数据库+chatGPT3.5 优化、索引、注释、写SQL就是一句话的事了
引言
3月份chatGPT是不安分的、微软是不安分的、那么勇哥就应该安分?不可能,绝对不可能。简单来说,勇哥3月份成功的把chatGPT3.5集成到bg-tinkle软件中发布了v1.0.5版本。集成后的bg-tinkle对于数据库的修改、统计、删除等操作就都是一句话的事了,非常NICE。
阅读本文你会了解3月份chatGPT重大的事件,体验如何使用AI帮助数据库优化、设计SQL等操作?以及了解本功能开发实现的思路?
事件回顾:不安分的3月大事
chatGPT竞品出现:(谷歌的)Bard、(百度的)文心一言
chatGPT发布新版:chatGPT4隆重发布(但是勇哥并不CARE,因为太贵和没资格)
chatGPT成品出现:微软office正式接入chatGPT,写好word、ppt、excel再也不用报班学习了(但是价格不便宜呀~)
数据库+AI:功能体验
AI功能是以聊天的方式进行,然后对聊天的结果可直接执行SQL、制作图表得操作。
通过数据库软件,直接获取数据库表结构,然后再此基础上可用让AI帮您设计统计分析、修改、优化等,并直接生成SQL语句。然后可在结果中一键执行SQL、或者生成SQL的统计图。
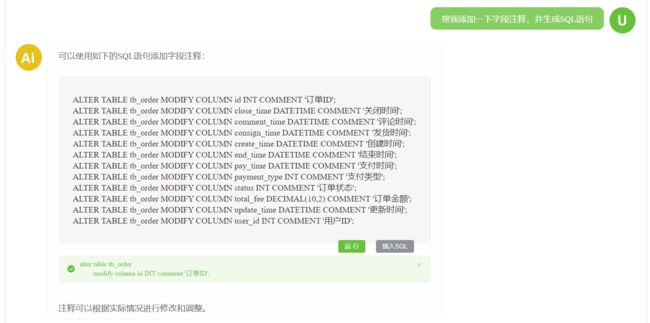
AI补全表注释
忘记写注释也不用怕,一键让AI补充+一键运行,10秒不到完成工作!大赞~
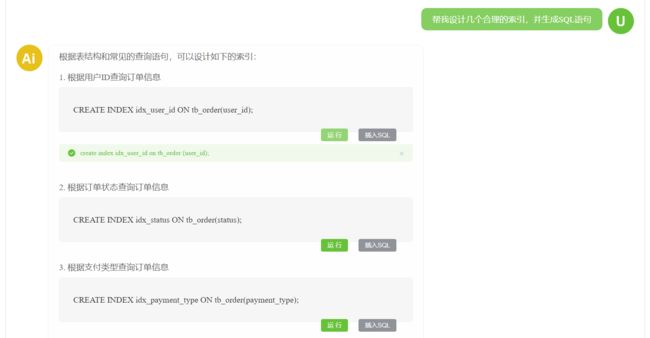
AI设计表索引
可以发送表常用的SQL语句,然后让其设计合理的索引。其设计的索引还挺符合行业规范的。大赞~
AI创建新表
依据现有的数据库,参考设计一张新的表。分成多次会话沟通,依然没有问题。

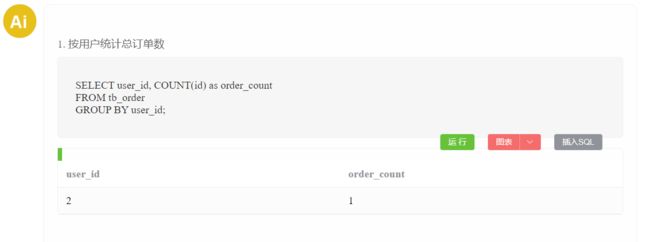
AI结果直接运行
AI结果中的查询SQL会自动执行,并以表格的方式展示结果。同时相关SQL如果有问题,还支持编辑后执行。
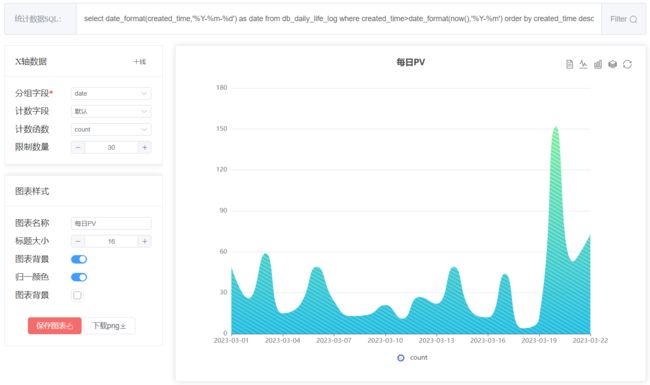
AI结果做成图表
AI生成的SQL语句,可以直接转到图表生成功能中,快速正常折线图、饼图、柱状图、树图、桑基图等。
数据库+AI:使用帮助-开启对话
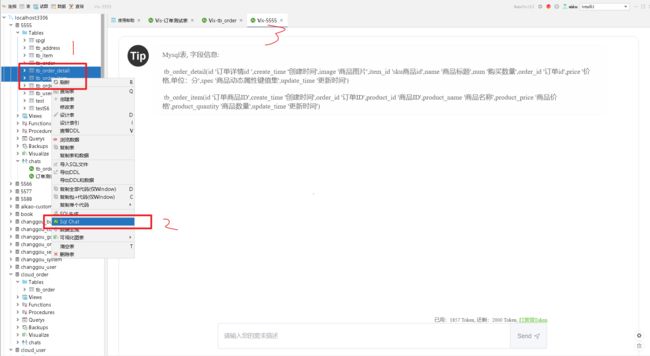
在数据库软件中,进入AI聊天非常简单按照以下2步进行即可:
选择你要操作的表,可以选择多张;
右键选择Sql Chat即可打开聊天窗口了
ChatGPT访问需要Token:
如果你有自己的token可以直接点击右下角的小齿轮,填写你自己的Token即可。
如果没有自己的token,可以通过‘打赏领Token功能’领取Token,然后即可访问。
数据库+AI:使用帮助-保存会话
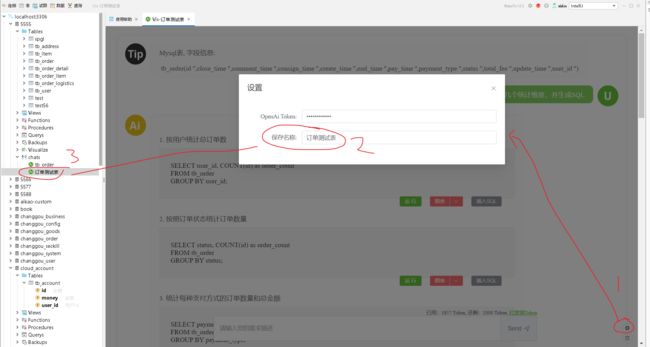
数据库AI聊天对话会保持到用户本地,以便再次打开,节省流量。要自定义保存文件名称,则参考以下操作步骤:
点击右下角‘小齿轮’
再弹出的对话框中填写保存的 ‘文件名称’
再次发送请求,程序会自动保存会话。
打开则只需要双击对应的会话名称即可(比如双击下图的3,就可以再次打开会话)。
数据库+AI:实现思路
还实现以上带有会话上下文的聊天功能,其实现原理其实很简单,但是有点费钱。具体实现的思路如下:
把对话中所有的消息都存储到一个集合中,比如下面第1处代码
过滤集合中那些请求失败的对话消息,比如下面第2处代码
ps:处理失败的消息,过滤掉主要原因是减少请求的Token,节省成本;
请求接口并获取响应数据,对响应数据进行SQL语句的解析,标记出来以便前端渲染演示和执行,比如下面第3处代码
// 1、存放所有的对话消息
List dtos = JSON.parseArray(tempMessages, ChatMessageDto.class);
// 2、过滤失败的消息
List messages = dtos.stream().filter(item -> item.getIsCall()==null||item.getIsCall()).map(item ->{
ChatMessage chatMessage = new ChatMessage();
chatMessage.setRole(item.getRole());
chatMessage.setContent(item.getContent());
return chatMessage;
}
).collect(Collectors.toList());
ChatMessageDto result = new ChatMessageDto();
