torch.nn.Multiheadattention介绍
初始化参数:
class
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True,
add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None, batch_first=False,
device=None, dtype=None)允许模型共同关注来自不同表示子空间的信息。
多头注意力被定义为:
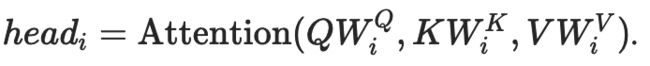
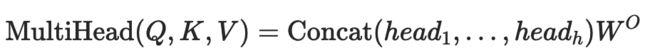
如果满足以下所有条件,forward() 将使用 FlashAttention 中描述的优化实现:
(1)计算自注意力(即查询、键和值是相同的张量。将来会放宽此限制。)
(2)使用 batch_first==True 对输入进行批处理 (3维)
(3)autograd 被禁用(使用 torch.inference_mode 或 torch.no_grad)或没有张量参数 requires_grad
(4)训练被禁用(使用 .eval())
(5)add_bias_kv 为假
(6)add_zero_attn 为假
(7)batch_first 为 True,输入被批处理
(8)kdim 和 vdim 等于 embed_dim
(9)如果传递了 NestedTensor,则既不传递 key_padding_mask 也不传递 attn_mask
(10)autograd被禁用
参数介绍:
embed_dim – 模型的总维度;
num_heads——并行注意力头的数量。请注意,embed_dim 将拆分为 num_heads(即每个头都有维度 embed_dim // num_heads);
dropout——attn_output_weights 上的辍学概率。默认值:0.0(no dropout);
bias – 如果指定,将偏置添加到输入/输出投影层。默认值:真;
add_bias_kv – 如果指定,则在 dim=0 处向键和值序列添加偏差。默认值:假;
add_zero_attn – 如果指定,则将一批新的零添加到 dim=1 处的键和值序列。默认值:假;
kdim – 键的特征总数。默认值:无(使用 kdim=embed_dim)。
vdim – 值的特征总数。默认值:无(使用 vdim=embed_dim)。
batch_first – 如果为 True,则输入和输出张量作为(batch、seq、feature)提供。默认值:False(序列、批次、特征)。
使用案例:
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output, attn_output_weights = multihead_attn(query, key, value)forward函数
forward(query, key, value, key_padding_mask=None, need_weights=True,
attn_mask=None, average_attn_weights=True, is_causal=False)参数解释:
query (Tensor) – 查询嵌入形状(L,Eq)用于非批处理输入,(L,N,Eq)用于batchfirst= False 或(N,L,Eq)用于batchfirst = True,其中 L是目标序列长度,N 是批处理大小,Eq 是嵌入查询的嵌入维度 embed _ dim。将查询与键-值对进行比较以生成输出。
key (Tensor)- 非批量输入的形状(S,Ek)的key嵌入,(S,N,Ek)的键嵌入,batchfirst = False 或(N,S,Ek)的键嵌入,batchfirst = True,其中 S 是源序列长度,N 是批量大小,Ek 是key嵌入维度 kdim。
value (Tensor) – 非批处理输入的形状 (S,Ev) 的value嵌入,(S,N,Ev) 当 batch_first=False 或 (N,S,Ev)当 batch_first=True 时,其中 S 是源序列长度,N是批量大小,Ev 是value嵌入维度 vdim。
key_padding_mask (Optional[Tensor]) – 如果指定,形状为 (N,S) 的掩码指示要忽略key中的哪些元素以引起注意(即视为“填充”)。对于未批量查询,形状应为 (S)。支持二进制和浮点掩码。对于二进制掩码,True 值表示为了引起注意,相应的key值将被忽略。对于float掩码,它会直接添加到相应的key值。
need_weights (bool) – 如果指定,除了 attn_outputs 之外还返回 attn_output_weights。默认值:真。
is_causal (bool) – 如果指定,则应用因果掩码作为注意掩码。与提供 attn_mask 互斥。默认值:假。
average_attn_weights (bool) – 如果为真,则表示返回的 attn_weights 应该在头部之间进行平均。否则,每个头单独提供 attn_weights。请注意,此标志仅在 need_weights=True 时有效。默认值:True(即头部的平均)
输出:
attn _ output-当输入未批处理时形状为(L,E),(L,N,E)(L,N,E)当batchfirst = False 或者(N,L,E)当batchfirst= True 时,形状(L,E)(N,L,E)的注意输出,其中 L是目标序列长度,N是批处理大小,E是嵌入维度 embed _ dim。
attn_output_weights - 仅在 need_weights=True 时返回。如果 average_attn_weights=True,当输入未分批时返回形状为 (L,S),有分批返回(N,L,S)的头部的平均注意力权重,其中 N 是批量大小, L 是目标序列长度,SS 是源序列长度。如果 average_attn_weights=False,当输入未分批或 (N,num_heads,L,S)(N,num_heads,L,S) 时,返回形状为 (num_heads,L,S)(N,num_heads,L,S) 的每个头部的注意力权重。