DDR4 硬件设计Note
1 DDR4概述
DDR4全称,DDR4-DRAM,与其他DDR系列DRAM一样,是当前电子系统架构中使用最为广泛的的RAM存储器。DRAM全称Dynamic Random Access Memory,翻译过来为动态随机读取存储器。
聊到DDR,大家都会联想到存储器,但是实际上DDR并不指代存储器,DDR实际是一种技术,全称Double Data Rate,翻译过来为双倍数据速率,只是这技术都广泛使用在DRAM上,所以人们习惯将DDR代指为存储器。那双倍速率指的是什么?我们可以简要说下,初代存储器在读写数据时,每次都在时钟信号从低变高或从高变低时,采样数据,在1个时钟周期,只能采样1个数。后续聪明的人类在时钟从低到高时,采样一个数据,时钟从高到低时,再采样1个数据,一个时钟周期,可以采样2个数据。所以读写速度比以前快了2倍。这种技术手段,就指的是DDR。
所以,概括下:DDR4-DRAM是第四代支持双倍数据读取,支持随机位置存取的静态存储器。
2 DDR4-DRAM的工作原理
2.1 DDR4信号类型
一颗DDR4芯片的内部功能框图如下:
 图2.1 MT40A1G8 DRAM芯片架构
图2.1 MT40A1G8 DRAM芯片架构
其引脚按照功能可以分为7类:前3类为电源、地、配置。
| Pin分类 |
名称 |
方向 |
功能描述 |
| 电源 |
VDD |
PI |
芯片主电源输入,1.2V |
| VDDQ |
PI |
DQ信号线电源,1.2 V |
|
| VPP |
PI |
DRAM 激活电源: 2.5V –0.125V/+0.250V. |
|
| VREFCA |
PI |
控制、命令、地址信号的参考电平 |
|
| 地 |
VSS |
- |
Ground. |
| VSSQ |
- |
DQ Ground. |
|
| 配置 |
ZQ |
- |
阻抗匹配(ODT)的校准参考,接240Ω电阻到地面VSSQ |
后4类为:控制信号、时钟信号、地址信号、数据信号。
| Pin分类 |
名称 |
方向 |
功能描述 |
| 控制信号 |
ALERT_n |
OUT |
这个信号允许DRAM向系统内存控制器指示特定的警报或事件已经发生。警报将包括命令/地址奇偶校验错误和CRC数据错误时启用这些功能的注册方式。 |
| TEN |
IN |
测试模式使能信号,高电平使能测试模式。正常运行的过程中,一定要拉低。 |
|
| RESET_n |
IN |
DDR复位信号。RESET_n为LOW时有效,RESET_n在正常操作时必须为HIGH。 |
|
| CKE |
IN |
时钟信号使能。通过此电平,可以使芯片进入低功耗模式 |
|
| ODT |
IN |
阻抗匹配使能 |
|
| CS_n |
IN |
DDR芯片使能,用于多个RANK时的RANK组选择。 |
|
| 命令信号 |
PAR |
IN |
命令/地址信号的奇偶校验使能,可通过寄存器禁用或者使能。 |
| ACT_n |
IN |
当ACT_n (along with CS_n)是LOW,输入引脚RAS_n/A16, CAS_n/A15,和WE_n/A14被视为行地址输入的ACTIVATE命令。当ACT_n为HIGH时(随CS_n LOW),输入引脚RAS_n/ A16, CAS_n/A15和WE_n/A14被视为使用RAS_n, CAS_n和WE_n信号的普通命令。 |
|
| RAS_n |
IN |
RAS_n/A16, CAS_n/A15, WE_n/A14(连同CS_n和ACT_n)定义要输入的命令和/或地址。 |
|
| CAS_n |
IN |
||
| WE_n |
IN |
||
| 时钟信号 |
CK_t |
IN |
差分时钟信号,由DDR Controller输出。 |
| CK_c |
IN |
||
| 地址信号 |
BA[1:0] |
IN |
Bank 地址输入。定义有效、READ、WRITE或PRECHARGE的Bank (在Bank 组中)命令被执行。 |
| BG[1:0] |
IN |
Bank组地址输入。定义有效、READ、WRITE或PRECHARGE的Bank 组命令被执行。 |
|
| A[17:0] |
IN |
地址信号输入。A10/AP、A12/BC_n、WE_n/A14、CAS_n/A15、RAS_n/A16有附加功能。A17连接是部分型号规范的。 |
|
| 数据信号 |
DQ |
I/O |
DQ表示DQ[3:0],DQ[7:0],和DQ[15:0]分别为x4、x8和x16配置。DQ0, DQ1, DQ2和DQ3的任何一个或全部都可以在测试期间通过模式寄存器设置MR[4] A[4] = HIGH来监视内部VREF电平,当使能时,训练次数改变。在此模式下,RTT值需要设置为High-Z。此测量是为了验证目的,而不是外部电压供应引脚。 |
| DM_n, UDM_n LDM_n |
IN |
DM_n是写入数据的输入掩码信号。在写访问期间,当DM与输入数据采样LOW一致时,输入数据被屏蔽。DM在DQS的两边采样。x4配置不支持DM。UDM_n和LDM_n引脚在x16配置中使用:UDM_n与DQ[15:8]相关; LDM_n与DQ[7:0]相关。DM、DBI和TDQS功能通过模式寄存器设置使能。请参阅数据掩码部分。 |
|
| DQS_t, UDQS_t, LDQS_t, |
I/O |
数据选通信号,用于READ作为输出,用于WRITE作为输入。读时,与DQ的边沿对齐;写时,与DQ的中心对齐(注:读时,DQS与DQ信号同相位发出;写时,DQS与DQ信号相位相差1/4T)。对于x16, LDQS对应于DQ上的数据[7:0];UDQS对应DQ上的数据[15:8]。对于x4和x8配置,DQS分别对应DQ[3:0]和DQ[7:0]上的数据。DDR4 SDRAM只支持差分数据选通,不支持单端数据选通。 |
|
| DQS_c, UDQS_c, LDQS_c |
I/O |
2.2 DDR4的时分复用寻址方式
DDR4中最重要的信号就是地址信号和数据信号。以X16架构DDR4芯片为例,有20根地址线(17根Address、2根BA、1根BG),16根数据线。假如我们用20根地址线,16根数据线,设计一款DDR,我们能设计出的DDR寻址容量有多大?
以最简单的单线8421编码寻址的方式,我们知道20根地址线(不考虑连续读写控制信号)的寻址空间为2^20,16根数据线可以1次传输16位数据,我们能很容易计算出,如果按照单线8421编码寻址方式,DDR芯片的最大存储容量为:
但是事实上,该DDR最大容量可以做到1GB,比传统的单线编码寻址容量大了整整512倍,它是如何做到的呢?答案很简单,分时复用。
我们把DDR存储空间可以设计成如下样式:首先将存储空间分成2个大块,分别为BANK GROUP0和BANK GROUP1,再用1根地址线(还剩19根),命名为BG,进行编码。若BG拉高选择BANK GROUP0,拉低选择BANK GROUP1。(当然也可以划分成4个大块,用2根线进行编码)

