
5 @author: Lenovo6 """
7
8 test_file = 'test_sc/test_sc_zhengxiang.txt'
9 test_file2 = 'gold/test_gold.txt'
10 defget_word(fname):11
12 f = open(fname,'r',encoding='utf-8',)13 lines =f.readlines()14
15 returnlines16
17
18 defcalc():19 lines_list_sc =get_word(test_file)20 lines_list_gold =get_word(test_file2)21
22 lines_list_num =len(lines_list_gold)23
24 right_num =025 m = 0#m存逆向结果文本词的总数
26 n = 0#n存gold文本词的总数
27
28 for i inrange(lines_list_num):29
30 line_list_sc = list(lines_list_sc[i].split())#line_list_sc为生成结果每行通过空格切分后的词汇表
31 line_list_gold = list(lines_list_gold[i].split())#line_list_gold为正确结果每行通过空格切分后的词汇表
32
33 m +=len(line_list_sc)34 n +=len(line_list_gold)35
36 str_sc = ''#存结果文本每行无空格连接起来的字符串
37 str_gold = ''#存gold文本每行无空格连接起来的字符串
38
39 s = 0#表示结果文本每行列表的下标
40 g = 0#表示gold文本每行列表的下标
41
42 while s < len(line_list_sc) and g
46 str_sc +=str_word_sc47 str_gold +=str_word_gold48
49 if str_word_sc == str_word_gold:#如果当前词汇相同,表明结果正确,且之前的词汇拼成的字符串长度相等
50 s += 1
51 g += 1
52 right_num += 1
53
54 else:#如果当前词汇不同,结果错误,不断取词汇拼字符串直到两个字符串长度相同
55
56 while len(str_sc) >len(str_gold):57 g += 1
58 str_gold +=line_list_gold[g]59
60
61 while len(str_sc)
63 str_sc +=line_list_sc[s]64
65 g += 1
66 s += 1
67
68 print("生成结果词的个数:", m)69 print("gold文本词的个数:", n)70 print("正确词的个数:", right_num)71 p = right_num/m72 r = right_num/n73 f = 2*p*r/(p+r)74 print("正确率:", p)75 print("召回率:", r)76 print("正向f值:", f)77 calc()
运行结果如下:
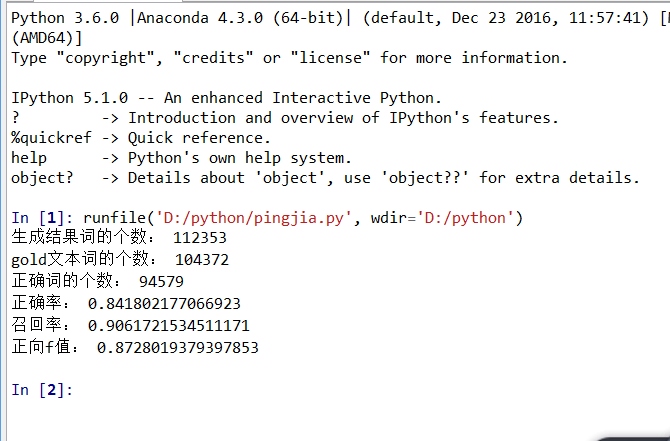
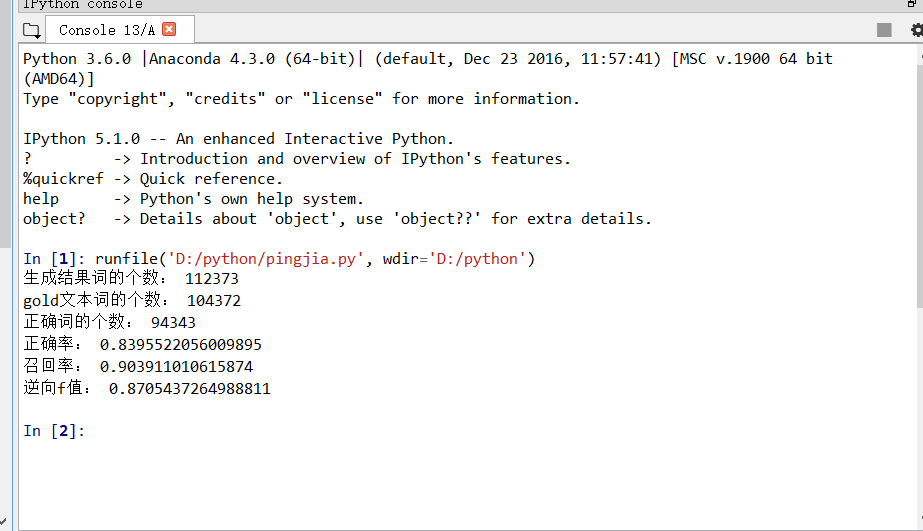
6、训练语料和测试语料见下百度云盘链接
链接: https://pan.baidu.com/s/1X0coEznut6_s0jsDG9_9Dg 密码: b393