NIO vs BIO,零拷贝,同步阻塞、同步非阻塞、同步多路复用、异步非阻塞
同是IO,NIO 和BIO有什么区别?
什么是 同步阻塞、同步非阻塞、同步多路复用、异步非阻塞?
他们是如何工作的?
已经有了IO了NIO是干什么的?
这篇文章将带你解决这些疑惑
在学习Java基础是说起IO就不得不说起stream和NIO对应的channel那
stream与channel有何差别?
缓冲区差别:普通的stream不会缓冲数据,不带缓冲数据,频繁的进行读写切换导致性能不是很高,所以在stream使用时我们通常使用一个字节数组来进行数据暂存,来达到缓冲区的效果,减少读写切换来提高性能利用,对于channel它会利用系统的缓冲区接收区属于系统层面更加的底层。
阻塞差别:stream只能是阻塞的就是在执行的时候用户线程就必须进行阻塞状态,而且stream只能是阻塞的,channel可以是阻塞的也可以是非阻塞的,在创建channel时我们可以使用configureBlocking(false)方法来使其,进入非阻塞状态,它实现的非阻塞,就是一直在轮询,在等待响应时可以切换任务,而不是一直阻塞等待,但是这也不是很好的解决方案
他们两个都是双工的,也就是读写同时进行
阻塞影响性能,非阻塞,但是一直轮询让cpu高负载,那有没有什么更好的解决方案呢?
那就是
Selector多路复用
多路复用也是属于阻塞的,但是它充分利用了线程
多路复用是一个概念,不只是java中有,多路复用是一种思想在许多网络相关的地方常有涉及,让一个线程
多路复用可以看下图
普通channel
selector
一个线程可以通过selector来监听多个channel,当一个channel处于阻塞状态,线程可以先去处理其他channel的事情,当此channel有了返回值不再阻塞,此channel会继续执行的
在没有任何任务分配之前,selector就是阻塞状态一直在等待,等到有任何一个channel有请求动作,selector就进入非阻塞状态去处理有请求的相应,这样就不会让一个线程只等待一个请求
selector就是一个资源调度器,监视所有的连接channel,来进行任务的调度,来使其处于非阻塞状态
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic),如果数据量大其他通道还是需要等待
调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理
selector在下面分析原理时会进一步分析
我们可以小结一下
同步阻塞:streamIO属于阻塞IO,Filechannel也是阻塞IO,就是在IO的同时就算没有任务线程也在此等待,这就是阻塞IO
同步非阻塞IO:就是采用轮询,在channel处于阻塞等待时,线程并不会一直等待,而是查看其他channel是否有任务,一直在轮询
同步多路复用:阻塞的不是channel而是一个selector,不需要主动去轮询,selector管理的channel只要有请求就会触发往下运行,处理对应channel的任务
也可以说:
- 同步:线程自己去获取结果(一个线程)
- 异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)
下面的图解进一步帮助理解NIO BIO之间的区别
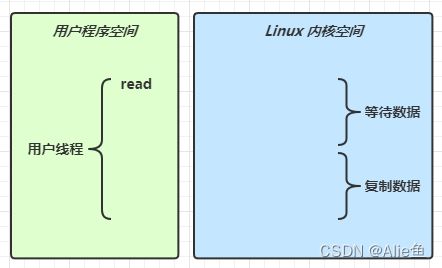
Java不能真正的进行网络通信,实际上的网络通信还是由操作系统来执行的,Java只是一个调用操作系统API的作用,所以发送网络请求需要转换为操作系统内核态
当调用channel或者stream读取操作后,会切换到操作系统内核态来完成真正的数据操作,而读取又分为两个阶段
- 等待数据阶段
- 复制数据阶段
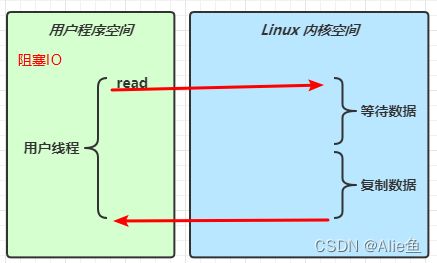
阻塞IO
在用户线程向操作系统发出读取请求,需要等待操作系统去响应操作,如果是网络IO在网络质量不好的情况下可能需要响应较长时间,如果因为此channel响应较慢而让一个线程处于等待这就是阻塞IO
阻塞io是指用户的线程被阻塞了,等待数据时阻塞,当数据到了,再从网卡进行复制,阻塞恢复,响应的数据也不会直接读入java中,因为通过网络IO请求数据此动作是操作系统来完成的,需要先读入操作系统再复制数据,然后再到java中
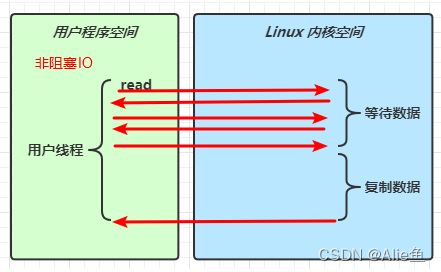
非阻塞 IO
非阻塞,在用户线程等待发送请求会不会进行阻塞等待而是立即返回,不会有长时间的阻塞,不过是一直在轮询,隔一段时间去检查是否有数据返回,当真正有数据返回是再进行数据的复制和读取,从图中可以看出,一直发送请求并立即返回,这样会白白浪费cpu性能
多路复用