再将1个BANK GROUP区域分成4个BANK小区域,分别命名为BANK0、BANK1、BANK2、BANK3。然后我们挑出2根地址线(还剩余17根)命名为BA0和BA1,为4个小BANK进行地址编码。

此时,我们将DDR内存颗粒划分成了2个BANK GROUP,每个BANK GROUP又分成了4个BANK,共8个BANK区域,分配了3根地址线,分别命名为BG0,BA0,BA1。然后我们还剩余17根信号线,每个BANK又该怎么设计呢?这时候,就要用到分时复用的设计理念了。
剩下的17根线,第一次用来表示行地址,第二次用来表示列地址。原本传输1次地址,就传输1次数据,寻址范围最多16KB(不要读写信号)。现在修改为传输2次地址,在传输1次数据,寻址范围最多被扩展为2GB。虽然数据传输速度降低了一半,但是存储空间被扩展了很多倍。这就是改善空间。所以,剩下的17根地址线,留1根用来表示传输地址是否为行地址。
在第1次传输时,行地址选择使能,剩下16根地址线,可以表示行地址范围,可以轻松算出行地址范围为2^16=65536个=64K个。在第2次传输时,行地址选择禁用,剩下16根地址线,留10根列地址线表示列地址范围,可以轻松表示的列地址范围为2^10=1024个=1K个,剩下6根用来表示读写状态/刷新状态/行使能、等等复用功能。
这样,我们可以把1个BANK划分成67108864个=64M个地址编号。如下所示:
在每个地址空间中,我们16根数据线全部用起来,一次存储16位数据。

所以1个BANK可以分成65536行,每行1024列,每个存储单元16bit。每行可以存储1024*16bit=2048bit=2Kb。每行的存储的容量,称为Page Size。
单个BANK共65536行,所以每个BANK存储容量为65536*2KB=128MB。单个BANK
GROUP共4个BANK,每个BANK GROUP存储容量为512MB。
单个DDR4芯片有2个BANK GROUP,故单个DDR4芯片的存储容量为1024MB=1GB。至此,20根地址线和16根数据线全部分配完成,用正向设计的思维方式,为大家讲解了DDR4的存储原理以及接口定义和寻址方式。
3 DDR4之内存通道(channel)和内存列(rank)

3.1 内存通道(channel)
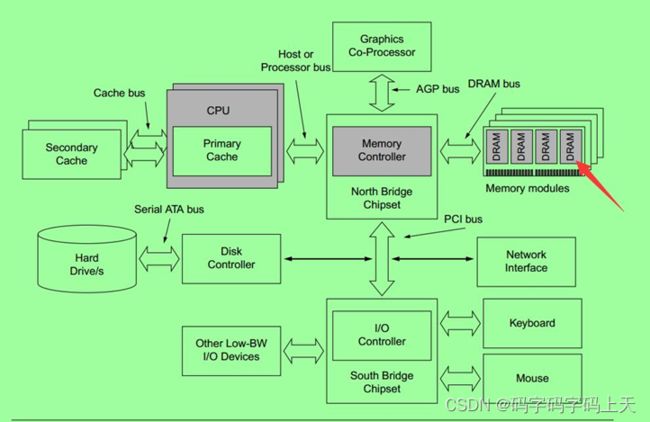
在数电和计算机硬件领域,多通道内存架构是一种技术。内存和CPU上的内存控制器,通过总线来和计算机的其余部分进行通信。在内存和内存控制器之间增加通信通道,可以加快数据传输速率。内存控制器通常有一个通道、两个通道(双通道)、四通道(四通道)、六通道和八通道等等。六通道和八通道架构通常是为服务器设计的。从理论上讲,多通道数据传输速率可以成倍的增加(多通道速率 = 单通道速率 * 通道数量)。
TweakTown使用SiSoftware Sandra执行的基准测试显示,与双通道配置相比,四通道配置的性能提高了约 70%。但TweakTown对同一主题进行其他测试显示,性能并没有显着差异。因此得出的结论是,并不是所有基准软件都能利用多通道内存提供的并行性。
 内存模块分别使用单通道和双通道和CPU通信
内存模块分别使用单通道和双通道和CPU通信
3.2 内存列(rank)
内存rank是一组连接到同一个chip select的DRAM芯片,可以同时访问它们。所有 DRAM 芯片共享所有命令和控制信号,并且只有每个rank的芯片选择引脚是独立的。

内存rank是由内存行业标准组织JEDEC创建和定义的。在DDR、DDR2或DDR3内存模块上,每个rank都有一个64位宽的数据总线(在支持ECC的DIMM上为64+8==72位宽)。物理DRAM的数量取决于它们各自的宽度。例如,一列×8(8位宽)DRAM将由8个物理芯片组成(如果支持 ECC,则为9个),但一列×4(4位宽)DRAM将由16个物理芯片(如果支持 ECC,则为18个)。
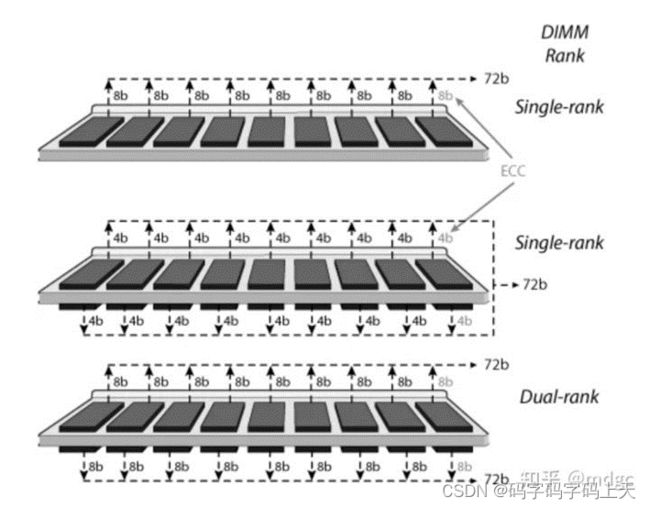 单侧单rank,双侧单rank,双侧双rank
单侧单rank,双侧单rank,双侧双rank
多个rank可以在单个 DIMM 上共存,现代 DIMM 可以由一列(单列)、两列(双列)、四列(四列)或八列(八列)组成。
增加每个 DIMM 的rank数主要是为了增加每个channel的内存密度。通道中太多的rank会导致超载并降低通道的速度。此外,某些内存控制器具有支持的最大rank数。命令/地址 (CA) 总线上的 DRAM 负载可以通过使用注册内存来减少。

