前言
之前总在聊微服务, 微服务本身也是分布式系统,其实微服务的核心思想是分而治之,把一个复杂的单体系统,按照业务的交付,分成不同的自服务,以降低资深复杂度,同时可以提升系统的扩展性。
今天想聊一下分库分表,因为对于快速增长的业务来说,这个是无法回避的一环。之前我在做商城相关的SAAS系统,商品池是一个存储瓶颈,商品池数量会基于租户增长和运营变得指数级增长,短短几个月就能涨到几千万的数据,而运营半年后就可能过亿。而对于订单这种数据,也会跟着业务的成长,也会变得愈发巨大。
存储层来说,提升大数据量下的存储和查询性能,就涉及到了另一个层面的问题,但思想还是一样的,分而治之。
我们面临什么样的问题
关系型数据库在大于一定数据量的情况下检索性能会急剧下降。在面对海量数据情况时,所有数据都存于一张表,显然会轻易超过数据库表可承受的。
此外单纯的分表虽然可以解决数据量过大导致检索变慢的问题,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以需要分库来解决单数据库实例性能瓶颈问题。
数据库架构方案
在讲具体解决方案之前,我们需要先了解一下数据库的三种架构涉及方案。
1. Shared Everything
一般指的是单个主机的环境,完全透明共享的CPU/内存/硬盘,并行处理能力是最差的,一般不考虑大规模的并发需求,架构比较简单,一般的应用需求基本都能满足。
2. Shared Disk
各处理单元使用自己的私有CPU和Memory,共享磁盘系统。典型的代表是Oracle RAC、DB2 PureScale。例如Oracle RAC,他用的是共享存储,做到了数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好,使用Storage Area Network (SAN),光纤通道连接到多个服务器的磁盘阵列,降低网络消耗,提高数据读取的效率,常用于并发量较高的OLTP应用。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能,同时更多的节点,则增加了运维的成本。
3. Shared Nothing
各处理单元都有自己私有的CPU/内存/硬盘等,Nothing,顾名思义,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表DB2 DPF、带分库分表的MySQL Cluster,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
我们常说的Sharding其实就是Shared Nothing,他是将某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的schema,例如MySQL Proxy和Google的各种架构,只需增加服务器数就可以增加处理能力和容量。
至于MPP,指的是大规模并行分析数据库(Analytical Massively Parallel Processing (MPP) Databases),他是针对分析工作负载进行了优化的数据库,一般需要聚合和处理大型数据集。MPP数据库往往是列式的,因此MPP数据库通常将每一列存储为一个对象,而不是将表中的每一行存储为一个对象。这种体系结构使复杂的分析查询可以更快,更有效地处理。例如TeraData、Greenplum,GaussDB100、TBase。
基于以上的这几种架构方案,我们可以给出大数据量存储的解决方案:
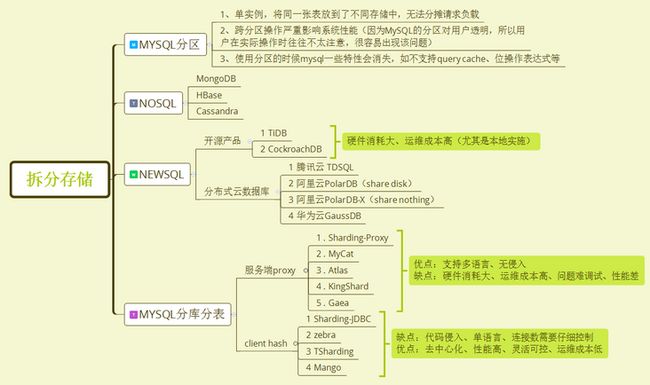 []()
[]()
以上几种解决方案各有利弊,分区模式最大的问题是准share everything架构,无法水平扩展cpu和内存,所以基本可以排除;nosql本身其实是个非常好的备选方案,但是nosql(包括大部分开源newsql)硬件消耗非常大,运维成本较高。而常用的一种方案就是基于Mysql的分库分表方案。
分库分表架构方案
对于分库分表,首先看一下市面上有哪些产品。
| 业界组件 | 原厂 | 功能特性 | 备注 |
|---|---|---|---|
| DBLE | 爱可生开源社区 | 专注于mysql的高可扩展性的分布式中间件 | 基于MyCAT开发出来的增强版。 |
| Meituan Atlas | 美团 | 读写分离、单库分表 | 目前已经在原厂逐步下架。 |
| Cobar | 阿里(B2B) | Cobar 中间件以 Proxy 的形式位于前台应用和实际数据库之间,对前台的开放的接口是 MySQL 通信协议 | 开源版本中数据库只支持 MySQL,并且不支持读写分离。 |
| MyCAT | 阿里 | 是一个实现了 MySQL 协议的服务器,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生协议与多个 MySQL 服务器通信 | MyCAT 基于阿里开源的 Cobar 产品而研发 |
| Atlas | 360 | 读写分离、静态分表 | 2015年后已经不在维护 |
| Kingshard | 开源项目 | 由 Go 开发高性能 MySQL Proxy 项目,在满足基本的读写分离的功能上,Kingshard 的性能是直连 MySQL 性能的80%以上。 | |
| TDDL | 阿里淘宝 | 动态数据源、读写分离、分库分表 | TDDL 分为两个版本, 一个是带中间件的版本, 一个是直接Java版本 |
| Zebra | 美团点评 | 实现动态数据源、读写分离、分库分表、CAT监控 | 功能齐全且有监控,接入复杂、限制多。 |
| MTDDL | 美团点评 | 动态数据源、读写分离、分布式唯一主键生成器、分库分表、连接池及SQL监控 | |
| Vitess | 谷歌、Youtube | 集群基于ZooKeeper管理,通过RPC方式进行数据处理,总体分为,server,command line,gui监控 3部分 | Youtube 大量应用 |
| DRDS | 阿里 | DRDS(Distributed Relational Database Service)专注于解决单机关系型数据库扩展性问题,具备轻量(无状态)、灵活、稳定、高效等特性,是阿里巴巴集团自主研 | |