先调用select方法先阻塞住,当有事件发生了selector停止阻塞,select就有可以通过key获得有请求的channel去调用read,如果需要复制数据还是阻塞状态,任何事件都会触发select

异步IO(AIO)
AIO 用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
Netty5版本特点也是使用异步IO但是由于性能没有提升,还多了更多的bug,维护成本也大大提高,最后导致版本废弃,现在主流版本还是Netty4
Linux现在也有很多异步IO方案:
-
glibcaio
在glibc aio的实现原理是,用多线程同步来模拟异步IO。 -
libaio
libaio是由linux内核提供的aio实现方案,类似于windows api。libaio与Glibc的多线程模拟不同 ,它是真正做到内核的异步通知,是真正意义上的异步IO。 -
libeio
libeio也是在用户态用多线程同步来模拟异步IO,但实现更高效,代码也更可靠,目前虽然是beta版,但已经可以上生产了(node.js底层就是用libev和libeio来驱动的)。libeio也不属于真正的异步IO, -
io_uring
需要5.1以上内核才能支持,一套全新的 syscall,一套全新的 async API,更高的性能,更好的兼容性,来迎接高 IOPS,高吞吐量的未来。
阻塞IO与多路复用差别
阻塞:在多用户线程下的阻塞io,在每次发出监听后都要进行阻塞等待,在做一件事的时候做不了其他的事情,阻塞IO只会响应它当前的任务,比如处于read响应状态,发送了连接请求由于read还没有执行,连接请求并不会得到任何响应
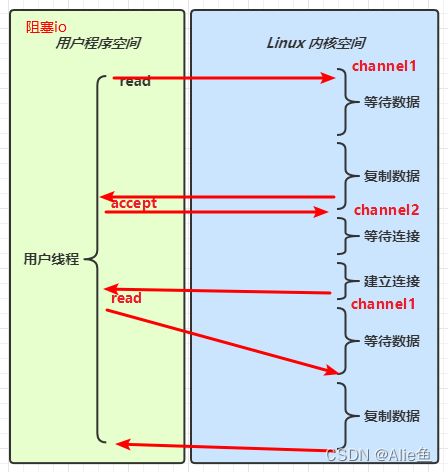
多路复用
在进行select监听,任何事件都会触发事件,让select向下运行,多个事件一次返回,减少了线程的空等待

零拷贝
零拷贝就是Java操作直接内存而不是Jvm内存,从系统的底层来减少IO次数来提高IO速度
传统的 IO
传统的 IO 将一个文件通过 socket 写出
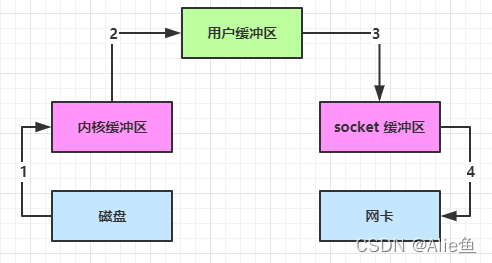
- java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu
DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO,DMA不会使用IO
-
从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA,因为这个IO操作不是操作系统层面的了,数据相当于内存读入java需要cpu进行数据的复制
-
调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝
-
接下来要向网卡写数据,这项能力 java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
NIO 优化
在使用NIO时分配缓存空间时有两个方法可以选择
- ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 java 内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存
大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用
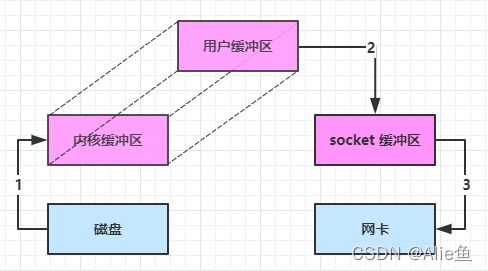
可以将内核缓冲区和用户缓冲区看作同一块内存,直接通过DMA复制到用户缓冲区,所以不需要,从内核缓冲区复制到用户缓冲区,cpu不需要参与减少了cpu压力,减少了一次数据的拷贝,
但是这样也有优缺点:
- 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
- 由于此内存不受JVM的管理,如果处理不当会导致内存的溢出
进一步优化
(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据 也就是常说的零拷贝
java中的transferTo/transferFrom不需要切换到java内存直接转到socket缓冲区,直接DMA将数据复制不需要cpu参与
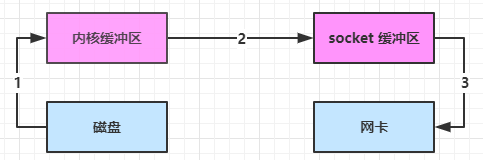
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了 3 次
进一步优化
(linux 2.4)再次优化直接将数据从内存缓冲区复制到网卡
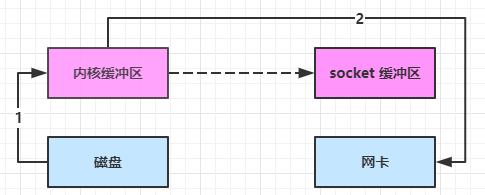
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
缺点也就是只适合小文件的传输