torch.nn操作
torch操作
- 一、nn.Identity
- 二、nn.SiLU
- 三、nn.MultiheadAttention()
- 四、torch.flatten(input, start_dim=0, end_dim=-1) → Tensor
-
- 4.1 Tensor.flatten(dim=)
- 六、Tensor.unsqueeze(dim=)
- 七、Tensor.squeeze(dim=)
- 八、torch.transpose(input, dim0, dim1) → Tensor
- 九、Tensor.expand()
- 十 数据索引与切片操作
-
- 10.1 索引
-
- 10.1.1 Tensor[:2]
- 10.1.2 a[:2,:1,:,:]
- 10.1.3 a[:2,1:,:,:]
- 10.1.4 a[:2,-3:]
- 10.1.5 a[0:4:2,:,:,0:4:2]
- 10.1.6 a[::2,:,:,::2]
- 10.1.7 ...操作表示自动判断其中得到维度区间,例如[... , 2]
-
- 特殊用法
- 10.1.8 a[..., 1::2, 1::2]
- 10.1.9 torch.cat(tensors, dim=0, *, out=None) → Tensor
- 10.1.10 Focus
- 十一、转置卷积操作
-
- 11.1 转置卷积操作代码
- 11.2 转置卷积与矩阵运算的关系
- 11.3 转置卷积就是一种卷积
- 11.4 当填充为0,步幅为1时
- 11.5 当填充为p,步幅为1时
- 11.6 当填充为p, 步幅为s时
- 11.7 同反卷积的关系
自己记录一些
一、nn.Identity
源码如下:
class Identity(Module):
r"""A placeholder identity operator that is argument-insensitive.
Args:
args: any argument (unused)
kwargs: any keyword argument (unused)
Examples::
>>> m = nn.Identity(54, unused_argument1=0.1, unused_argument2=False)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 20])
"""
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input: Tensor) -> Tensor:
return input
表示:输入的是什么,输出的就是什么tensor不变
二、nn.SiLU
f(x)=x⋅σ(x)

三、nn.MultiheadAttention()
embed_dim=c, num_heads=num_heads
四、torch.flatten(input, start_dim=0, end_dim=-1) → Tensor
参数注释
input (Tensor) – the input tensor.
start_dim (int) – the first dim to flatten
end_dim (int) – the last dim to flatten
>>> t = torch.tensor([[[1, 2],
... [3, 4]],
... [[5, 6],
... [7, 8]]])
>>> torch.flatten(t)
tensor([1, 2, 3, 4, 5, 6, 7, 8])
>>> torch.flatten(t, start_dim=1)
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])
4.1 Tensor.flatten(dim=)
#从dim维开始拉直,前面维度不变
A=torch.arange(80,dtype=torch.float64).reshape(2,2,5,4)
print(A)
print(A.shape)
print(A.flatten(2))
print(A.flatten(2).shape)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]],
[[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.],
[32., 33., 34., 35.],
[36., 37., 38., 39.]]],
[[[40., 41., 42., 43.],
[44., 45., 46., 47.],
[48., 49., 50., 51.],
[52., 53., 54., 55.],
[56., 57., 58., 59.]],
[[60., 61., 62., 63.],
[64., 65., 66., 67.],
[68., 69., 70., 71.],
[72., 73., 74., 75.],
[76., 77., 78., 79.]]]], dtype=torch.float64)
torch.Size([2, 2, 5, 4])
tensor([[[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32., 33.,
34., 35., 36., 37., 38., 39.]],
[[40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52., 53.,
54., 55., 56., 57., 58., 59.],
[60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71., 72., 73.,
74., 75., 76., 77., 78., 79.]]], dtype=torch.float64)
torch.Size([2, 2, 20])
我令dim=1
即
A=torch.arange(80,dtype=torch.float64).reshape(2,2,5,4)
print(A)
print(A.shape)
print(A.flatten(1))
print(A.flatten(1).shape)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]],
[[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.],
[32., 33., 34., 35.],
[36., 37., 38., 39.]]],
[[[40., 41., 42., 43.],
[44., 45., 46., 47.],
[48., 49., 50., 51.],
[52., 53., 54., 55.],
[56., 57., 58., 59.]],
[[60., 61., 62., 63.],
[64., 65., 66., 67.],
[68., 69., 70., 71.],
[72., 73., 74., 75.],
[76., 77., 78., 79.]]]], dtype=torch.float64)
torch.Size([2, 2, 5, 4])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27.,
28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39.],
[40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52., 53.,
54., 55., 56., 57., 58., 59., 60., 61., 62., 63., 64., 65., 66., 67.,
68., 69., 70., 71., 72., 73., 74., 75., 76., 77., 78., 79.]],
dtype=torch.float64)
torch.Size([2, 40])
可以发现从dim= 维之后进行拉平
p = x.flatten(2)
六、Tensor.unsqueeze(dim=)
参考链接: https://blog.csdn.net/HUSTHY/article/details/101649012.
