ets学习
http://diaocow.iteye.com/blog/1768647
http://www.cnblogs.com/me-sa/archive/2011/08/11/erlang0007.html
ets是什么?
ets是Erlang Term Storage的缩写,它是一个基于内存的KV Table,支持大数据量存储以及高效查询.
ets有4种类型的table:
| set | table中的每一个Value(Tuple)都是唯一,并且一个Key只能对应一个Value |
| ordered_set | 同set,唯一不同的是table中的Key是有序的 |
| bag | table中的每一个Value都是唯一,但是一个key可以对应多个Value |
| duplicate_bag | table中每一个key可以对应多个Value,并且允许Value重复 |
那么table中的Key如何定义,Value又是什么呢?
table中的Value是一个tuple,而它的Key就是tuple中的第一个元素(默认),譬如,我往ets table插入一个{name, diaocow},那么Key就是name,Value就是{name, diaocow},于是就在ets table中建立了这么一条映射关系:name -> {name, diaocow}
这4种类型table有什么区别,查找效率又如何?
set, bag, duplicate_bag内部是采用哈希结构实现,因此查找效率很高,O(1);
ordered_set 内部是采用平衡树结构实现(Key之间是有序的),查找效率相比其他类型略低,是logN级别的;
至于选用何种类型的table,需要根据实际需求来确定,如果你需要元素之间有序,那么你只能选用ordered_sets(需要牺牲一点效率)
bag,duplicate_bag 虽然在查找效率上差不多,但是在插入元素时却有可能千差万别,为什么呢?
因为bag虽然允许table中每一个Key对应多个Value,但是它不允许这些Value重复,所以在插入具有相同Key的Value时,它必须与每一个现有元素作对比,而duplicate bag 允许table中的Value重复,所以它在插入时就完全不需要考虑这些,只管插,所以效率很高.
现在我们就来看看书上的一个例子,加上理解: 
运行结果: 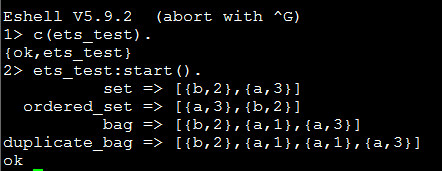
注意对于set和ordered_set 当插入具有相同Key的Value时,后插入的Value会替代上一个Value(譬如这里的{a,1}被{a,3}替代),另外在erlang的每一个node中,可以创建的ets table数量是有限的(默认为1440,不过我的测试结果确是2037???),这个值可以通过修改环境变量ERL_MAX_ETS_TABLES来修改(官方文档建议实际中采用的值比这个高些)
-------------------------------------------------------------------------------华丽分割线-------------------------------------------------------------------------------
现在我们重新回到刚才那个例子,来学习几个api:
1.ets:new(Name, Options) -> tid() | atom()
这个函数用来创建一个名为Name的table(若创建成功,返回一个TableId或者TableName供process引用);Options是一个选项list,用来指定创建table的各种属性,它的值有:
| set,ordered_set,bag,duplicate_bag | 指定创建的table类型 |
| public,private,protected | 指定table的访问权限,若是public表示所有process都可以对该table进行读写(只要你知道TableId或者TableName),private表示只有创建表的process才能对table进行读写,而protected则表示所有的process都可以对表进行读取,但是只有创建表的process能够对表进行写操作(ps: ets table仅可以被同一个erlang node中的processes共享) |
| named_table | 若指定了named_table这个属性,就可以使用表名(也就是new函数的第一个参数Name)对表进行操作,而无需使用TableId |
