python数据分析电商用户行为,看完这一篇就够了
本文分析主要内容分为下四个部分:
一. 项目背景
二. 数据集介绍
三. 数据清洗
四. 分析模型构建
五. 总结
一. 项目背景
项目对京东电商运营数据集进行指标分析以了解用户购物行为特征,为运营决策提供支持建议。 本文采用了MySQL和Python两种代码进行指标计算以适应不同的数据分析开发环境。
二. 数据集介绍
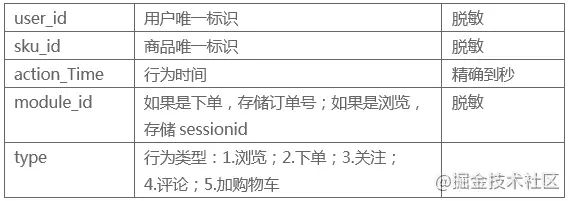
本数据集为京东竞赛数据集,详细介绍请访问链接: jdata.jd.com/html/detail… 。 数据集共有五个文件,包含了’2021-02-01’至’2021-04-15’之间的用户数据,数据已进行了脱敏处理,本文使用了其中的行为数据表,表中共有五个字段,各字段含义如下图所示 行为数据表(jdata_action)字段说明
三. 数据清洗
# 导入python相关模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import datetime
plt.style.use('ggplot')
%matplotlib inline
# 设置中文编码和负号的正常显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
复制代码
# 读取数据,数据集较大,如果计算机读取内存不够用,可以尝试kaggle比赛
# 中的reduce_mem_usage函数,附在文末,主要原理是把int64/float64
# 类型的数值用更小的int(float)32/16/8来搞定
user_action = pd.read_csv('jdata_action.csv')
复制代码
# 因数据集过大,本文截取'2018-03-30'至'2018-04-15'之间的数据完成本次分析
# 注:仅4月份的数据包含加购物车行为,即type == 5
user_data = user_action[(user_action['action_time'] > '2018-03-30') & (user_action['action_time'] < '2018-04-15')]
复制代码
# 存至本地备用
user_data.to_csv('user_data.csv',sep=',')
复制代码
# 查看原始数据各字段类型
behavior = pd.read_csv('user_data.csv', index_col=0)
behavior[:10]
复制代码
# OUTPUT
user_id sku_id action_time module_id type
17 1455298 208441 2018-04-11 15:21:43 6190659 1
18 1455298 334318 2018-04-11 15:14:54 6190659 1
19 1455298 237755 2018-04-11 15:14:13 6190659 1
20 1455298 6422 2018-04-11 15:22:25 6190659 1
21 1455298 268566 2018-04-11 15:14:26 6190659 1
22 1455298 115915 2018-04-11 15:13:35 6190659 1
23 1455298 208254 2018-04-11 15:22:16 6190659 1
24 1455298 177209 2018-04-14 14:09:59 6628254 1
25 1455298 71793 2018-04-14 14:10:29 6628254 1
26 1455298 141950 2018-04-12 15:37:53 10207258 1
复制代码
behavior.info()
复制代码
# OUTPUT
Int64Index: 7540394 entries, 17 to 37214234
Data columns (total 5 columns):
user_id int64
sku_id int64
action_time object
module_id int64
type int64
dtypes: int64(4), object(1)
memory usage: 345.2+ MB
复制代码
# 查看缺失值
behavior.isnull().sum()
复制代码
# OUTPUT
user_id 0
sku_id 0
action_time 0
module_id 0
type 0
dtype: int64
复制代码
数据各列无缺失值。
# 原始数据中时间列action_time,时间和日期是在一起的,不方便分析,对action_time列进行处理,拆分出日期和时间列,并添加星期字段求出每天对应
# 的星期,方便后续按时间纬度对数据进行分析
behavior['date'] = pd.to_datetime(behavior['action_time']).dt.date # 日期
behavior['hour'] = pd.to_datetime(behavior['action_time']).dt.hour # 时间
behavior['weekday'] = pd.to_datetime(behavior['action_time']).dt.weekday_name # 周
复制代码
# 去除与分析无关的列
behavior = behavior.drop('module_id', axis=1)