即torch.unsqueeze(input, dim) → Tensor
官方文档注释
Returns a new tensor with a dimension of size one inserted at the specified position.
The returned tensor shares the same underlying data with this tensor.
A dim value within the range [-input.dim() - 1, input.dim() + 1) can be used. Negative dim will correspond to unsqueeze() applied at dim = dim + input.dim() + 1.
Parameters
input (Tensor) – the input tensor.
dim (int) – the index at which to insert the singleton dimension
即在指定位置插入一个维度
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
a=torch.arange(24,dtype=torch.float64).reshape(3,2,4)
print(a.shape)#torch.Size([3, 2, 4])
a=a.unsqueeze(0)
print(a)
print(a.shape)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]],
[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.]]]], dtype=torch.float64)
torch.Size([1, 3, 2, 4])
#在指定dim=x的地方插入一个维度(前插),这种变换相当于加几个括号
a=torch.arange(24,dtype=torch.float64).reshape(3,2,4)
a=a.unsqueeze(0)
print(a.shape)
a=a.unsqueeze(dim=2)
print(a.shape) #(1,3,1,2,4)
torch.Size([1, 3, 2, 4])
torch.Size([1, 3, 1, 2, 4])
最后一维情况:,指定最后其实还没有
a=torch.arange(24,dtype=torch.float64).reshape(3,2,4)
a=a.unsqueeze(dim=3)
torch.Size([3, 2, 4, 1])
七、Tensor.squeeze(dim=)
torch.squeeze(input, dim=None, *, out=None) → Tensor

The returned tensor shares the storage with the input tensor, so changing the contents of one will change the contents of the other.(共享),即改变其中一个,另一个也会被改变
如果不指定维度,就删除所以维度索引个数为1的维度
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0) #在指定的维度0上的个数不是1,所以不压缩,不变
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])
八、torch.transpose(input, dim0, dim1) → Tensor
Returns a tensor that is a transposed version of input. The given dimensions dim0 and dim1 are swapped.
The resulting out tensor shares its underlying storage with the input tensor, so changing the content of one would change the content of the other.(共享内存)
input (Tensor) – the input tensor.
dim0 (int) – the first dimension to be transposed
dim1 (int) – the second dimension to be transposed
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 1.0028, -0.9893, 0.5809],
[-0.1669, 0.7299, 0.4942]])
>>> torch.transpose(x, 0, 1)
tensor([[ 1.0028, -0.1669],
[-0.9893, 0.7299],
[ 0.5809, 0.4942]])
Tensor.transpose(dim0, dim1) → Tensor 同样的道理
九、Tensor.expand()
Returns a new view of the self tensor with singleton dimensions expanded to a larger size.
Passing -1 as the size for a dimension means not changing the size of that dimension.
Tensor can be also expanded to a larger number of dimensions, and the new ones will be appended at the front. For the new dimensions, the size cannot be set to -1.
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
这个函数的作用就是对指定的维度进行数值大小的改变。只能改变维大小为1的维,否则就会报错。不改变的维可以传入-1或者原来的数值。
b=torch.arange(12,dtype=torch.float64).reshape(1,3,4)
print(b.shape)
print(b.expand(4,-1,-1).shape)
torch.Size([1, 3, 4])
torch.Size([4, 3, 4])
十 数据索引与切片操作
参考原文
链接: https://www.cnblogs.com/Yanjy-OnlyOne/p/11553084.html.