3.3 关于多rank的内存性能,需要考虑多种影响
多rank允许每个rank中有多个打开的 DRAM pages(row)(通常每个rank有8个row)。这增加了命中已经打开的row地址的可能性。性能提升高度依赖于应用程序和内存控制器利用打开row的能力。
多rank在数据总线上具有更高的负载(在无缓冲DIMM CA总线也一样)。因此,如果一个通道中连接了多个dual-rank DIMM,速度可能会降低。
受限于某些限制,可以独立访问rank,但不能同时访问,因为数据线仍然在通道上的列之间共享。例如,控制器可以在等待从一个rank中读取的数据时,将写入数据发送到一个rank。当写入数据从数据总线消费时,另一rank可以执行与读取相关的操作,例如激活一行或将数据从内部传输到输出驱动器。一旦 CA 总线没有了来自前一次读取的噪声,DRAM 就可以驱动读取数据。像这样控制交错访问是由内存控制器完成的。
CPU可以访问一个rank,而另一个rank可以进行刷新周期(准备好被访问)。刷新周期的屏蔽和流水线通常会为CPU 密集型应用程序带来更好的性能,因为它减少了内存响应时间。但是访问不同rank在某些情况下会导致流水线停滞,从而降低性能。因此,多级rank的整体影响因应用程序而异。


4 DDR之T拓扑和Fly-by拓扑
T型拓扑及Fly_by拓扑结构,这两种拓扑结构应用最多的应该是在DDR3里面,说到这里,小编又想开始聊聊DDR3的设计了,我想很多人都比较有兴趣。因为DDR3的设计还是比较复杂,而且应用也比较广泛,如下图是常见的T型及Fly_by型的拓扑应用。

4.1 T拓扑(树形拓扑)的定义及其注意事项
T拓扑又叫树形拓扑,连接模式大概如下所示:

从上面的图中,我们可以看出T拓扑本身就是一堆的阻抗不连续,从发送端到接收端一路上分岔路太多,对于路痴而言,是很容易迷失在人生旅途上的;对于信号来讲,同样如此,T拓扑的的分支太多,阻抗不匹配的情况一路都在,每个部分线长对于接收端的波形有什么影响呢,layout的时候怎么处理各个分段线长之间的关系比较好?
首先关注主干L1的线长,一般我们处理T拓扑等长的时候,都会有这样的要求,等长在主干部分完成,不要在分支的地方绕线。原因之一是因为对绕线空间的考虑,主干绕线一次性搞定,分支处理每次搞定一个,一点都不经济适用,对不对!还有另外一个原因,就是主干线的长度对于接收端波形的影响不大,只要匹配好驱动端和L1线段之间的阻抗,那么驱动端与L1线段的之间的反射就不会反馈到驱动端,更加也就不会作用到接收端的波形上了,L1段线长变化主要影响由线长引起的高频分量的损耗,使上升沿变缓,在做好了端接的情况下,对于信号判定方面没有其他的影响,如下图所示为扫描L1段的波形。

至于分支L2的线长,波形和主干的结果是一致的,因为这个分支的反射波形在并联端接的地方被吸收了,同样不会影响到接收端的波形。所以线长对于接收端的波形除了上升沿变缓,也没有其他的影响,如下图所示为扫描L2段的波形。

既然分支L2线长变化对于信号的影响不大,那么分支L3线长的变化对于接收端波形是否也是这样?其实不然,L2的反射波形会被端接吸收,但是L3的反射波形却没有端接匹配,所以反射波形会反馈到接收端,因此L3的线长对于接收端的波形是有影响的。线长越短,波形越好。因为分支L3长度比较短的话,从接收端过来的反射波会淹没在上升时间中,一旦分支长度变长,反射波发生影响,就可能对接收端产生台阶回沟的效果,甚至会造成误判断的结果,有图有真相,如下图所示为扫描L3段的波形。
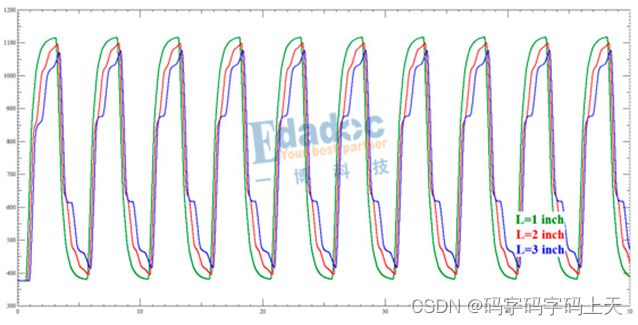
注:以上波形都是在200MHz时钟频率下仿真的,如频率更高波形会更差。
所以对于我们处理T拓扑的话,要注意让分支L3尽量短,其他的线长也是要尽量做到短,做不到的情况下,可以考虑加长主干L1线长和分支L2线长,这种情况下,上升沿的损耗是不可避免的。
4.2 Fly_by拓扑结构及其端接详解
相比T拓扑,fly-by在传输较高速率信号时更占优势一些,当然fly-by也并不就是完美的,它自身也存在很多缺陷,例如使用fly-by,负载之间有延时差,导致信号不能同时到达接收端。为解决这个问题,DDR3引入了read and write leveling,但是fly-by由于分支结构的存在,通道本身就存在一些缺点。例如:通道阻抗不连续;容性突变对时序的影响等等。下面就来详细的分析一下。
4.2.1分支处阻抗的不连续程度受stub长度影响
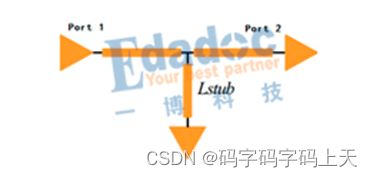
信号通道中只要有分叉就会存在阻抗的不连续,fly-by结构处处是分叉,阻抗不连续问题就很突出,到底这种阻抗不连续到了什么程度呢?下面就通过仿真实例来看看。在仿真软件中搭建如下拓扑结构,扫描通道S参数,再利用S参数反推出各个节点的阻抗。

起初,我们将Stub长度都设定为100mil,扫描通道,得到通道的阻抗曲线如下:

由上图可知,通道中有四次阻抗跌落,这些跌落分别对应该传输线的四个分支。Stub的长度与阻抗跌落的程度是否呈正相关呢?为简化分析过程,我们只允许通道中有一个Stub,扫描Stub长度,看看阻抗的变化趋势。
仿真的结果如下图所示:

上图的结构是不是很容易让我们联想到过孔的Stub,没错,传输线上的Stub和过孔的Stub效应差不多,只不过我们在仿真过孔的时候,一般会选择三维建模,而且,过孔还考虑了焊盘的效应。
由图4的三个波形曲线可知,Stub越长,阻抗掉的越低。为什么会这样?传输线瞬态阻抗计算公式为Z=√(L/C)。就是信号感知的电感与电容的比值再开根号。因为分叉处的传输线与主线之间是并联关系,Stub就像并联在传输线上的小电容, Stub越长,电容量越大,阻抗也就越低。当然,fly-by结构的分支较多,每个分叉处都存在阻抗不连续,信号会在Stub之间来回反射,如图所示,所以分析起来比较复杂。

像这种复杂的反射,只能借助仿真软件去评估它对信号的影响程度。为了解决这个问题,工程上一般会选择在主通道末端接上上拉电阻。但是,末端端接只能解决末端反射问题,对于分支上的反射是不能完全消除的。
4.2.2 Stub电容效应对传输延时的影响
我们知道,连接在通道中途的短桩线和主通道是并联关系,而这些短桩线本身是有电容的,这就意味着这些小桩线相当于一个个的小电容并联在传输线中。由电容的频率响应曲线可知,电容对信号中的高频分量的阻抗是很低的,也就是说信号中的高频分量会因为通道中并联的小电容被过滤掉。高频分量的损失会导致信号的上升时间的变缓。到底是不是这样呢?
搭建如下拓扑,下图两个通道的长度是完全一致的。驱动端阻抗与传输线阻抗相匹配,在驱动端加载一个上升沿为1ns的激励和我们推测的一样,连线中途的Stub会导致信号上升沿出现延迟的现象。因为: TD_0=Len√LC,信号在传输的过程中,每遇到一个Stub就会导致一个小小的延迟,多次累加后就会出现一个较大的延迟。这对高速信号来说,是不可忽略的影响。
工程中会通过线宽补偿来减小这种容性突变,效果究竟怎么样呢,还是通过仿真来看一下。如上拓扑结构,调高Stub以及桩线之间走线的阻抗,看看上升沿的变化。

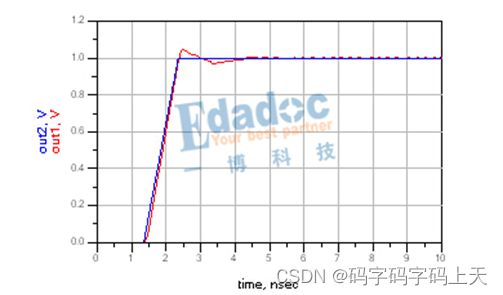
由上图可知,Stub以及Stub之间的走线阻抗拉高之后,上升沿延迟现象得到改善。容性突变导致的负反射也得到一定的补偿。细心读者可能会发现,补偿之后,反射导致的过冲问题又显现出来,这可真是“按下葫芦浮起瓢”。怎么办?过冲问题只有交给端接电阻去解决了。
说了这么多,看来要想把fly-by结构对信号的影响说清楚还真是没那么容易。对于这种拓扑结构,常规的串扰控制自是不必多说的,另外,还需要牢牢记住的就是:Stub能短就尽量做短些吧;在负载很多的情况下,做一下阻抗补偿还是很有必要的。
4.3 T型及Fly_by拓扑之应用总结
通常来讲,谈到DDR3的拓扑结构(这里主要是针对时钟或地址控制信号),大家马上就会想到T型或者Fly_by结构,但什么时候使用T型或者Fly_by 型呢?答案是:it depends!(如果大家有经常参加老外的培训,这应该是个用得最多的回答了,可见老外也是比较狡猾的)。这个问题确实是没法确切回答的,因为要看情况,小编在此也来试着把这个问题回答得更具体点。
首先,从颗粒数目的情况来考虑。一般在4个或者4个以下的拓扑,使用T型 或者Fly_by型都没有太大问题,主要看个人喜好了,如果板子布线空间足够的话,还是建议使用T型拓扑,信号质量也不赖,后期调试也较简单;如果颗粒数 目超过4个,那么果断使用Fly_by拓扑,不要问我为什么,等你去绕等长的时候你就知道为什么要用Fly_by拓扑了。
其次,从布线空间来考虑。板内布线空间较充裕,有足够的空间绕等长,可以使用T型拓扑,如果板内布线空间较紧张,没有足够空间绕等长,那么还是使用Fly_by拓扑。
再次,从信号速率来考虑。一般T型拓扑频率超过1GHz信号质量就会出现大幅的下降,所以此时应考虑使用fly_by拓扑结构。
当然,使用何种拓扑并不是单一情况的考虑,而是综合的一个考虑,就像前面说到的需要综合考虑颗粒数目、板内布线空间、信号速率以及个人喜好(或者对各拓扑的熟悉程度)等。
下面来简单总结下T型拓扑和Fly_by拓扑的优缺点以及使用注意事项。
T型拓扑结构的特点是主控到每个颗粒的长度基本一致,也就是说每个颗粒的信号质量都差不多;缺点就是绕等长时需要更多的布线空间,所以不适合较多颗粒数目的 情况,其次是需要同等地位的分支完全对称(包括长度及阻抗等),如果不对称那么信号质量的影响比较大。所以我们在使用T型拓扑的时候应该注意预留足够的空间来绕线,另外还需要注意同一个节点分出去的分支(也就是前面说的同等地位的分支)必须对称。
这个在前面的T型拓扑里面已经有仿真结果了,在此就不在赘述。
Fly_by 拓扑结构的优点是布线相对简单,其中数据组不需要和时钟信号绕等长,这样就可以节省较多的布线空间,同时也可以支持更高的信号速率;缺点就是信号到达每片颗粒的时间不一致,带来了一定的skew,这个skew需要一定的技术来弥补。同时在前面的文章中也有提到过,对Fly_by拓扑影响最大的是主干到颗粒 的那段Stub线,所以必须严格控制stub的长度(时钟信号100mil左右,地址、控制等信号150mil左右),这个长度当然是越短越好。至于颗粒间的长度到底影响有多大,前面的文章提问也问到过,请看下面的不同位置及长度对比下的信号眼图。