复制代码
# 将用户行为标签由数字类型改为用字符表示
behavior_type = {1:'pv',2:'pay',3:'fav',4:'comm',5:'cart'}
behavior['type'] = behavior['type'].apply(lambda x: behavior_type[x])
behavior.reset_index(drop=True,inplace=True)
复制代码
# 查看处理好的数据
behavior[:10]
复制代码
# OUTPUT
user_id sku_id action_time type date hour weekday
0 1455298 208441 2018-04-11 15:21:43 pv 2018-04-11 15 Wednesday
1 1455298 334318 2018-04-11 15:14:54 pv 2018-04-11 15 Wednesday
2 1455298 237755 2018-04-11 15:14:13 pv 2018-04-11 15 Wednesday
3 1455298 6422 2018-04-11 15:22:25 pv 2018-04-11 15 Wednesday
4 1455298 268566 2018-04-11 15:14:26 pv 2018-04-11 15 Wednesday
5 1455298 115915 2018-04-11 15:13:35 pv 2018-04-11 15 Wednesday
6 1455298 208254 2018-04-11 15:22:16 pv 2018-04-11 15 Wednesday
7 1455298 177209 2018-04-14 14:09:59 pv 2018-04-14 14 Saturday
8 1455298 71793 2018-04-14 14:10:29 pv 2018-04-14 14 Saturday
9 1455298 141950 2018-04-12 15:37:53 pv 2018-04-12 15 Thursday
复制代码
四. 分析模型构建分析指标
- 流量指标分析
- 用户消费频次分析
- 用户行为在时间纬度的分布
- 用户行为转化漏斗
- 用户留存率分析
- 商品销量分析
- RFM用户价值分层
1.流量指标分析
pv、uv、消费用户数占比、消费用户总访问量占比、消费用户人均访问量、跳失率
- PV UV
# 总访问量
pv = behavior[behavior['type'] == 'pv']['user_id'].count()
# 总访客数
uv = behavior['user_id'].nunique()
# 消费用户数
user_pay = behavior[behavior['type'] == 'pay']['user_id'].unique()
# 日均访问量
pv_per_day = pv / behavior['date'].nunique()
# 人均访问量
pv_per_user = pv / uv
# 消费用户访问量
pv_pay = behavior[behavior['user_id'].isin(user_pay)]['type'].value_counts().pv
# 消费用户数占比
user_pay_rate = len(user_pay) / uv
# 消费用户访问量占比
pv_pay_rate = pv_pay / pv
# 消费用户人均访问量
pv_per_buy_user = pv_pay / len(user_pay)
复制代码
# SQL
SELECT count(DISTINCT user_id) UV,
(SELECT count(*) PV from behavior_sql WHERE type = 'pv') PV
FROM behavior_sql;
SELECT count(DISTINCT user_id)
FROM behavior_sql
WHERE WHERE type = 'pay';
SELECT type, COUNT(*) FROM behavior_sql
WHERE
user_id IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = 'pay')
AND type = 'pv'
GROUP BY type;
复制代码
print('总访问量为 %i' %pv)
print('总访客数为 %i' %uv)
print('消费用户数为 %i' %len(user_pay))
print('消费用户访问量为 %i' %pv_pay)
print('日均访问量为 %.3f' %pv_per_day)
print('人均访问量为 %.3f' %pv_per_user)
print('消费用户人均访问量为 %.3f' %pv_per_buy_user)
print('消费用户数占比为 %.3f%%' %(user_pay_rate * 100))
print('消费用户访问量占比为 %.3f%%' %(pv_pay_rate * 100))
复制代码
# OUTPUT
总访问量为 6229177
总访客数为 728959
消费用户数为 395874
消费用户访问量为 3918000
日均访问量为 389323.562
人均访问量为 8.545
消费用户人均访问量为 9.897