参考博客
https://blog.csdn.net/weixin_37552816/article/details/89285235
https://blog.csdn.net/qian_5557/article/details/88649762
https://blog.csdn.net/GodWriter/article/details/93592148
https://blog.csdn.net/GodWriter/article/details/91042157
https://blog.csdn.net/wsLJQian/article/details/113972843
10.1 索引
记住这一句话,数字是在哪个维度上操作的,该维度上的数据表示在该维度上对哪些索引的操作
采用的示例数据是[Batch,C,H,W]的torch.Tensor : [4,3,2,4]
a=torch.arange(96,dtype=torch.float64).reshape(4,3,2,4)
print("===================================")
print(a)
print(a.shape)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]],
[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.]]],
[[[24., 25., 26., 27.],
[28., 29., 30., 31.]],
[[32., 33., 34., 35.],
[36., 37., 38., 39.]],
[[40., 41., 42., 43.],
[44., 45., 46., 47.]]],
[[[48., 49., 50., 51.],
[52., 53., 54., 55.]],
[[56., 57., 58., 59.],
[60., 61., 62., 63.]],
[[64., 65., 66., 67.],
[68., 69., 70., 71.]]],
[[[72., 73., 74., 75.],
[76., 77., 78., 79.]],
[[80., 81., 82., 83.],
[84., 85., 86., 87.]],
[[88., 89., 90., 91.],
[92., 93., 94., 95.]]]], dtype=torch.float64)
torch.Size([4, 3, 2, 4])
10.1.1 Tensor[:2]
实例Tensor一共四个维度,[Batch,C,H,W]的torch.Tensor : [4,3,2,4]:第0,1,2,3维度
这里的结果是取了0~47,torch.Size([2, 3, 2, 4]),表示取出身处第0维度前两个索引(0,1,未到2)(因为[:2]是身处第一维的)
print(a[:2])
#输出
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]],
[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.]]],
[[[24., 25., 26., 27.],
[28., 29., 30., 31.]],
[[32., 33., 34., 35.],
[36., 37., 38., 39.]],
[[40., 41., 42., 43.],
[44., 45., 46., 47.]]]], dtype=torch.float64)
torch.Size([2, 3, 2, 4])
10.1.2 a[:2,:1,:,:]
取出身处第0维的前2索引和第1维的前1索引:
大的两二维是从0~47,再在这两维的每个维度取前一维
print(a[:2,:1,:,:])
print(a[:2,:1,:,:].shape)
#输出
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]]],
[[[24., 25., 26., 27.],
[28., 29., 30., 31.]]]], dtype=torch.float64)
torch.Size([2, 1, 2, 4])
10.1.3 a[:2,1:,:,:]
表示取出身处第0维的前二索引(0,1)和身处第1维的从索引1到最后(索引-1)
大的前两维取出0-47,在这两个维度取出从索引1至最后(索引1和索引2(也就是索引-1))
print(a[:2,1:,:,:])
print(a[:2,1:,:,:].shape)
tensor([[[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.]]],
[[[32., 33., 34., 35.],
[36., 37., 38., 39.]],
[[40., 41., 42., 43.],
[44., 45., 46., 47.]]]], dtype=torch.float64)
torch.Size([2, 2, 2, 4])
10.1.4 a[:2,-3:]
同样在维度0,取得前两个索引;在维度1,取得从索引倒数第三个(就是索引0)至倒数第一个(索引-1,也就是索引2,包括索引2)索引
print(a[:2,-3:])
print(a[:2,-3:].shape)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]],
[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.]]],
[[[24., 25., 26., 27.],
[28., 29., 30., 31.]],
[[32., 33., 34., 35.],
[36., 37., 38., 39.]],
[[40., 41., 42., 43.],
[44., 45., 46., 47.]]]], dtype=torch.float64)
torch.Size([2, 3, 2, 4])
10.1.5 a[0:4:2,:,:,0:4:2]
两个冒号表示在身处某一维度上隔着索引个数取