可见颗粒与颗粒间的长度影响也不及stub的影响大,但太长了对信号还是有一定的影响,所以根据板内空间及信号质量的综合考虑,我们建议颗粒与颗粒的长度控制在1inch内较好。
另外不管是T型拓扑还是Fly_by拓扑,还需要考虑合理的端接,常用的端接方式是T型拓扑在第一个分支节点处上拉50欧姆或其他端接电阻到Vtt,而 Fly_by则是在最后一个颗粒处上拉50欧姆或其他端接电阻到Vtt;除了端接电阻,其实当颗粒数目较多时,都可以将两种拓扑的主干线路阻抗降低到40 欧姆左右,这样有利于提升信号的质量
4.4 Write leveling功能与Fly_by拓扑
Write leveling功能和Fly_by拓扑密不可分。Fly_by拓扑主要应用于时钟、地址、命令和控制信号,该拓扑可以有效的减少stub的数量和他们的长度,但是却会导致时钟和Strobe信号在每个芯片上的飞行时间偏移,这使得控制器(FPGA或者CPU)很难保持tDQSS、tDSS 和tDSH这些参数满足时序规格。因此write leveling应运而生,这也是为什么在DDR3里面使用fly_by结构后数据组可以不用和时钟信号去绕等长的原因,数据信号组与组之间也不用去绕等长,而在DDR2里面数据组还是需要和时钟有较宽松的等长要求的。DDR3控制器调用Write leveling功能时,需要DDR3 SDRAM颗粒的反馈来调整DQS与CK之间的相位关系。

Write leveling 是一个完全自动的过程。控制器(CPU或FPGA)不停的发送不同时延的DQS信号,DDR3 SDRAM颗粒在DQS-DQS#的上升沿采样CK的状态,并通过DQ线反馈给DDR3控制器。控制器端反复的调整DQS-DQS#的延时,直到控制器端检测到DQ 线上0到1 的跳变(说明tDQSS参数得到了满足),控制器就锁住此时的延时值,此时便完成了一个Write leveling过程;同时在Leveling过程中,DQS-DQS#从控制器端输出,所以在DDR3 SDRAM 侧必须进行端接;同理,DQ线由DDR3 SDRAM颗粒侧输出,在控制器端必须进行端接。
需要注意的是,并不是所有的DDR3控制器都支持write leveling功能,所以也意味着不能使用Fly_by拓扑结构,通常这样的主控芯片会有类似以下的描述:
The following option DDR3 features are not supported:
Read and Write leveling
5 DDR的硬件设计
作为硬件工程师,我们通常收到需求是:该产品内存配置为DDR4,容量8Gb(1GB=8Gb)。而我们通常需要把这个“简陋”的需求,转化为具体的电路,该如何去实现呢?其实,很简单。DDR4的硬件设计过程可以总结为:为某个平台搭配一颗DDR内存颗粒,并保证平台与DDR内存颗粒均能正常工作。
所以可以分为2部分,如何为平台选型1颗DDR内存颗粒?如何保证DDR相关电路能正常工作?
5.1 DDR内存颗粒选型
目前很多芯片都会把CPU与外围控制电路(例如:FLASH控制电路,DDR控制电路,USB控制电路)集成到1颗芯片中,像高通MDM8909,类似这样的芯片,我们称为“平台芯片”。平台芯片中DDR控制电路,我们称为“DDR Controller”,翻译过来为:DDR控制器。
为DDR控制器搭配它能控制的DDR内存颗粒,你就必须先了解下:DDR控制器需要什么样的内存颗粒?
硬件设计第一步:查阅平台芯片规格书中,关于DDR控制器部分的描述。
It has 16/32 bits DDR3L/4 up to 2400 MT/s, parallel NAND, serial NOR interfaces.

所以我们了解到了:该平台芯片,支持DDR3L或者DDR4内存颗粒,数据位宽为16位或者32位,最高数据传输速度为2400MT/s,即频率为1200MHz(DDR是双边沿数据传输,1个时钟周期传输2次数据,1s传输了2400M次,即意味着1s时钟变化了1200次,即频率为1200MHz)。结合产品需求:容量8Gb,那我们基本可以锁定DDR的详细规格了。
在正式选型之前,还要引入1个概念“RANK”。我们知道,DDR即支持多个内存颗粒扩展容量,又支持多个内存颗粒扩展数据位宽。例如,我们的DDR控制器支持32位数据位宽,那我们可以用8个4位DDR,或者4个8位DDR,或者2个16位DDR,或者1个32位DDR进行数据位扩展。假如我们用8个4位DDR颗粒进行设计,我们的RANK数量就是8,我们戏称为“8-RANK设计”,当然实际生活中,我们肯定不会这么蠢,拿8个4位DDR去扩展32位。
所以,在确定我们的RANK数量后,需求被锁定了。
容量设定为8Gb,类型为DDR4,数据宽度为32位,最高频率为1200MHz。由于目前大部分DDR内存颗粒最高支持16位数据宽度,所以RANK数量为2,即我们说的Dual-RANK设计。
根据这个需求,可以在DDR官网上去寻找合适的“DDR芯片”了。例如在镁光官网产品页,选定DRR4-SDRAM,选定8Gb,DDR4。

网页会为你推荐很多型号。像数据位宽是8位的,可以直接跳过。

数据位宽为16位,频率为1200Mhz(2400MT/s)的,仍然有很多。这时候就是考验硬件工程师职业素养的时候了,我们不仅要考虑硬件性能,还要考虑下物料成本,物料采购周期。考虑成本,就尽量不要有“过设计”的地方,所以速率为3200MT/s的器件排除掉。如果我们是消费类商规产品,所以温度范围选择较窄的商业级器件,其次,为了增进你和采购的感情,千万不要选择停产的物料。千万不要选择停产的物料。千万不要选择停产的物料。