消费用户数占比为 54.307%
消费用户访问量占比为 62.898%
复制代码
消费用户人均访问量和总访问量占比都在平均值以上,有过消费记录的用户更愿意在网站上花费更多时间,说明网站的购物体验尚可,老用户对网站有一定依赖性,对没有过消费记录的用户要让快速了解产品的使用方法和价值,加强用户和平台的黏连。
- 跳失率
# 跳失率:只进行了一次操作就离开的用户数/总用户数
attrition_rates = sum(behavior.groupby('user_id')['type'].count() == 1) / (behavior['user_id'].nunique())
复制代码
# SQL
SELECT
(SELECT COUNT(*)
FROM (SELECT user_id
FROM behavior_sql GROUP BY user_id
HAVING COUNT(type)=1) A) /
(SELECT COUNT(DISTINCT user_id) UV FROM behavior_sql) attrition_rates;
复制代码
print('跳失率为 %.3f%%' %(attrition_rates * 100) )
复制代码
# OUTPUT
跳失率为 22.585%
复制代码
整个计算周期内跳失率为22.585%,还是有较多的用户仅做了单次操作就离开了页面,需要从首页页面布局以及产品用户体验等方面加以改善,提高产品吸引力。
2. 用户消费频次分析
# 单个用户消费总次数
total_buy_count = (behavior[behavior['type']=='pay'].groupby(['user_id'])['type'].count()
.to_frame().rename(columns={'type':'total'}))
# 消费次数前10客户
topbuyer10 = total_buy_count.sort_values(by='total',ascending=False)[:10]
# 复购率
re_buy_rate = total_buy_count[total_buy_count>=2].count()/total_buy_count.count()
复制代码
# SQL
#消费次数前10客户
SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id
ORDER BY COUNT(type) DESC
LIMIT 10
#复购率
CREAT VIEW v_buy_count
AS SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id;
SELECT CONCAT(ROUND((SUM(CASE WHEN total_buy_count>=2 THEN 1 ELSE 0 END)/
SUM(CASE WHEN total_buy_count>0 THEN 1 ELSE 0 END))*100,2),'%') AS re_buy_rate
FROM v_buy_count;
复制代码
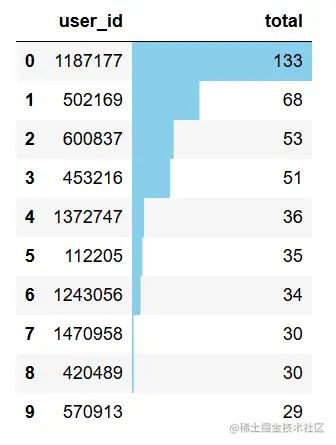
topbuyer10.reset_index().style.bar(color='skyblue',subset=['total'])
复制代码
# 单个用户消费总次数可视化
tbc_box = total_buy_count.reset_index()
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(x=tbc_box['total'],data=tbc_box,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(tbc_box['total'])), (p.get_x() - 0.1, p.get_height()))
plt.title('用户消费总次数')
复制代码
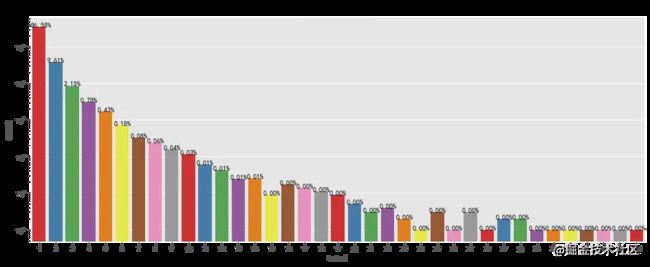
整个计算周期内,最高购物次数为133次,最低为1次,大部分用户的购物次数在6次以下,可适当增加推广,完善购物体验,提高用户消费次数。购物次数前10用户为1187177、502169等,应提高其满意度,增大留存率。
print('复购率为 %.3f%%' %(re_buy_rate * 100) )
复制代码
# OUTPUT
复购率为 13.419%
复制代码
复购率较低,应加强老用户召回机制,提升购物体验,也可能因数据量较少,统计周期之内的数据 无法解释完整的购物周期,从而得出结论有误。
3. 用户行为在时间纬度的分布
- 日消费次数、日活跃人数、日消费人数、日消费人数占比、消费用户日人均消费次数
# 日活跃人数(有一次操作即视为活跃)
daily_active_user = behavior.groupby('date')['user_id'].nunique()
# 日消费人数
daily_buy_user = behavior[behavior['type'] == 'pay'].groupby('date')['user_id'].nunique()
# 日消费人数占比
proportion_of_buyer = daily_buy_user / daily_active_user
