信息收集之WAF绕过
信息收集之WAF绕过
- 前言
- 一、工具进行目录扫描
-
-
- 1. 工具的下载
- 2. 工具的使用
-
- 二、Python代码进行目录扫描
前言
对于web安全无WAF的信息收集,大家可以查看如下链接的文章:
web安全之信息收集
对于有WAF信息收集,看如下所示:(
WAF一般只能够阻断我们的扫描,不能够阻断我们的资产收集)
一、工具进行目录扫描
1. 工具的下载
工具进行目录扫描,我推荐使用WebPathBrute,这款扫描工具可以对扫描的值进行一些更改。WebPathBrute下载地址
2. 工具的使用
如下图是工具的整体界面
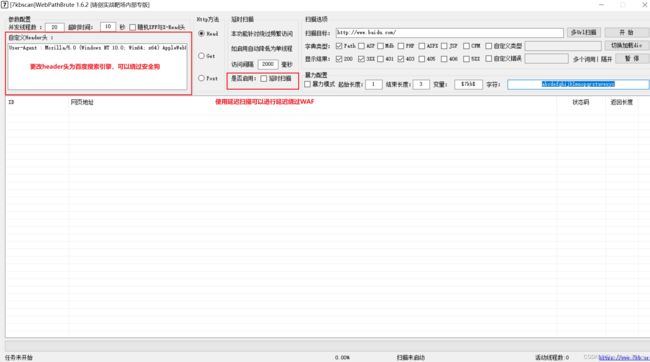
- http访问方法 HEAD GET POST 三种方式,head请求扫描速度最快 但是准确率不如以下两种,post请求是为某些情况绕过waf使用的。
- 延时扫描功能 勾选效果是: 单线程扫描、默认每隔2秒访问一次。适用于某些存在CCwaf的网站 免于频繁访问被认为是CC攻击。(默认两秒已经能过云锁以及安全狗的默认CC设置)
- 扫描类型 分别对应同目录下多个txt文件 自定义对应的文件是custom.txt,后缀格式为".xxx",如不需要后缀可以不填 直接将字典内容修改为"111.svn"此类即可。
- 双击表格内某行即调用系统默认浏览器打开当前行Url 右键可复制Url内容。
- 批量导入的Url与填写的Url都需要以 http:// https:// 开头的格式。
二、Python代码进行目录扫描
如下就是代码:
import time
import requests
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'PHPSESSID=fd9fe23725ee345977c7bc5197297969; safedog-flow-item=3F12D5FCE8EE42D19C69ADB5A7C5BDDB',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)' # 百度搜索引擎就可以绕过安全狗
}
for paths in open('dict.txt', encoding='utf-8'): # dict.txt为字典目录
url = "http://192.168.93.134/pikachu/" # 要扫描的URL地址
paths = paths.replace('\n', '') # 把末尾的换行去掉
urls = url + paths
# proxy = {
# 'http': '127.0.0.1:7777'
# } # 代理池绕过 绕过宝塔
try:
code = requests.get(urls, headers=headers).status_code
# time.sleep(3) # 延迟绕过 ,可以绕过安全狗,宝塔,阿里云
print(urls + '|' + str(code))
except Exception as err:
print('connect error')