在维度0隔着索引个数2进行取得(至索引4,但不取索引4),再在取得的位置,维度3(最后一个维度,按照隔着索引个数2进行取得(同样至索引4,但未到索引4))
先取到0和48的所在第0维,再在其中的维度3(就是最后一个维度)进行隔着索引数目2进行取值
print(a[0:4:2,:,:,0:4:2])
print(a[0:4:2,:,:,0:4:2].shape)
tensor([[[[ 0., 2.],
[ 4., 6.]],
[[ 8., 10.],
[12., 14.]],
[[16., 18.],
[20., 22.]]],
[[[48., 50.],
[52., 54.]],
[[56., 58.],
[60., 62.]],
[[64., 66.],
[68., 70.]]]], dtype=torch.float64)
torch.Size([2, 3, 2, 2])
10.1.6 a[::2,:,:,::2]
两个冒号直接写表示从所有的数据中隔行取数据(在身处所属维度对该维度所有数据进行隔行取数据)
以下结果发现跟1.5的结果类似。
print(a[::2,:,:,::2])
print(a[::2,:,:,::2].shape)
tensor([[[[ 0., 2.],
[ 4., 6.]],
[[ 8., 10.],
[12., 14.]],
[[16., 18.],
[20., 22.]]],
[[[48., 50.],
[52., 54.]],
[[56., 58.],
[60., 62.]],
[[64., 66.],
[68., 70.]]]], dtype=torch.float64)
torch.Size([2, 3, 2, 2])
10.1.7 …操作表示自动判断其中得到维度区间,例如[… , 2]
总结
起始 , … , 最后:没有起始就是在最后一个维度取索引值,没有最后就取出第0维的索引值
b=torch.rand(4,3,28,28)
print(b[...,2].shape)
print(b[0,...,::2].shape)
print(b[...].shape)
torch.Size([4, 3, 28])#最后一个维度的索引2
torch.Size([3, 28, 14])#取出第0维,最后一个维度按照索引个数2隔着取
torch.Size([4, 3, 28, 28])
仍然a=torch.arange(96,dtype=torch.float64).reshape(4,3,2,4)
以下取出的是在最后一个维度(维度3)的所有索引2的数据
print(a[...,2])
print(a[...,2].shape)
tensor([[[ 2., 6.],
[10., 14.],
[18., 22.]],
[[26., 30.],
[34., 38.],
[42., 46.]],
[[50., 54.],
[58., 62.],
[66., 70.]],
[[74., 78.],
[82., 86.],
[90., 94.]]], dtype=torch.float64)
torch.Size([4, 3, 2])
#下面是#取出第0维,最后一个维度按照索引个数2隔着取
print(a[0,...,::2])
print(a[0,...,::2].shape)
tensor([[[ 0., 2.],
[ 4., 6.]],
[[ 8., 10.],
[12., 14.]],
[[16., 18.],
[20., 22.]]], dtype=torch.float64)
torch.Size([3, 2, 2])
特殊用法
下面的0是显然处在倒数第2维,所以是其余维度正常保持,取出该指定维度(倒数第2维)的所有索引0的数据,
当指定的是某一个维度的唯一索引的数据,取出来的数据就产生了降维
仍然a=torch.arange(96,dtype=torch.float64).reshape(4,3,2,4)
print(a[...,0,:])
print(a[...,0,:].shape)
b=torch.rand(5,4,3,28,64)
print(b[...,2].shape)
print(b[0,...,::2].shape)
print(b[...,0,:].shape)
tensor([[[ 0., 1., 2., 3.],
[ 8., 9., 10., 11.],
[16., 17., 18., 19.]],
[[24., 25., 26., 27.],
[32., 33., 34., 35.],
[40., 41., 42., 43.]],
[[48., 49., 50., 51.],
[56., 57., 58., 59.],
[64., 65., 66., 67.]],
[[72., 73., 74., 75.],
[80., 81., 82., 83.],
[88., 89., 90., 91.]]], dtype=torch.float64)
torch.Size([4, 3, 4])
#---------------------------------
torch.Size([5, 4, 3, 28])
torch.Size([4, 3, 28, 32])
torch.Size([5, 4, 3, 64])
10.1.8 a[…, 1::2, 1::2]
a=torch.arange(96,dtype=torch.float64).reshape(4,3,2,4)
print("=====================================================")
print(a)
print(a.shape)
print(a[..., 1::2, 1::2])
print(a[..., 1::2, 1::2].shape)
#只显示
#print(a[..., 1::2, 1::2])
#print(a[..., 1::2, 1::2].shape)
tensor([[[[ 5., 7.]],
[[13., 15.]],
[[21., 23.]]],
[[[29., 31.]],
[[37., 39.]],
[[45., 47.]]],
[[[53., 55.]],
