hadoop配置Hadoop 2.0--分布式环境搭建安装配置
PS:今天上午,非常郁闷,有很多简单基础的问题搞得我有些迷茫,哎,代码几天不写就忘。目前又不当COO,还是得用心记代码哦!
集群环境:
1 NameNode(真实主机):
Linux yan-Server 3.4.36-gentoo #3 SMP Mon Apr 1 14:09:12 CST 2013 x86_64 AMD Athlon(tm) X4 750K Quad Core Processor AuthenticAMD GNU/Linux
2 DataNode1(虚拟机):
Linux node1 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
3 DataNode2(虚拟机):
Linux node2 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
4 DataNode3(虚拟机):
Linux node3 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
原创作品,转载请表明:
http://blog.csdn.net/yming0221/article/details/8989203
1.安装VirtualBox虚拟机
Gentoo下直接命令编译安装,或者官网下载二进制安装包直接安装:
emerge -av virtualbox
2.虚拟机下安装Ubuntu 12.04 LTS
应用Ubuntu镜像安装完成后,然后再克隆另外两台虚拟主机(这里会碰到克隆的主机启动的时候主机名和MAC地址会是一样的,局域网会造成冲突)
主机名修改文件
/etc/hostname
MAC地址修改需要先删除文件
/etc/udev/rules.d/70-persistent-net.rules
然后在启动之前设置VirtualBox虚拟机的MAC地址

启动后会主动生成删除的文件,配置网卡的MAC地址。
为了更方便的在各主机之间共享文件,可以启动主机yan-Server的NFS,将命令参加/etc/rc.local中,让客户端主动挂载NFS目录。
删除各虚拟机的NetworkManager,手动设置静态的IP地址,例如node2主机的/etc/network/interfaces文件配置如下:
auto lo iface lo inet loopback auto eth0 iface eth0 inet static address 192.168.137.202 gateway 192.168.137.1 netmask 255.255.255.0 network 192.168.137.0 broadcast 192.168.137.255
主机的基本环境设置完毕,上面是主机对应的IP地址
| 类型 | 主机名 | IP |
| NameNode | yan-Server | 192.168.137.100 |
| DataNode | node1 | 192.168.137.201 |
| DataNode | node2 | 192.168.137.202 |
| DataNode | node3 | 192.168.137.203 |
为了节省资源,可以设置虚拟机默认启动字符界面,然后通过主机的TERMINAL ssh远程登录。(SSH已经启动服务,允许远程登录,安装方法不再赘述)
设置方法是修改/etc/default/grub文件将上面的一行消除注释
GRUB_TERMINAL=console
然后update-grub便可。
3.Hadoop环境的配置
3.1配置JDK环境(之前就做好了,这里不再赘述)
export JAVA_HOME=/opt/jdk1.7.0_21 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3.2在官网下载Hadoop,然后解压到/opt/目录上面(这里应用的是hadoop-2.0.4-alpha)
然后进入目录/opt/hadoop-2.0.4-alpha/etc/hadoop,配置hadoop文件
修改文件hadoop-env.sh
export HADOOP_FREFIX=/opt/hadoop-2.0.4-alpha
export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
export PATH=$PATH:$HADOOP_FREFIX/bin
export PATH=$PATH:$HADOOP_FREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
export YARN_HOME=${HADOOP_FREFIX}
export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
export JAVA_HOME=/opt/jdk1.7.0_21
修改文件hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-2.0.4-alpha/workspace/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-2.0.4-alpha/workspace/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored. </description> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permission</name> <value>false</value> </property> </configuration>