List chatCompletionChoices = AiUtils.chatGpt(token, messages);
for (ChatCompletionChoice chatCompletionChoice : chatCompletionChoices) {
String content = chatCompletionChoice.getMessage().getContent();
// 3、把字符串消息,转成结构化的消息,便于运行SQL
result.setChatTerms(AiUtils.parseChatMessage(content));
result.setContent(content);
result.setRole(chatCompletionChoice.getMessage().getRole());
dtos.add(result);
} 第3处例子:
非结构化的数据:
\n\n统计维度:\n\n1. 按照用户ID统计总销售额\n2. 按照支付方式统计销售额占比\n3. 按照订单状态统计订单数量和销售额\n4. 按照下单时间统计每月销售额\n\nSQL语句:\n\n1. 按照用户ID统计总销售额\n\n```sql\nSELECT user_id, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY user_id;\n```\n\n2. 按照支付方式统计销售额占比\n\n```sql\nSELECT payment_type, SUM(total_fee) as total_sales, \n ROUND(SUM(total_fee)/(SELECT SUM(total_fee) FROM tb_order)*100,2) as sales_percentage\nFROM tb_order\nGROUP BY payment_type;\n```\n\n3. 按照订单状态统计订单数量和销售额\n\n```sql\nSELECT status, COUNT(*) as order_count, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY status;\n```\n\n4. 按照下单时间统计每月销售额\n\n```sql\nSELECT DATE_FORMAT(create_time, '%Y-%m') as month, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY month;\n```转成结构化的数据:
[
{
"content": "\n\n统计维度:\n\n1. 按照用户ID统计总销售额\n2. 按照支付方式统计销售额占比\n3. 按照订单状态统计订单数量和销售额\n4. 按照下单时间统计每月销售额\n\nSQL语句:\n\n1. 按照用户ID统计总销售额\n\n",
"type": "MES"
},
{
"content": "\nSELECT user_id, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY user_id;\n",
"type": "SQL"
},
{
"content": "\n\n2. 按照支付方式统计销售额占比\n\n",
"type": "MES"
},
{
"content": "\nSELECT payment_type, SUM(total_fee) as total_sales, \n ROUND(SUM(total_fee)/(SELECT SUM(total_fee) FROM tb_order)*100,2) as sales_percentage\nFROM tb_order\nGROUP BY payment_type;\n",
"type": "SQL"
},
{
"content": "\n\n3. 按照订单状态统计订单数量和销售额\n\n",
"type": "MES"
},
{
"content": "\nSELECT status, COUNT(*) as order_count, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY status;\n",
"type": "SQL"
},
{
"content": "\n\n4. 按照下单时间统计每月销售额\n\n",
"type": "MES"
},
{
"content": "\nSELECT DATE_FORMAT(create_time, '%Y-%m') as month, SUM(total_fee) as total_sales\nFROM tb_order\nGROUP BY month;\n",
"type": "SQL"
}
]