[[61., 63.]],
[[69., 71.]]],
[[[77., 79.]],
[[85., 87.]],
[[93., 95.]]]], dtype=torch.float64)
torch.Size([4, 3, 1, 2])
#上述说明是在宽高维度进行取索引(都是从索引1开始,隔行(列)取数据)
#由于第2维的维度总数(索引数是2)所以就取了1个索引,第3维(是 W 维),从索引1隔着两行取
x::y------>前一个x是起始索引值,后一个y是索引间隔
b=torch.rand(5,4,3,48,64)
print(b.shape)
print(b[...,2::3,1::4].shape)
print(b)
print(b[...,2::3,1::4])
torch.Size([5, 4, 3, 48, 64])
torch.Size([5, 4, 3, 16, 16])
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]], dtype=torch.float64)
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]], dtype=torch.float64)
10.1.9 torch.cat(tensors, dim=0, *, out=None) → Tensor
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,
-1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,
-0.5790, 0.1497]])
(x,x,x) 和 [x,x,x] 是一个意思
x=torch.arange(6,dtype=torch.float64).reshape(2,3)
print(x)
print(x.shape)
print(torch.cat([x,x,x,],dim=0))
print(torch.cat([x,x,x,],dim=0).shape)
#输出
tensor([[0., 1., 2.],
[3., 4., 5.]], dtype=torch.float64)
torch.Size([2, 3])
tensor([[0., 1., 2.],
[3., 4., 5.],
[0., 1., 2.],
[3., 4., 5.],
[0., 1., 2.],
[3., 4., 5.]], dtype=torch.float64)
torch.Size([6, 3])
10.1.10 Focus
class Focus(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
patch_top_left = x[..., ::2, ::2]
patch_bot_left = x[..., 1::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat((patch_top_left, patch_bot_left, patch_top_right, patch_bot_right,), dim=1,)
return self.conv(x)
测试运行:
import torch
import torch.nn as nn
class Focus(nn.Module):
def __init__(self, ksize=1, stride=1, act="silu"):
super().__init__()
# self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
patch_top_left = x[..., ::2, ::2]
patch_bot_left = x[..., 1::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat((patch_top_left, patch_bot_left, patch_top_right, patch_bot_right,), dim=1,)
return x
# return self.conv(x)
a=torch.arange(96,dtype=torch.float64).reshape(2,3,4,4)
print(a)
f=Focus()
b=f(a)
print(b)
测试结果:
# a输出
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.]],
[[32., 33., 34., 35.],
[36., 37., 38., 39.],
[40., 41., 42., 43.],
[44., 45., 46., 47.]]],
[[[48., 49., 50., 51.],
[52., 53., 54., 55.],
[56., 57., 58., 59.],
[60., 61., 62., 63.]],
[[64., 65., 66., 67.],
[68., 69., 70., 71.],
[72., 73., 74., 75.],
[76., 77., 78., 79.]],
[[80., 81., 82., 83.],
[84., 85., 86., 87.],
[88., 89., 90., 91.],
[92., 93., 94., 95.]]]], dtype=torch.float64)
# b输出
tensor([[[[ 0., 2.],
[ 8., 10.]],
[[16., 18.],
[24., 26.]],
[[32., 34.],
[40., 42.]],
[[ 4., 6.],
[12., 14.]],
[[20., 22.],
[28., 30.]],
[[36., 38.],
[44., 46.]],
[[ 1., 3.],
[ 9., 11.]],
[[17., 19.],
[25., 27.]],
[[33., 35.],
[41., 43.]],
[[ 5., 7.],
[13., 15.]],
[[21., 23.],
[29., 31.]],