修改文件mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.job.tracker</name> <value>hdfs://yan-Server:9001</value> <final>true</final> </property> <property> <name>mapreduce.map.memory.mb</name> <value>1536</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1024M</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>3072</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx2560M</value> </property> <property> <name>mapreduce.task.io.sort.mb</name> <value>512</value> </property> <property> <name>mapreduce.task.io.sort.factor</name> <value>100</value> </property> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>50</value> </property> <property> <name>mapred.system.dir</name> <value>file:/opt/hadoop-2.0.4-alpha/workspace/systemdir</value> <final>true</final> </property> <property> <name>mapred.local.dir</name> <value>file:/opt/hadoop-2.0.4-alpha/workspace/localdir</value> <final>true</final> </property> </configuration>
修改文件yarn-env.xml
export HADOOP_FREFIX=/opt/hadoop-2.0.4-alpha
export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
export PATH=$PATH:$HADOOP_FREFIX/bin
export PATH=$PATH:$HADOOP_FREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
export YARN_HOME=${HADOOP_FREFIX}
export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
export JAVA_HOME=/opt/jdk1.7.0_21
修改文件yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.address</name> <value>yan-Server:8080</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>yan-Server:8081</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>yan-Server:8082</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce.shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
将配置好的Hadoop复制到各DataNode(这里DataNode的JDK配置和主机的配置是分歧的,不需要再修改JDK的配置)
3.3 修改主机的/etc/hosts,将NameNode参加该文件
192.168.137.100 yan-Server 192.168.137.201 node1 192.168.137.202 node2 192.168.137.203 node3
3.4 修改各DataNode的/etc/hosts文件,也添加上述的内容
192.168.137.100 yan-Server 192.168.137.201 node1 192.168.137.202 node2 192.168.137.203 node3
3.5 配置SSH免密码登录(所有的主机都应用root用户登录)
主机上运行命令
ssh-kengen -t rsa
一起回车,然后复制.ssh/id_rsa.pub为各DataNode的root用户目录.ssh/authorized_keys文件
然后在主机上远程登录一次
ssh root@node1
初次登录可能会需要输入密码,之后就不再需要。(其他的DataNode也都远程登录一次确保可以免输入密码登录)
4.启动Hadoop
为了方便,在主机的/etc/profile配置hadoop的环境变量,如下:
export HADOOP_PREFIX="/opt/hadoop-2.0.4-alpha"
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}
4.1 格式化NameNode
hdfs namenode -format
4.2 启动全部进程
start-all.sh
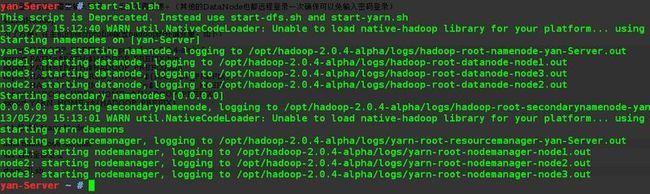
在浏览器查看,地址:
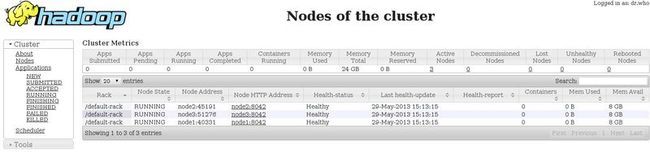
所有数据节点DataNode畸形启动。
4.3 关闭所有进程
stop-all.sh
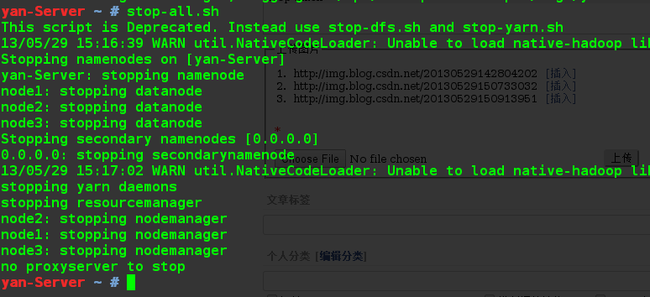
至此,Hadoop环境搭建基本结束。
参考:
1.实战Hadoop--开启通向云计算的捷径(刘鹏)
2.http://www.cnblogs.com/aniuer/archive/2012/07/16/2594448.html
文章结束给大家分享下程序员的一些笑话语录: 一程序员告老还乡,想安度晚年,于是决定在书法上有所造诣。省略数字……,准备好文房4宝,挥起毛笔在白纸上郑重的写下:Hello World
--------------------------------- 原创文章 By
hadoop和配置
---------------------------------