这样下来,我们选型基本就锁定到MT40A512M16JY-083E了,用量为1片。
5.2 DDR的硬件电路搭建
设计逻辑器件电路,就要有逻辑思维,最简单的逻辑思维,就是分组。所以,先了解DDR控制器的硬件接口。控制器硬件PIN脚可以分为电源组,配置组,控制组,时钟组,地址组,数据组。
电源组和配置组接口如下,供电,接电阻就可以完成,1.2V的供电,尽可能要平稳,此处忽略。ZQ电阻是用来校准ODT阻抗的,我们后面会讲到。
控制信号中,需要注意CS0和CS1,2个片选信号可以用来进行多RANK内存容量扩展的,说明DDR控制器,最多支持2组RANK。每组RANK分配单独的片选信号。我们此处设计2个16位芯片组成1个RANK,即CS0要同时接在目前选的2个DDR颗粒的CS上,组成菊花链。其余控制信号一般无时序要求,能传递逻辑即可。
地址信号通常要参考时钟信号来进行寻址,所以地址信号要严格与时钟信号保持长度一致,来保证所有地址位在采样的时候同时到达。因为同一块单板上,每根线上电子的传递速度是一样的,所以信号线长度越长,信号越晚到达,信号线长度越短,信号越早到达,地址采样的时候,是有时间期限的,所以,所有的地址信号必须保证在采样时间范围内全部到达,因此要求地址线相对时钟线进行长度控制。前面一节我们讲了内存寻址原理,先用BG信号选择BANK GROUP,再用BA信号进行BANK选择,再用A[0:16]进行选择,再用A[0:16]进行列选择,完成寻址。可以看到,Address信号在进行选择和列选择时,BG和BA信号都是保持的,所以BG信号和BA信号的等长要求会相对略宽。
DDR控制器有2根BG信号,2根BA信号,17根Address信号,同一个RANK有2个DDR颗粒,每个DDR颗粒有1根BG信号,2根BA信号,17根Address信号,前面CS0同时连接了2个DDR颗粒的片选,所以寻址时两颗DDR会被同时片选,那么DDR控制器如何区分开寻址其中1颗DDR颗粒呢?硬件又该怎么连接?其实很简单,根据上节讲的内存寻址原理,我们知道每个DDR颗粒有2个BANK GROUP(1根BG信号),4个BANK(2根BA信号),与CS扩展容量的原理一致,我们把BG0接在DDR颗粒1上,BG0拉高拉低,我们可以寻址CHIP1的8个BANK。BG1接在DDR颗粒2上,BG1拉高拉低,我们可以寻址CHIP1的8个BANK。BA、ADDR进行菊花链连接,同时接在2颗DDR芯片上。
接下来,我们看看数据信号的链接,数据信号是内部分组的,由于DDR数据信号传输的时候双边沿数据传输,而且如果所有信号都参考时钟去做等长,会导致等长控制非常困难,增加DDR的设计难度,所以聪明的人类想出了另外一招,额外增加数据选通信号来作为数据信号的采样时钟,每8位信号,参考一组差分。所以我们很轻易可以看出DDR控制器有4组DQS差分信号,32根数据信号。我们的RANK中有2个DDR颗粒,每个颗粒有2组DQS差分信号,16根数据信号。所以
控制器的DQS[0:1]连接DDR CHIP0的DQS[0:1],
控制器的DQ[0:15]连接DDR CHIP0的DQ[0:15]。
控制器的DQS[2:3]连接DDR CHIP1的DQS[0:1],
控制器的DQ[16:31]连接DDR CHIP1的DQ[0:15]。
至此所有信号连接完成。
接下来是阻抗匹配,地址信号都需要外部加49欧姆匹配电阻到电源或者GND,数据信号,则不需要。因为DDR内部集成ODT功能,只需要通过配置,即可完成每组数据线的阻抗匹配。
单rank DIMM需要一对时钟;双 rank DIMM需要两个时钟对。
确保MAPAR_OUT和MAPAR_ERR信号连接正确:
•MAPAR_OUT (from控制器)=> PAR(在内存/DRAM)
•ALERT_n (from the DIMM/DRAM) => MAPAR_ERR(在控制器
确保在MALERT /MAPAR_ERR pin上存在一个50 Ω到100 Ω上拉电阻连接1.2 V。焊接在板或RDIMM上分离的DRAM芯片要求使用50~100 Ω上拉电阻。对于UDIMM/SODIMM不需要on board上拉电阻,因为UDIMM/SODIMM 的ALERT引脚上已经存在50Ω终端电阻。
•确保MDIC0通过162Ω精度1%电阻接地。
•确保MDIC1通过162Ω精度1%电阻连 接到DDR电源。
6 DDR4 PCB设计要点介绍
6.1 DDR4信号分组
DDR4新增了许多功能,数据信号,地址信号,包括电源都有更新,分组的时候我们需要弄清楚这些新增的信号应该归到哪一类,方便后续的布线,等长处理等。
6.2 DDR4布局要求
DDR4布局的基本要求如下:
- 地址/命令/控制和时钟组线布局布线需使用Fly-by的拓扑结构,不可使用T型,拓扑过孔到管脚的长度尽量短,长度在150mil左右;Fly-by拓扑中的走线应该从芯片0到芯片n,并且可以按照最方便电路板设计的顺序进行。
- VTT上拉电阻放置在相应网络的末端,即靠近最后一个DDR4颗粒的位置放置;注意VTT上拉电阻到DDR4颗粒的走线越短越好,走线长度小于500mil;每个VTT上拉电阻对应放置一个VTT的滤波电容(最多两个电阻共用一个电容)。
- CPU端和DDR4颗粒端,每个引脚对应一个滤波电容,滤波电容尽可能靠近引脚放置。线短而粗,回路尽量短;CPU和颗粒周边均匀摆放一些储能电容,DDR4颗粒每片至少有一个储能电容
 图6.1 DDR4布局标题
图6.1 DDR4布局标题
6.3 DDR4布线要求
DDR4布线的基本要求如下:
1.单端信号:数据总线控制50ohm阻抗,地址/控制/命令信号控制40ohm阻抗;DQS差分线控制100ohm阻抗;时钟差分线控制80ohm阻抗;阻抗误差控制10%内。
2.确保数据/地址/命令信号的最大引入走线长度不超过7英寸(7000mil)。
3.确保在参考平面边缘附近的走线至少保持参考平面边缘有30-40mil的间距。
4.所有的内层走线都要求夹在两个参考平面之间,即相邻层不要有信号层,这样可以避免串扰和跨分割,走线到平面的边缘必须保持4mil以上的间距;所有DDR4信号走线都不要跨越平面分割或间隙。
5.除了从焊盘到过孔之间的短线外,所有的走线都必须走带状线,即内层走线。
6.允许不超过1/2的走线宽度通过antipad。
7.Fly_by拓扑要求stub走线很短,当stub走线相对于信号边沿变化率很短时,stub支线和负载呈容性。负载引入的电容,实际被分摊到了走线上,所以造成走线的单位电容增加,从而降低了走线的有效阻抗。所以在设计中,我们应该将负载部分的走线设计为较高阻抗(作阻抗补偿),最直接有效的方式就是减小支线线宽。经过负载电容的平均后,负载部分的走线才会和主线阻抗保持一致,从而达到阻抗连续,降低反射的效果。如图6.2所示。
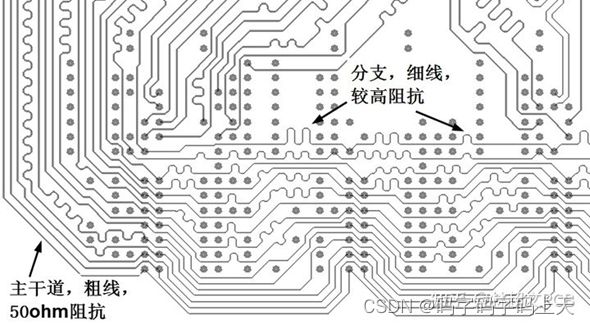 图6.2 容性负载补偿
图6.2 容性负载补偿
8.数据线参考面优先两边都是GND,接受一边地,一边自身电源,但是到GND平面的距离要比到电源平面的距离要近;对于地址线,控制信号,CLK来说,参考面首选GND和VDD,也可以选GND和GND。如图6.3所示。
 图6.3 数据线和地址线参考面
图6.3 数据线和地址线参考面
9.所有的DQ线必须同组同层,地址线是否同层不做要求。
10.从存储器控制器到任何给定DDR4芯片的时钟信号走线长度应该大于其相应的DQS信号走线长度。
6.4 DDR4走线线宽和线间距
DDR4走线线宽和线间距要求如下:
1.线宽和线间距必须满足阻抗控制,即单端线50ohm或40ohm,差分线100ohm。