# 日消费总次数
daily_buy_count = behavior[behavior['type'] == 'pay'].groupby('date')['type'].count()
# 消费用户日人均消费次数
consumption_per_buyer = daily_buy_count / daily_buy_user
复制代码
# SQL
# 日消费总次数
SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日活跃人数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
# 日消费人数
SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日消费人数占比
SELECT
(SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
# 日人均消费次数
SELECT
(SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
复制代码
# 日消费人数占比可视化
# 柱状图数据
pob_bar = (pd.merge(daily_active_user,daily_buy_user,on='date').reset_index()
.rename(columns={'user_id_x':'日活跃人数','user_id_y':'日消费人数'})
.set_index('date').stack().reset_index().rename(columns={'level_1':'Variable',0: 'Value'}))
# 线图数据
pob_line = proportion_of_buyer.reset_index().rename(columns={'user_id':'Rate'})
fig1 = plt.figure(figsize=[16,6])
ax1 = fig1.add_subplot(111)
ax2 = ax1.twinx()
sns.barplot(x='date', y='Value', hue='Variable', data=pob_bar, ax=ax1, alpha=0.8, palette='husl')
ax1.legend().set_title('')
ax1.legend().remove()
sns.pointplot(pob_line['date'], pob_line['Rate'], ax=ax2,markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,pob_line['Rate']):
plt.text(a+0.1, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12)
fig1.legend(loc='upper center',ncol=2)
plt.title('日消费人数占比')
复制代码

日活跃人数与日消费人数无明显波动,日消费人数占比均在20%以上。
# 消费用户日人均消费次数可视化
# 柱状图数据
cpb_bar = (daily_buy_count.reset_index().rename(columns={'type':'Num'}))
# 线图数据
cpb_line = (consumption_per_buyer.reset_index().rename(columns={0:'Frequency'}))
fig2 = plt.figure(figsize=[16,6])
ax3 = fig2.add_subplot(111)
ax4 = ax3.twinx()
sns.barplot(x='date', y='Num', data=cpb_bar, ax=ax3, alpha=0.8, palette='pastel')
sns.pointplot(cpb_line['date'], cpb_line['Frequency'], ax=ax4, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,cpb_line['Frequency']):
plt.text(a+0.1, b + 0.001, '%.2f' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('消费用户日人均消费次数')
复制代码

日消费人数在25000以上,日人均消费次数大于1次。
dau3_df = behavior.groupby(['date','user_id'])['type'].count().reset_index()
dau3_df = dau3_df[dau3_df['type'] >= 3]
复制代码
# 每日高活跃用户数(每日操作数大于3次)
dau3_num = dau3_df.groupby('date')['user_id'].nunique()
复制代码
# SQL
SELECT date, COUNT(DISTINCT user_id)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY date;
复制代码
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(dau3_num.index, dau3_num.values, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,dau3_num.values):
