Redis 笔记(12)— 单线程架构(非阻塞 IO、多路复用)和多个异步线程
Redis 使用了单线程架构、非阻塞 I/O 、多路复用模型来实现高性能的内存数据库服务。Redis 是单线程的。那么为什么说是单线程呢?
Redis 在 Reactor 模型内开发了事件处理器,这个事件处理器分为多个 Socket(套接字)、IO 多路复用程序、事件分派器、事件处理器(连接应答处理器、命令请求处理器、命令回复处理器),其中事件派发器的队列是由单线程的事件处理器消费的,也是因为这个,Redis 才叫单线程模型。
当多个事件并发出现时,I/O 多路复用程序将监听到的所有 Socket,关联不同的事件处理器,这个关联操作以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向事件分派器传送 Socket,当上一个套接字产生的事件被处理完毕之后,I/O 多路复用程序才会继续向事件分派器传送下一个套接字。
1. 单线程模型
开启三个 redis-cli 客户端同时执行命令。客户端 1 设置一个字符串键值对:
127.0.0.1:6379> set hello world
客户端 2 对 counter 做自增操作:
127.0.0.1:6379> incr counter
客户端 3 对 counter 做自增操作:
127.0.0.1:6379> incr counter
Redis 客户端与服务端的模型可以简化成下图,每次客户端调用都经历了发送命令、执行命令、返回结果三个过程。
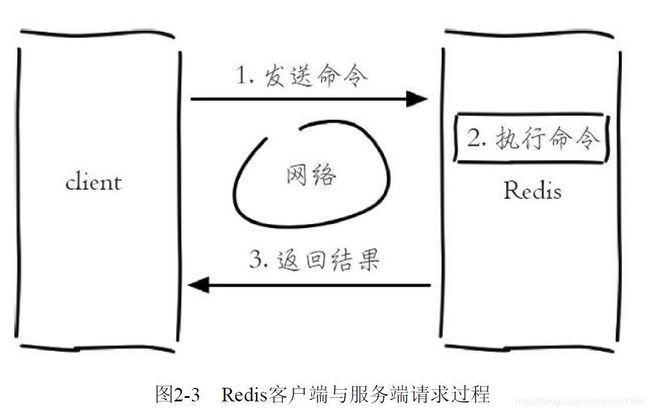
其中第 2 步是重点要讨论的,因为 Redis 是单线程来处理命令的,所以一条命令从客户端达到服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。
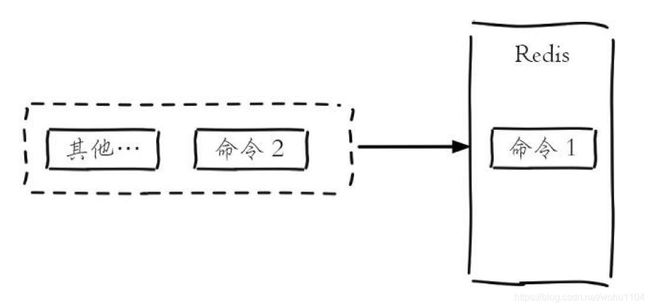
所以上面 3 个客户端命令的执行顺序是不确定的,如下图所示。但是可以确定不会有两条命令被同时执行
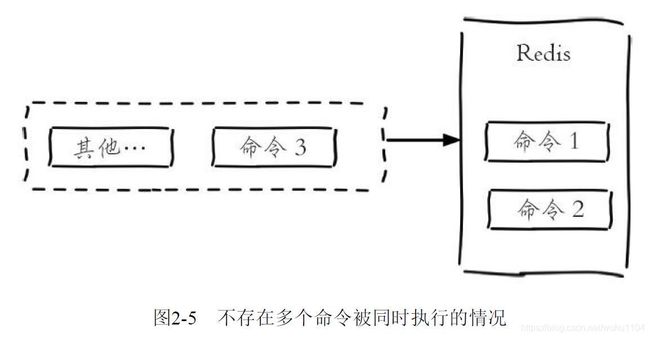
所以两条 incr 命令无论怎么执行最终结果都是 2,不会产生并发问题,这就是 Redis 单线程的基本模型。
2. 非阻塞 IO
当我们调用套接字的读写方法,默认它们是阻塞的,比如 read 方法要传递进去一个参数 n,表示最多读取这么多字节后再返回,如果一个字节都没有,那么线程就会卡在那里,直到新的数据到来或者连接关闭了,read 方法才可以返回,线程才能继续处理。而 write 方法一般来说不会阻塞,除非内核为套接字分配的写缓冲区已经满了,write 方法就会阻塞,直到缓存区中有空闲空间挪出来了。
非阻塞 IO 在套接字对象上提供了一个选项 Non_Blocking,当这个选项打开时,读写方法不会阻塞,而是能读多少读多少,能写多少写多少。能读多少取决于内核为套接字分配的读缓冲区内部的数据字节数,能写多少取决于内核为套接字分配的写缓冲区的空闲空间字节数。读方法和写方法都会通过返回值来告知程序实际读写了多少字节。
有了非阻塞 IO 意味着线程在读写 IO 时可以不必再阻塞了,读写可以瞬间完成然后线程可以继续干别的事了。
3. 多路复用(事件轮询)
非阻塞 IO 有个问题,那就是线程要读数据,结果读了一部分就返回了,线程如何知道何时才应该继续读。也就是当数据到来时,线程如何得到通知。写也是一样,如果缓冲区满了,写不完,剩下的数据何时才应该继续写,线程也应该得到通知。
事件轮询 API 就是用来解决这个问题的,最简单的事件轮询 API 是 select 函数,它是操作系统提供给用户程序的 API。输入是读写描述符列表 read_fds & write_fds,输出是与之对应的可读可写事件。同时还提供了一个 timeout 参数,如果没有任何事件到来,那么就最多等待 timeout 时间,线程处于阻塞状态。一旦期间有任何事件到来,就可以立即返回。时间过了之后还是没有任何事件到来,也会立即返回。拿到事件后,线程就可以继续挨个处理相应的事件。处理完了继续过来轮询。于是线程就进入了一个死循环,我们把这个死循环称为事件循环,一个循环为一个周期。
每个客户端套接字 socket 都有对应的读写文件描述符。
read_events, write_events = select(read_fds, write_fds, timeout)
