Python爬虫
百度百科是这样定义爬虫的:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗的解释:
打开一个网页,里面有网页内容吧,想象一下,有个工具,可以把网页上的内容获取下来,存到你想要的地方,这个工具就是我们今天的主角:爬虫。
打开浏览器(强烈建议谷歌浏览器),找到浏览器地址栏,然后在里敲网址https://music.163.com/,你会看到网页内容。
鼠标在页面上点击右键,然后点击查看网页源代码(view page source)。看到这些文字了吗?这才是网页本来的样子。
其实,所有的网页都是HTML+CSS+JavaScript代码,只不过浏览器将这些代码解析成了上面的网页,我们的小爬虫抓取的其实就是这些代码中的文本啦。
这不合理啊,难不成那些图片也是文本?
恭喜你,答对了。回到浏览器中有图的哪个tab页,鼠标右键,点击Inspect。会弹出一个面板,点击板左上角的箭头,点击虐狗图片,你会看到下面有红圈圈的地方,是图片的网络地址。图片可以通过该地址保存到本地哦。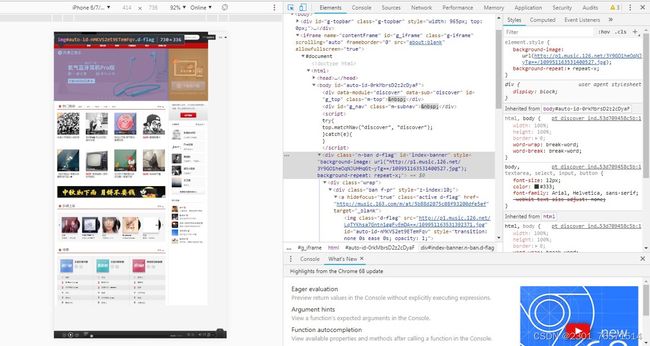
没错,我们的小爬虫抓取的正是网页中的数据,但是前提是你要知道你想要抓取什么数据,你的目标网站是什么,才可以把想法变成现实的哦。
说了这么多,学习Python爬虫还是需要一定的基础知识呢?
-
-
HTML
这个能够帮助你了解网页的结构,内容等。可以参考W3School的教程或者菜鸟教程。 -
Python
如果有编程基础的小伙伴儿,推荐看一个廖雪峰的Python教程就够了
没有编程基础的小伙伴,推荐看看视频教程(网易云课堂搜Python),然后再结合廖雪峰的教程,双管齐下。
其实知乎上总结的已经非常好了,我就不多唠叨了。知乎-如何系统的自学Python -
TCP/IP协议,HTTP协议
这些知识能够让你了解在网络请求和网络传输上的基本原理,了解就行,能够帮助今后写爬虫的时候理解爬虫的逻辑。
廖雪峰Python教程里也有简单介绍,可以参考:TCP/IP简介,HTTP协议
-