选项1(更宽的线宽-更低的走线阻抗):
•单端阻抗= 40 Ω。较低的阻抗允许走线以较少的串扰更靠近。
•间距>= 2-3x距离从信号到相邻的接地平面
选项2(更窄的线宽-更高的走线阻抗):
•单端阻抗= 50 Ω
•间距>= 2-3x距离从信号到相邻的接地平面
2.ZQ属于模拟信号,布线尽可能短,并且阻抗越低越好,所以尽可能的把线走宽一点,建议3倍50ohm阻抗控制的线宽;
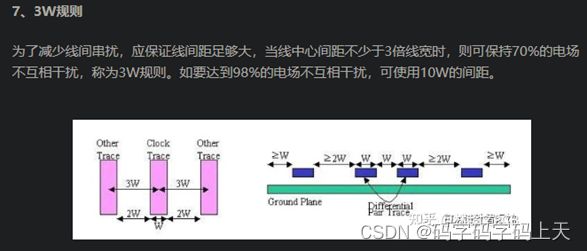
3.DQ和DBI数据线,组内要求满足3W间距,与其他组外信号之间保持至少4W;
4.DQS和CLK距离其他信号间距做到5W以上;
5.确保从一个差分对到任何其他信号走线(包括其他差分对)的间距至少为25mil。
6.在过孔比较密集的BGA区域,同组内的数据线,地址线的间距可以缩小到2W,但是要求这样的走线尽可能的短,并且尽可能的走直线;
7.如果空间允许,所有的信号线走线之间的间距尽可能的保证均匀美观;
8.内存信号与其他非内存信号之间应该保证4倍的介质层高的距离。
DDR4部分布线如图6.4所示。
 图6.4 DDR4布线
图6.4 DDR4布线
插入:
6.5 DDR4等长要求
DDR4等长要求如下:
(1)数据走线尽量短,不要超过2000mil,分组做等长,组内等长参考DQS,误差范围控制在+/-5mil;
(2)地址线、控制线、时钟线作为一组等长,组内等长参考CLK,误差范围控制在+/-10mil;
(3)DQS、时钟差分线队内误差范围控制在+/-5mil;
(4)RESET和ALERT不需要做等长控制;
(5)信号实际长度应当包括零件管脚的长度,尽量取得零件管脚长度,并导入软件中;
(6)因有些IC内核设计比较特别,按新品设计指导书或说明按参考板做,特别是Intel,AMD的芯片,请特别留意芯片手册要求;
DDR4等长规则设置如图6.5,6.6所示。
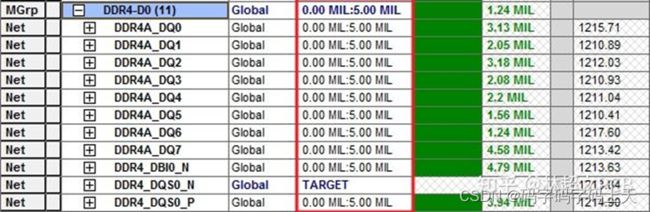 图6.5 所示 数据线等长规则
图6.5 所示 数据线等长规则
 图6.6 地址线等长规则设置
图6.6 地址线等长规则设置
6.6 DDR4电源处理
(1)VDD(1.2V)电源是DDR4的核心电源,其引脚分布比较散,且电流相对会比较大,需要在电源平面分配一个区域给VDD(1.2V);VDD的容差要求是5%,详细在JEDEC里有叙述。通过电源层的平面电容和专用的一定数量的去耦电容,可以做到电容完整性。1.2V电源设计如图6.7所示。
 图6.7 DDR4 1.2V电源平面
图6.7 DDR4 1.2V电源平面
(2)VTT(0.6V)电源,它不仅有严格的容差性,而且还有很大的瞬间电流;可以通过增加去耦电容来实现它的目标阻抗;由于VTT是集中在上拉电阻处,不是很分散,且对电流有一定的要求,在处理VTT电源时,一般是在元件面同层通过铺铜直接连接,铜皮要有一定宽度(120mil)。如图6.8所示。
 图6.8 VTT电源处理
图6.8 VTT电源处理
(3)VREF(0.6V)VREF要求更加严格的容差性,但是它承载的电流比较小。它不需要非常宽的走线,且通过一两个去耦电容就可以达到目标阻抗的要求。因其相对比较独立,电流也不大,布线处理时建议用与器件同层的铜皮或走线直接连接,无须再电源平面层为其分配电源。注意铺铜或走线时,要先经过电容再接到芯片的电源引脚,不要从分压电阻那里直接接到芯片的电源引脚。如图6.9所示。
 图6.9 VTEF电源处理
图6.9 VTEF电源处理
VPP(2.5V)内存的激活供电,容差相对宽松,最小2.375V,最大2.75V。电流也不是很大,一般走根粗线或者画块小铜皮即可,如图6.10所示。
 图6.10 VPP电源处理
图6.10 VPP电源处理
6.7 DDR3四片fly-by拓扑Fanout设计示例
Fanout的难点在于地址线的扇出,扇出的结果要保证四片DDR3之间地址线的互连能够满足Flyby的传输结构。而数据不存在拓扑结果的问题,所以数据的扇出相对简单。
我们可以将一个DDR芯片进行整体的布局布线,然后将其建立一个复用模块应用到其他的3片ddr芯片上,这样可以节约设计时间,单片DDR的整体扇出效果,如图6.11所示
 图6.11 单片DDR的扇出效果
图6.11 单片DDR的扇出效果
扇出之后就可以在ddr3芯片之间进行互连建立flyby拓扑结构,常规ddr3芯片之间地址线的互连需要用到两个内层(左右两边,一边一层),其中一层的互连效果如图6.12所示。
 图6.12 地址线的扇出效果
图6.12 地址线的扇出效果
最终内存的信号是通过第一片DDR连到CPU,以时钟信号为例,如图6.13所示。
 图6.13 信号从第一片DDR连到CPU
图6.13 信号从第一片DDR连到CPU
扇出和拓扑结构建立好之后就可以在CPU和DDR芯片之间进行数据线和地址线的互连了,由于这部分只是进行点对点的拉线,比较简单,只要拉线的时候遵循ddr3的布线原则就可以了,这部分就不做过多的介绍。
6.8 DDR3四片T型拓扑Fanout设计示例
DDR3两片T型结构的设计和fly-by结构设计在信号分组,电源布局布线,信号互连,数据线等长处理等上都是相同的做法。在布局、地址的拓扑结构,端接电阻,地址线等长略有区别。
6.8.1 两片DDR3 T型结构布局
两片DDR2与CPU的距离可以按照图8.1所示进行放置(这个距离也可以根据PCB的空间进行适当缩减)。
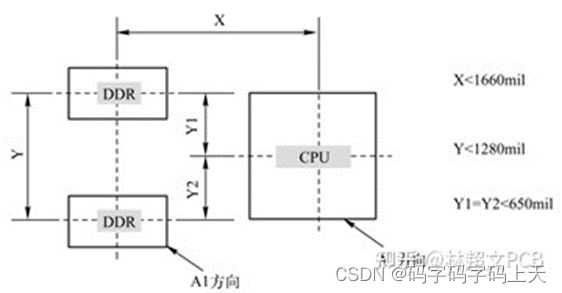 图6.14 两片DDR3T型结构的布局
图6.14 两片DDR3T型结构的布局
6.8.2 T型结构Fanout处理
拓扑结构的建立主要是在地址线扇出这个环节有很大区别,单片ddr3芯片的扇出的整体效果如图8.15所示。T型拓扑建立的效果图,如图6.16所示
 图6.15 T型结构单片DDR的扇出效果
图6.15 T型结构单片DDR的扇出效果  图6.16 T型拓扑建立的效果图
图6.16 T型拓扑建立的效果图
最终DDR芯片的信号都是从T点连到CPU,例如时钟线,如图8.17所示。
 图6.17信号从T点连到CPU
图6.17信号从T点连到CPU
7 DDR4之PCB走线间距的串扰评估
XX工,麻烦你把这组数据线的间距调大一些,我担心串扰会比较大”
“间距我已经按照3H处理了而且布线空间也没办法调整了”
“这个DDR4是要跑2400M的,麻烦您调整一个合适的间距,尽量不要出问题”
但是怎样才是合适的间距,在layout工程师眼里一直都是一个玄学的命题,只能放飞想象的翅膀,而不是一个可以用数字量化的结果。就好像串扰,也是一个抽象的世界,所以每每遇到这种问题,大家就只能佛系一点啦。
对于串扰,我们可能了解是怎么产生的,以及变化的趋势,但实际上,在遇到间距太近没有空间调整,或者双带线层叠的时候,我们能做的就是尽量拉开间距,却没有太直观的办法评估多大的间距会是比较合适的。在没有测试参数,没有仿真结果的情况下,是不是只能靠拍脑袋了呢?此时,Allegro17.2中的功能——线间耦合串扰分析“duang”就适时出场。这个功能可以帮layout工程师去衡量间距和串扰之间的平衡,用具体的参数告诉大家,怎样的间距才是合适的。还是一样用一个例子来说明新功能的实用性。
如下图所示DDR3信号,工作频率为1600Mbps,按照客户要求设置了比较严格的等长要求±5mil,由于空间的影响,部分地方间距压缩到5mil才能完成时序等长,这个间距和我们平时的设计规范是违背的,这种时候就需要准确的数据,用严谨的态度去说服客户修改等长要求,下面我们用线间耦合串扰分析去看一下5mil的间距对于信号的影响大不大。

