CountVectorizer详解
CountVectorizer详解
1、引入countvectorizer
from sklearn.feature_extraction.text import CountVectorizer
2、定义文本列表,这里写了个二维的。
from sklearn.feature_extraction.text import CountVectorizer
X_test = ['you are good','but we do not fit']
3、文本向量化与函数展示
from sklearn.feature_extraction.text import CountVectorizer
X_test = ['you are good','but we do not fit']
vectorizer = CountVectorizer()
count = vectorizer.fit_transform(X_test)
print(count)
print(vectorizer.get_feature_names())
print(vectorizer.vocabulary_)
print(count.toarray())
结果如下:
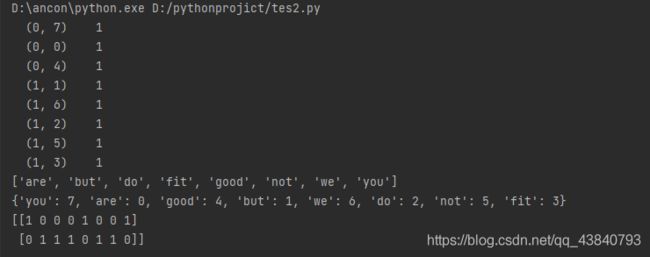
(1)这个文本有哪些词汇,用get_feature_names()函数,得到的结果是[‘are’, ‘but’, ‘do’, ‘fit’, ‘good’, ‘not’, ‘we’, ‘you’],按首字母顺序来排列的。
(2)文本各个词汇按首字母的位置是几号,用vocabulary_函数,得到{‘you’: 7, ‘are’: 0, ‘good’: 4, ‘but’: 1, ‘we’: 6, ‘do’: 2, ‘not’: 5, ‘fit’: 3},比如are的首字母是a,排在第一位,序号为0。
(3)每个句子出现了哪些单词,用toarray()函数。1表示出现,0表示没出现。

所以toarray()输出的是二维的。
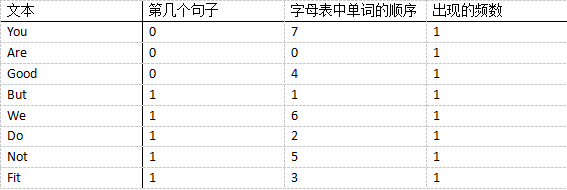
(4)文本词汇出现的频率,用vectorizer.fit_transform(文本)进行统计,统计的字段如下表所示,其中前两列算是位置,最后一列是词频,就得到python中的输出。
4、参数
参数可以自己搜,只要把countvectorizer的函数计算规则返回值搞清楚了,什么参数都简单。