for event in read_events:
handle_read(event.fd)
for event in write_events:
handle_write(event.fd)
handle_others() # 处理其它事情,如定时任务等
因为我们通过 select 系统调用同时处理多个通道描述符的读写事件,因此我们将这类系统调用称为多路复用 API 。
现代操作系统的多路复用 API 已经不再使用 select 系统调用,而改用 epoll(linux) 和 kqueue(freebsd & macosx),因为 select 系统调用的性能在描述符特别多时性能会非常差。它们使用起来可能在形式上略有差异,但是本质上都是差不多的,都可以使用上面的伪代码逻辑进行理解。
服务器套接字 serversocket 对象的读操作是指调用 accept 接受客户端新连接。何时有新连接到来,也是通过 select 系统调用的读事件来得到通知的。
4. 为什么单线程还能如此快
为什么 Redis 使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
- 纯内存访问,
Redis将所有数据放在内存中,内存的响应时长大约为 100 纳秒,这是Redis达到每秒万级别访问的重要基础。 - 非阻塞
I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为件,不在网络I/O上浪费过多的时间。 - 单线程避免了线程切换和竞态产生的消耗。
单线程能带来几个好处:
- 单线程可以简化数据结构和算法的实现。如果对高级编程语言熟悉的读者应该了解并发数据结构实现不但困难而且开发测试比较麻烦。
- 单线程避免了线程切换和竞态产生的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。
但是单线程会有一个问题:对于每个命令的执行时间是有要求的。如果某个命令执行过长,会造成其他命令的阻塞,对于 Redis 这种高性能的服务来说是致命的,所以 Redis 是面向快速执行场景的数据库。
5. 多个异步线程
5.1 懒惰删除
在 4.0 版本引入了 unlink 指令,它能对删除操作进行懒处理,丢给后台线程来异步回收内存。
> unlink key
OK
可以将整个 Redis 内存里面所有有效的数据想象成一棵大树。当 unlink 指令发出时,它只是把大树中的一个树枝别断了,然后扔到旁边的火堆里焚烧 (异步线程池)。树枝离开大树的一瞬间,它就再也无法被主线程中的其它指令访问到了,因为主线程只会沿着这颗大树来访问。
Redis 提供了 flushdb 和 flushall 指令,用来清空数据库,这也是极其缓慢的操作。Redis 4.0 同样给这两个指令也带来了异步化,在指令后面增加 async 参数就可以将整棵大树连根拔起,扔给后台线程慢慢焚烧。
> flushall async
OK
5.2 异步队列
主线程将对象的引用从「大树」中摘除后,会将这个 key 的内存回收操作包装成一个任务,塞进异步任务队列,后台线程会从这个异步队列中取任务。任务队列被主线程和异步线程同时操作,所以必须是一个线程安全的队列。
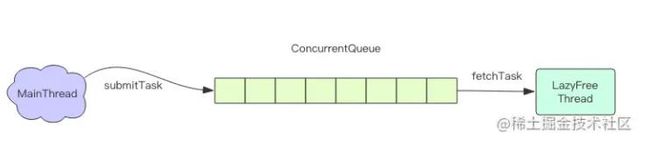
不是所有的 unlink 操作都会延后处理,如果对应 key 所占用的内存很小,延后处理就没有必要了,这时候 Redis 会将对应的 key 内存立即回收,跟 del 指令一样。
5.3 其它异步删除点
Redis 回收内存除了 del 指令和 flush 之外,还会存在于在 key 的过期、LRU 淘汰、rename 指令以及从库全量同步时接受完 rdb 文件后会立即进行的 flush 操作。
Redis4.0 为这些删除点也带来了异步删除机制,打开这些点需要额外的配置选项。
slave-lazy-flush从库接受完rdb文件后的flush操作lazyfree-lazy-eviction内存达到maxmemory时进行淘汰lazyfree-lazy-expire key过期删除lazyfree-lazy-server-del rename指令删除 destKey
参考:
- 《Redis 开发运维》
- https://juejin.cn/book/6844733724618129422/section/6844733724710420487