| Sharding-proxy | apache开源项目 | 提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。向应用程序完全透明,可直接当做MySQL使用。适用于任何兼容MySQL协议的客户端。 | Apache项目,定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 |
| Sharding jdbc | apache开源项目 | 完全兼容JDBC和各种ORM框架。适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。基于任何第三方的数据库连接池,如:DBCP,C3P0, BoneCP, Druid, HikariCP等。支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL | Apache项目,定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动 |
对于分库分表的产品模式,又分为两种,中间件模式和客户端模式。
1. 中间件模式其优缺点
中间件模式独立进程,所以可以支持异构语言,对当前程序没有侵入性,对业务方来说是透明的mysql服务,但是缺点也非常明显,硬件消耗大、运维成本高(尤其是在本地化实施情况下),同时因为对关系型数据库增加了代理,会造成问题难调试。
2. 客户端模式优缺点
客户端模式的主要缺点是对代码有侵入,所以基本只能支持单语言,同时因为每个客户端都要对schema建立连接,所以如果数据库实例不多,需要对连接数仔细控制,但是客户端模式的优点也非常明显,首先从架构上它是去中心化的,这样就避免了中间件模式的proxy故障问题,同时因为没有中间层性能高、灵活可控,而且因为没有proxy层,不需要考虑proxy的高可用和集群,运维成本也比较低。
sharding-jdbc接入实战
sharding-jdbc其实是这些产品中最为大家熟知的,也是因为它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。而且在社区活跃度,代码质量等方面,也是很不错的。接下来,我讲详细讲一下接入细节。
1. 组件集成
org.apache.shardingsphere
shardingsphere-jdbc-core-spring-boot-starter 5.0.0
com.baomidou
dynamic-datasource-spring-boot-starter
3.4.0
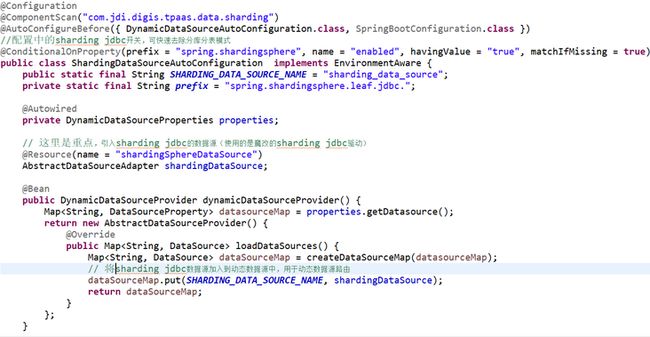
2. bean配置
配置sharding jdbc数据源并且加入到动态数据源中,用于数据源路由。
 []()
[]()
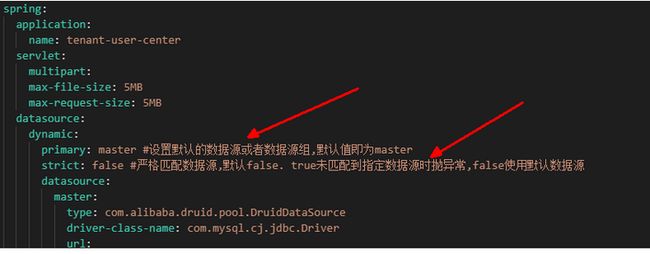
修改原配置中心对应服务的mysql数据源配置,对不分库分表的数据源配置为动态数据源默认路由
 []()
[]()
3. sharing JDBC配置
spring.shardingsphere.enabled=true #shardingsphere开关
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.mode.type=Standalone #在使用配置中心的情况下,使用standalone模式即可(memery、standalone、cluster三种模式)
spring.shardingsphere.mode.repository.type=File #standalone模式下使用File,即当前配置文件
spring.shardingsphere.mode.overwrite=true # 本地配置是否覆盖配置中心配置。如果可覆盖,每次启动都以本地配置为准。
spring.shardingsphere.datasource.names=ds-0,ds-1 #配置数据源名字,真实数据源
#配置ds-0数据源
spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://****
spring.shardingsphere.datasource.ds-0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-0.username=
spring.shardingsphere.datasource.ds-0.password=
#配置ds-1数据源
spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://****
spring.shardingsphere.datasource.ds-1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-1.username=
spring.shardingsphere.datasource.ds-1.password=
#配置模式数据库分片键和相关的表
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
spring.shardingsphere.rules.sharding.broadcast-tables=t_address #配置广播表,即所有库中都会同步增删的表 以上是一些基本配置,还有一些业务场景配置,大家可以参考开源社区文档: https://shardingsphere.apache.org/document/4.1.0/cn/overview/
总结
对于具体业务场景,我们首先是基于DDD的思想划分业务单元,最开始先做好垂直分库。接着是针对一些特定的业务增长量巨大的表,进行水平的分库处理,比如商品子域中的商品池表,订单子域中的订单表等等。
而在分表维度,业务初期,就要最好垂直分表的设计。比如商品池设计中,只需要存储关系信息,而商品详情的信息单独存储在一个底表之中。
作者:京东物流 赵勇萍
来源:京东云开发者社区