【MySQL】索引
文章目录
- 1. 前言
- 2. 索引的简介
- 3. 查看索引
- 4. 创建索引
- 5. 删除索引
- 6. 索引底层的数据结构
-
- 6.1 B树
- 6.2 B+树
- 7.索引的分类
- 8.总结
1. 前言
在SQL语句中,使用查询操作的频率比增删改的操作高.而在实际开发中,一张数据库表中的数据是很多的.想要快速查询出想要的数据效率是很低的.因此为了提高查询效率,所以就有了"索引"这个概念.
2. 索引的简介
“索引"可以理解为书/文章的目录,我们可通过目录快速找到我们想要找到的内容,但是如果没有目录,我们就得从头开始看.直到找到我们的
在算法中,有一个常见的操作是"用空间换时间”.顾名思义就是牺牲更多的空间来使时间复杂度变低."索引"也是如此, 使用"索引"有两个代价:1.使用索引会消耗更多的空间 2.虽然提高了查询的数据,但是降低了增删改的效率. 即使"索引"有弊端,但是我们仍然会使用"索引",因为通常认为查询操作比增删改的使用频率高
3. 查看索引
show index from 表名;

我这里有一个"索引",是使用主键约束自带的一个索引
4. 创建索引
create [UNIQUE|FULLTEXT] index 索引名 on 表名(字段,...);
# []中的是可选项
# UNIQUE: 唯一索引
# FULLTEXT: 全文索引
一个索引可以关联多个字段,如果一个索引只关联一个字段,那么这个索引叫"单列索引",如果一个索引关联多个字段,那么这个索引也称"联合索引"
示例:

可以看到刚开始的时候student这个表并没有"索引",后面我给student这个表中的"name"这一列创建了索引.
注意: 创建"索引" 也是一个低效操作,如果表中的数据多,创建索引就可能会非常耗时+带来大量的硬盘IO,从而导致数据库卡死.
5. 删除索引
drop index 索引名 on 表名;
示例:

删除索引和创建索引类似,也是低效操作.一般建议在建表的时候就创建好"索引"
6. 索引底层的数据结构
前面说到"索引"可以提高查询的效率,在我们学习常见的数据结构中可以提高查找效率的有二叉搜索树(二叉排序树)和哈希表. 但是这两种数据结构都不太适合做数据库的索引,当然也是有用哈希表作为索引的数据结构的.
原因:
- 虽然哈希表的增删改查的时间复杂度都是O(1),但也只是值相等的情况下,如果涉及到比较的操作,那么哈希表就无能为力了.
- 而二叉搜索树的查询速度在最坏的情况下是O(n).虽然后面有了AVL树和红黑树(比较平衡的二叉搜索树),此时的查找的效率是O(logn).如果数据库中的数据非常多,那么二叉搜索树的高度就会非常高.而二叉搜索树的高度是和比较次数呈正相关的.而进行比较操作是需要读硬盘的,这个就有点吃不消了.
数据库的索引中最常用的数据结构是 B+树,而且MySQL默认的存储引擎InnoDB也是以B+树作为索引的数据结构.,不过想要认识B+树,要先认识B树(B-树).
6.1 B树
B树(B-tree)是一种自平衡的树形数据结构,常用于数据库和文件系统中进行数据的存储和查找。B树的特点是可以存储大量的数据,而且查找、插入、删除等操作的时间复杂度都是O(log n),其中n是数据的总数。
B树示例图:
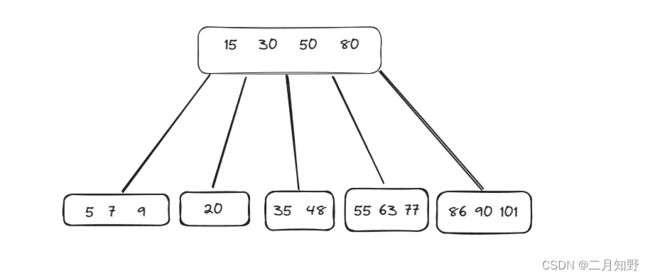
B树的结构类似于二叉搜索树(N叉搜索树),但每个节点可以有多个子节点。B树的节点通常包含多个关键字和对应的指针,关键字按照大小顺序排列,指针指向子节点或数据。
B树的自平衡性质是通过节点的分裂和合并来实现的。当一个节点中的关键字数量超过了指定的阈值时,就会进行分裂,将一部分关键字和指针移到新的节点中。当一个节点中的关键字数量低于指定的阈值时,就会进行合并,将相邻的节点合并成一个节点。
B树相对于普通的二叉搜索树来说有以下几个优点:
-
减少磁盘I/O操作:B树是一种多路搜索树,每个节点可以存储多个关键字和指针,因此可以减少磁盘I/O操作次数,提高数据访问效率。
-
更适合外部存储:B树的节点大小通常与磁盘块大小相同,因此可以更好地利用外部存储设备的特点,提高数据存储和访问效率。
-
平衡性更好:B树的每个节点都有多个子节点,因此树的高度相对较小,树的平衡性更好,查询效率更高。
-
更适合大规模数据:B树可以存储大量的数据,因此更适合处理大规模数据。
B树的不足: B树在查找元素的时候只适合 定值查找(查找一个固定的值),而不是和范围查找.为了解决这个问题,因此就有了B+树.
6.2 B+树
B+树是一种平衡树,常用于数据库和文件系统中的索引结构。它的特点是每个节点可以存储多个关键字和对应的数据指针,而且所有关键字都在叶子节点上出现,非叶子节点只存储关键字和指向子节点的指针。B+树的叶子节点形成了一个有序链表,可以方便地进行范围查询和遍历。B+树的插入、删除和查找操作的时间复杂度都是O(log n),因此它是一种高效的数据结构。
B+树示例图:
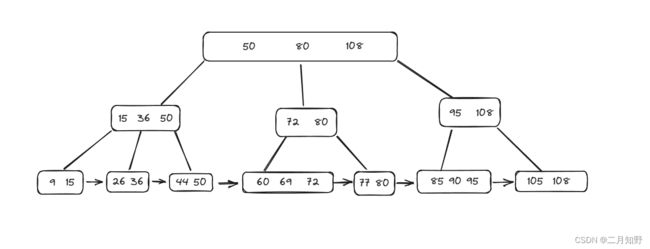
B+树和B树的差异在于以下几点:
- 有k个孩子的节点就有k个关键字。也就是孩子数量=关键字数,而B树中,孩子数量=关键字数+1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- 非叶子节点仅用于索引, 不保存数据记录,跟记录有关的信息都放在叶子节点中。而B树中,非叶子节点既
保存索引,也保存数据记录。 - 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大
顺序链接。
而在MySQL索引是对原有的B+树进行了优化,原本的B+树最下面的叶子就只是一个单向不循环链表,而MySQL索引中的B+树则是一个双向循环链表.
如图所示:

B+树的叶子结点就是全部的数据,用双向循环链表进行保存,此时就非常容易范围查找了, 只需取一段子链表即可.
正因为叶子节点是全集数据,只需要把每一行(每一条记录的完整的所有列关联到叶子节点上即可),非叶子节点,只需要保存索引列(只存个id),因此非叶子结点占用的空间很小,就可以在内存中缓存. 从而进一步减少硬盘I/O
B+树相对于B树主要有以下几个优点:
-
更适合磁盘存储:B+树的内部节点只存储键值信息,而不存储数据信息,所有数据都存储在叶子节点中。这样可以使得每个节点存储更多的键值信息,从而减少树的高度,减少磁盘I/O次数,提高查询效率。
-
更适合范围查询:由于B+树的所有数据都存储在叶子节点中,而且叶子节点之间有指针相连,因此B+树更适合范围查询。例如,如果要查询某个范围内的数据,只需要找到最小值和最大值所在的叶子节点,然后沿着指针遍历即可。
-
更适合顺序访问:由于B+树的所有数据都存储在叶子节点中,而且叶子节点之间有指针相连,因此B+树更适合顺序访问。例如,如果要对数据进行排序,只需要按照叶子节点的顺序遍历即可。
-
更适合并发访问:由于B+树的所有数据都存储在叶子节点中,而且叶子节点之间有指针相连,因此B+树更适合并发访问。例如,如果多个线程同时查询不同的数据,只需要访问不同的叶子节点即可,不会出现锁竞争的情况。
7.索引的分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered lndex) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary lndex) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果
存在主键,主键索引就是聚集索引。 - 如果
不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。 - 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
ps: 聚集索引和二级索引在SQL优化中十分重要.
8.总结
索引在MySQL中非常重要,B树和B+树的区别,MySQL为什么使用B+树作为索引的数据结构等也是很常见的面试问题.对于这些问题要能够熟练掌握.
感谢你的观看!希望这篇文章能帮到你!
专栏:《速通MySQL》在不断更新中,欢迎订阅!
“愿与君共勉,携手共进!”