plt.text(a+0.1, b + 300 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日高活跃用户数')
复制代码
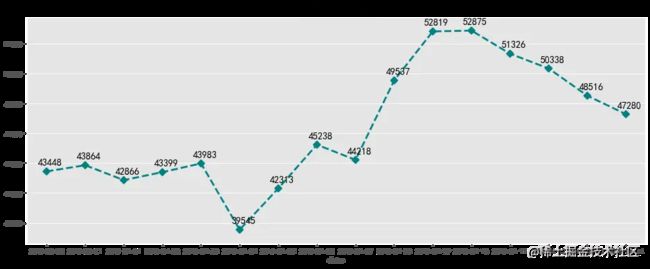
每日高活跃用户数在大部分4万以上,2018-04-04之前数量比较平稳,之后数量一直攀升,8号9号达到最高,随后下降,推测数据波动应为营销活动产生的。
# 高活跃用户累计活跃天数分布
dau3_cumsum = dau3_df.groupby('user_id')['date'].count()
复制代码
# SQL
SELECT user_id, COUNT(date)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY user_id;
复制代码
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(dau3_cumsum.values,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(dau3_cumsum.values)), (p.get_x() + 0.2, p.get_height() + 100))
plt.title('高活跃用户累计活跃天数分布')
复制代码
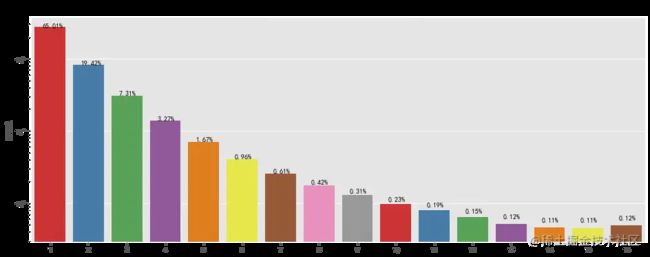
统计周期内,大部分高活跃用户累计活跃天数在六天以下,但也存在高达十六天的超级活跃用户数量,对累计天数较高的用户要推出连续登录奖励等继续维持其对平台的黏性,对累计天数较低的用户要适当进行推送活动消息等对其进行召回。
#每日浏览量
pv_daily = behavior[behavior['type'] == 'pv'].groupby('date')['user_id'].count()
#每日访客数
uv_daily = behavior.groupby('date')['user_id'].nunique()
复制代码
# SQL
#每日浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY date;
#每日访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
复制代码
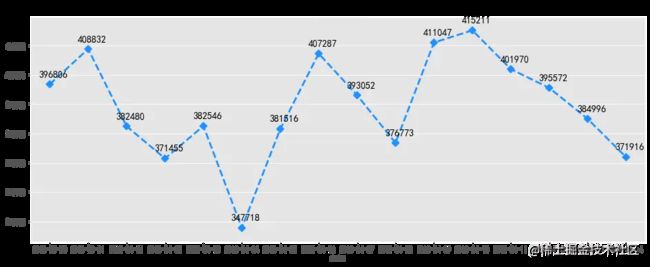
# 每日浏览量可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_daily.index, pv_daily.values,markers='D', linestyles='--',color='dodgerblue')
x=list(range(0,16))
for a,b in zip(x,pv_daily.values):
plt.text(a+0.1, b + 2000 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日浏览量')
复制代码
# 每日访客数可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_daily.index, uv_daily.values, markers='H', linestyles='--',color='m')
x=list(range(0,16))
for a,b in zip(x,uv_daily.values):
plt.text(a+0.1, b + 500 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日访客数')
复制代码
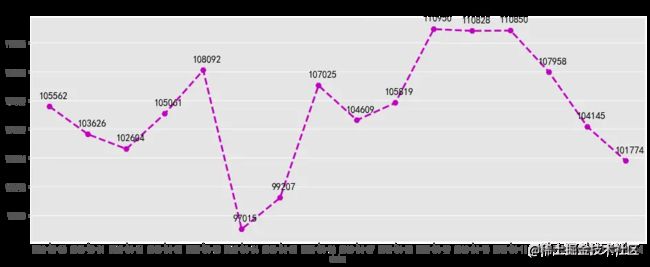
浏览量和访客数每日变化趋势大致相同,2018-04-04日前后用户数量变化波动较大,4月4日为清明节假日前一天,各数据量在当天均有明显下降,但之后逐步回升,推测应为节假日营销活动或推广拉新活动带来的影响。
#每时浏览量
pv_hourly = behavior[behavior['type'] == 'pv'].groupby('hour')['user_id'].count()
#每时访客数
uv_hourly = behavior.groupby('hour')['user_id'].nunique()
复制代码
# SQL
# 每时浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY hour;
# 每时访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY hour;
复制代码
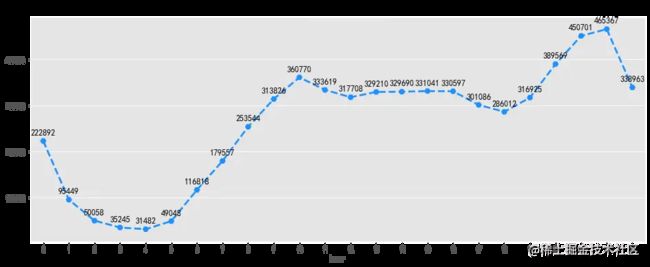
# 浏览量随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_hourly.index, pv_hourly.values, markers='H', linestyles='--',color='dodgerblue')
for a,b in zip(pv_hourly.index,pv_hourly.values):