[[37., 39.],
[45., 47.]]],
[[[48., 50.],
[56., 58.]],
[[64., 66.],
[72., 74.]],
[[80., 82.],
[88., 90.]],
[[52., 54.],
[60., 62.]],
[[68., 70.],
[76., 78.]],
[[84., 86.],
[92., 94.]],
[[49., 51.],
[57., 59.]],
[[65., 67.],
[73., 75.]],
[[81., 83.],
[89., 91.]],
[[53., 55.],
[61., 63.]],
[[69., 71.],
[77., 79.]],
[[85., 87.],
[93., 95.]]]], dtype=torch.float64)
:: ----->前面的不写,就默认的是从0开始
十一、转置卷积操作
https://courses.d2l.ai/zh-v2/

11.1 转置卷积操作代码
import torch
from torch import nn
from d2l import torch as d2l
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1)) #转置卷积操作,这是设置输出大小
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i:i + h, j:j + w] += X[i, j] * K #元素级乘法,但先不求和
return Y
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(trans_conv(X, K))
'''
输出:
tensor([[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]])
'''
#高级API实现
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
#批量大小,通道数,Height, Width
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
print(tconv(X))
'''
输出:
tensor([[[[ 0., 0., 1.],
[ 0., 4., 6.],
[ 4., 12., 9.]]]], grad_fn=)
'''
#填充、步幅和多通道
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv.weight.data = K
print(tconv(X))
'''
#输出:
tensor([[[[4.]]]], grad_fn=)
'''
#转置卷积步幅增大的情况
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
tconv.weight.data = K
print(tconv(X))
'''
输出
tensor([[[[0., 0., 0., 1.],
[0., 0., 2., 3.],
[0., 2., 0., 3.],
[4., 6., 6., 9.]]]], grad_fn=)
'''
# 多通道
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
print(tconv(conv(X)).shape == X.shape)
'''
输出
True
'''
11.2 转置卷积与矩阵运算的关系
X = torch.arange(9.0).reshape(3, 3)
K = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
Y = d2l.corr2d(X, K)
print(Y)
'''
输出:
tensor([[27., 37.],
[57., 67.]])
'''
def kernel2matrix(K):
k, W = torch.zeros(5), torch.zeros((4, 9))
k[:2], k[3:5] = K[0, :], K[1, :]
W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k
return W
W = kernel2matrix(K)
print(W)
'''
输出:
tensor([[1., 2., 0., 3., 4., 0., 0., 0., 0.],
[0., 1., 2., 0., 3., 4., 0., 0., 0.],
[0., 0., 0., 1., 2., 0., 3., 4., 0.],
[0., 0., 0., 0., 1., 2., 0., 3., 4.]])
'''
矩阵乘法:
Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)
'''
#输出
tensor([[True, True],
[True, True]])
'''
Z == trans_conv(Y, K)
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3)
'''
输出:
tensor([[True, True, True],
[True, True, True],
[True, True, True]])
'''
11.3 转置卷积就是一种卷积
在形状上是逆变换

11.4 当填充为0,步幅为1时

11.5 当填充为p,步幅为1时

11.6 当填充为p, 步幅为s时
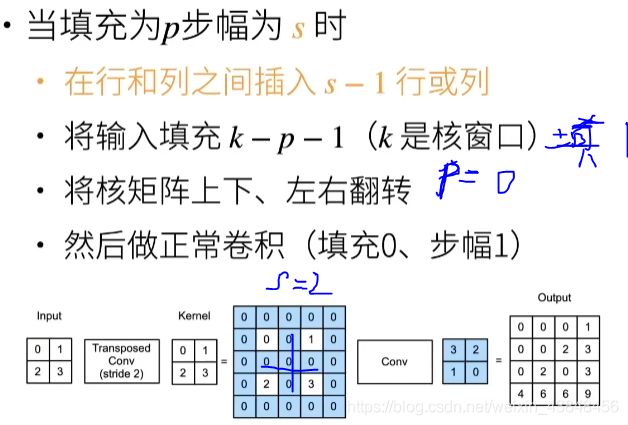

11.7 同反卷积的关系
数学上的反卷积(deconvolution)是指卷积的逆运算
如果
Y = c o n v ( X , K ) , 那 么 X = d e c o n v ( Y , K ) Y=conv(X,K),那么 X=deconv(Y,K) Y=conv(X,K),那么X=deconv(Y,K)
反卷积很少用在深度学习中,
通常所说的反卷积神经网络指用了转置卷积的神经网络