首先选择Coupling Workflow,开始设置其他参数。选择需要分析的网络,设置耦合阈值为2%,意味着耦合率为2%以下时忽略不计。一般的遵循的规则是耦合率应该为5%以下,当耦合率高于5%以上时,信号间距就需要调整了。设置比较简单,傻瓜式操作,对于英语渣的我而言,可以说是非常的人性化了。选择start analysis。
 结果也是通过两种方式显示:coupling Vision,比较直观的一种方式,把鼠标放置在相应的线段上时,也会显示相应的耦合系数。
结果也是通过两种方式显示:coupling Vision,比较直观的一种方式,把鼠标放置在相应的线段上时,也会显示相应的耦合系数。

另一种结果显示方式是coupling table,数据比较清晰具体,主要关注的是最大耦合系数以及耦合系数大于5%的部分线长比例。
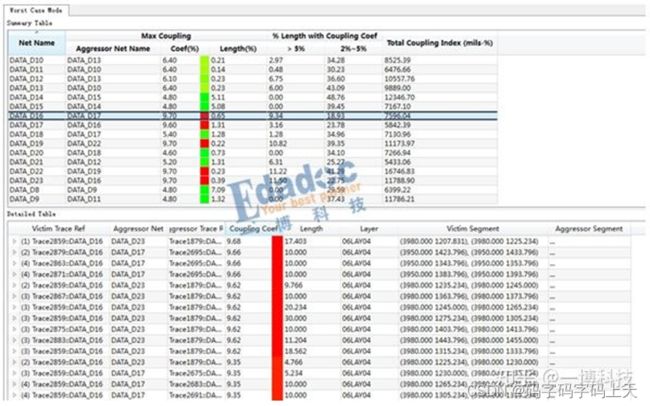
从上面的结果可以看到,部分网络的耦合系数达到9.7%,串扰太大,对信号质量可能影响会比较大。但这些地方都比较短,比较容易调整,所以可以选择适当放宽等长规则到±25mil,把间距拉开到9mil,这是可以满足时序,调整也比较小的一种方式,结果如下图,耦合系数均在5%以下。

引用文献:
- 知乎专栏:一搏科技。
- 知乎专栏:每日硬件知识。
- 知乎专栏:林超文PCB。