| {keypos,Pos} | 上面说到,我们默认使用tuple中第一个元素作为Key,那么是否可以修改这个规则呢?自然可以,使用{keypos,Pos}即可,其中Pos就是表示使用tuple中第几个元素作为Key |
| {heir, Pid, HeirData},{heir,none} | 这个heir属性指明当创建table的process终止时,是否有其他process来继承这个table,默认值是{heir,none},表示没有继承者,所以当创建表的process终止时,表也随之被delete;若我们指定了{heir,Pid,HeirData},那么当创建表的process终止时,process identifer为Pid的process将会收到一个消息:{'ETS-TRANSFER',tid(),FromPid,HeirData},这样表的拥有权就转交了,我们可以看下面这段测试代码 |

运行结果: 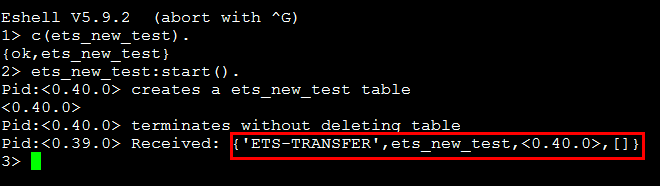
如果你不指定任何Options(即参数值为[]),那么ets将会使用[set, protected, {keypos,1}, {heir,none}, {write_concurrency,false}, {read_concurrency,false}]作为默认值(关于write_concurrency和read_concurrency这个两个参数的具体含义自己不是特别的清楚,目前只是了解到该参数用于设置是否允许并发读或者写,和性能调优相关,所以暂时hold)
2. ets:insert(Tab, ObjectOrObjects) -> true
很显然这个函数是用来往table里插入数据,其中第一个参数Tab表示需要操作哪一张表,它可以是TableId或者TableName(若创建表时指定了named_table选项),第二个参数ObjectOrObjects表示需要插入的数据,它可以是一个tuple或者是一个tuple list;注意这个insert方法是一个原子操作,并且对于set或者ordered_set类型table,在插入具有相同Key的Value时,会用新值去替换老值;
那么ets是如何判断两个Key是否相同呢?它分为match和compare equal 两种情况:
1.如果两个Key(erlang term)match,那么这两个Key不仅值相同,类型也相同;
2.如果两个Key (erlang term)compare equal, 那么只需要这两个Key的值相同,而无需类型相同(譬如 1.0 compare equal 1,但是1 not match 1.0)
所以若两个Key match,则它们一定compare equal,反过来则不行,那在ets中到底是采用match还是compare equal进行判断与table的类型有关,其中ordered_set采用compare equal方式匹配,其余类型都采用match方式匹配,我们来看下面一个例子: 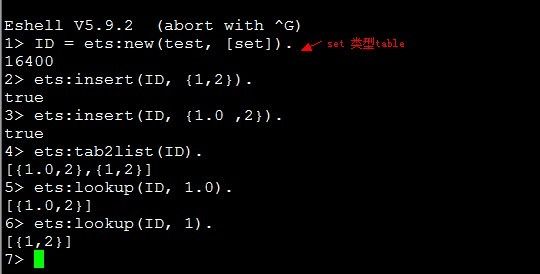
这是一个set类型table,所以在比较Key时采用match方式进行匹配(既比较类型也比较值),所以它认为1.0和1是两个不同的Key,因此插入了两个Tuole,现在我们再看另外一个例子,对比一下: 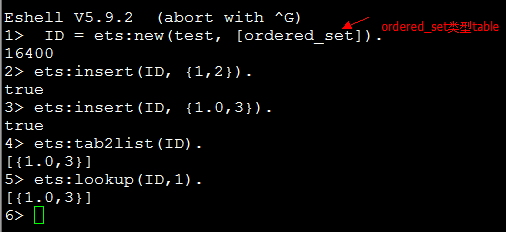
对于ordered_set类型table,它采用compare equal方式进行匹配(仅比较值),所以它认为1.0和1是两个相同的Key,因此用新值{1.0,3} 替换了老值{1, 2}(注意看tab2list方法),相关官方文档:
3. ets:lookup(Tab, Key) -> [Object]
第一个参数Tab,不再解释,与insert函数中的一样,第二个参数就是需要查找的Key,它以list的形式返回符合条件的tuple(可以参看我们上一个例子代码),相关官方文档:
If the table is of type set or ordered_set, the function returns either the empty list or a list with one element, as there cannot be more than one object with the same key. If the table is of type bag or duplicate_bag, the function returns a list of arbitrary length.
除了使用lookup来查找,ets还提供了一些更为强大的查找方法:
4.match(Tab, Pattern) -> [Match]
该方法用来查找table中所有匹配Pattern的tuple并返回tuple中某些或全部元素(这个由pattern指定),譬如: 
运行结果: 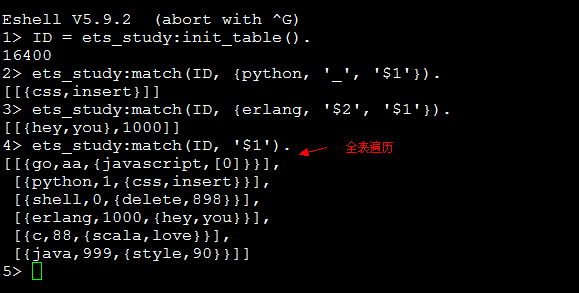
其中Pattern可以包含以下字符
1.一个绑定变量或者任意Erlang Term;
2.一个占位符'_',可以匹配任何Erlang Term;
3.一个变量符'$N' (N可以为0,1,2,3....),该变量指定了match方法需要返回tuple中哪些元素;
若Pattern中包含Key值,那么查找起来非常快速(相当于索引查询),否则需要全表遍历
我们除了可以一次性查找出所有满足匹配的tuples,也可以采用"分页查询"的方式查询,即每次只查询出部分结果,然后通过迭代查找出所有结果: 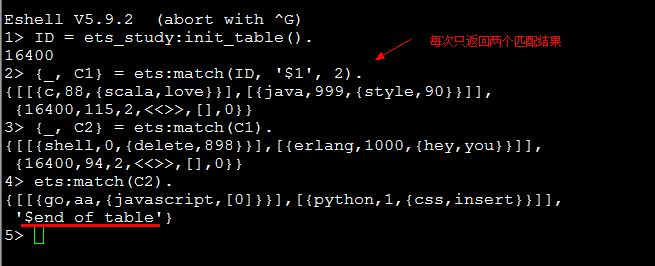
其中:
5.match(Tab, Pattern, Limit) -> {[Match],Continuation} | '$end_of_table'
用来返回table中满足匹配的tuples并且数量限制为Limit,返回值Continuation用来传递给match(Continuation)方法进行下一次迭代,直到遍历完table(返回结尾标示:'$end_of_table'); Api文档中提到:用这种方式遍历表的效率高于first和next方法(这两个方法后面会提到)
最后我们来看下ets table的遍历
first(Tab) -> Key | '$end_of_table'
next(Tab, Key1) -> Key2 | '$end_of_table'
first方法用来返回table中第一个Key,而next方法返回table中在Key1后面的Key2,如果这是一张空表或者Key1已经是表的最后一个Key,那么first方法以及next方法将返回'$end_of_table'作为结尾标记,我们可以使用这组方法对一个table的Key进行遍历: 
另外对于ordered_set类型table,它的Key本身就是有序的(因为它内部采用平衡树结构,按照Erlang Term Order排列),所以在遍历ordered_set类型table时,它的Key会按Erlang Term Order输出,而对于其他类型的table,遍历table时Key的顺序是不确定的;
last(Tab) -> Key | '$end_of_table'
prev(Tab, Key1) -> Key2 | '$end_of_table'
这组遍历方式和first/last基本相同,唯一不同的是,它是从后往前遍历
至此我想大家已经基本了解了:
1.ets table的类型分类
2.ets table的创建
3.ets table的插入和查找
4.ets table的遍历
-------------------------------------------------------------------------------华丽分割线-------------------------------------------------------------------------------
ets其他一些细节:
1.官方文档中提到: In the current implementation, every object insert and look-up operation results in a copy of the object,这是什么意思呢?
意思是,在当前erlang的实现版本中,插入一个tuple:会从当前process中的stack和heap拷贝tuple的一副副本到ets table中去,同样查询操作也会导致从表中拷贝一份tuple(或多个tuples)到执行查询的process的stack和heap中去,这种行为适用于erlang所有的数据类型,除了binaries;
2.ets table是不会被垃圾回收的,只有当下面两种情况它会被销毁:
a.调用delete方法;
b.创建ets table的process结束;
3.关于ordered_set类型table,它的内部元素根据Key值按照Erlang Term Order排序,那么Erlang Term Order是什么呢?
a.如果比较的两个值不是同一种数据类型,则按照这种规则比较:number < atom < reference < fun < port < pid < tuple < list < bit string;
b.如果比较的两个值都是List,那么它会逐个比较其中元素;
3.如果比较的两个值都是Tuple,那么它首先会比较Tuple Size是否相同(即元素个数),若Size相同则逐个比较其中的元素; 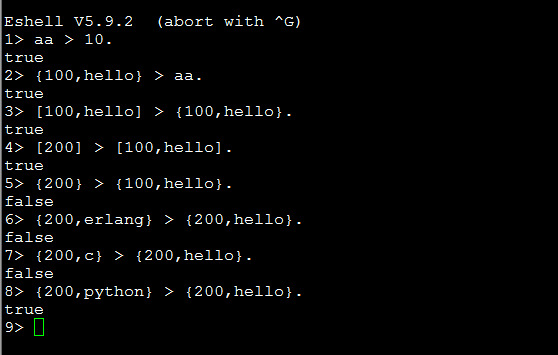
关于ets更详细内容,请参看文档:http://www.erlang.org/doc/man/ets.html