plt.text(a, b + 10000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('浏览量随小时变化')
复制代码
# 访客数随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_hourly.index, uv_hourly.values, markers='H', linestyles='--',color='m')
for a,b in zip(uv_hourly.index,uv_hourly.values):
plt.text(a, b + 1000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('访客数随小时变化')
复制代码
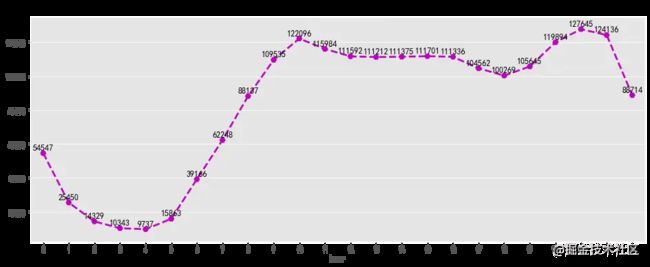
浏览量及访客数随小时变化趋势一致,在凌晨1点到凌晨5点之间,大部分用户正在休息,整体活跃度较低。凌晨5点到10点用户开始起床工作,活跃度逐渐增加,之后趋于平稳,下午6点之后大部分人恢复空闲,浏览量及访客数迎来了第二波攀升,在晚上8点中到达高峰,随后逐渐下降。可以考虑在上午9点及晚上8点增大商品推广力度,加大营销活动投入,可取的较好的收益,1点到5点之间适合做系统维护。
# 用户各操作随小时变化
type_detail_hour = pd.pivot_table(columns = 'type',index = 'hour', data = behavior,aggfunc=np.size,values = 'user_id')
# 用户各操作随星期变化
type_detail_weekday = pd.pivot_table(columns = 'type',index = 'weekday', data = behavior,aggfunc=np.size,values = 'user_id')
type_detail_weekday = type_detail_weekday.reindex(['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])
复制代码
# SQL
# 用户各操作随小时变化
SELECT hour,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY hour
ORDER BY hour
# 用户各操作随星期变化
SELECT weekday,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY weekday
ORDER BY weekday
复制代码
tdh_line = type_detail_hour.stack().reset_index().rename(columns={0: 'Value'})
tdw_line = type_detail_weekday.stack().reset_index().rename(columns={0: 'Value'})
tdh_line= tdh_line[~(tdh_line['type'] == 'pv')]
tdw_line= tdw_line[~(tdw_line['type'] == 'pv')]
复制代码
# 用户操作随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='hour', y='Value', hue='type', data=tdh_line, linestyles='--')
plt.title('用户操作随小时变化')
复制代码
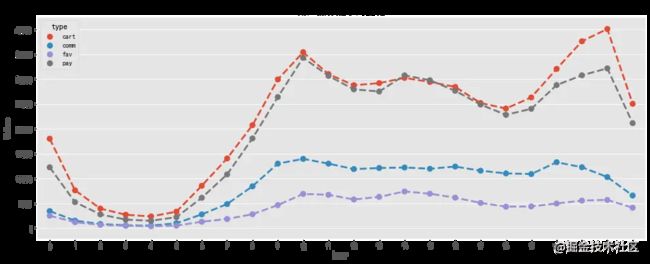
用户操作随小时变化规律与PV、UV随小时规律相似,与用户作息规律相关,加入购物车和付款两条曲线贴合比比较紧密,说明大部分用户习惯加入购物车后直接购买。关注数相对较少,可以根据用户购物车内商品进行精准推送。评论数也相对较少,说明大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。
# 用户操作随星期变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='weekday', y='Value', hue='type', data=tdw_line[~(tdw_line['type'] == 'pv')], linestyles='--')
plt.title('用户操作随星期变化')
复制代码
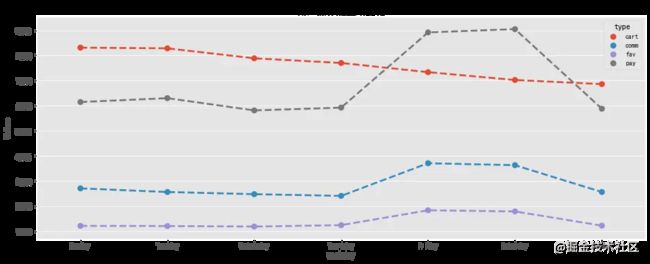
周一到周四工作日期间,用户操作随星期变化比较平稳,周五至周六进入休息日,用户操作明显增多,周日又恢复正常。
4. 用户行为转化漏斗
# 导入相关包
from pyecharts import options as opts
from pyecharts.charts import Funnel
import math
复制代码
behavior['action_time'] = pd.to_datetime(behavior['action_time'],format ='%Y-%m-%d %H:%M:%S')
复制代码
# 用户整体行为分布
type_dis = behavior['type'].value_counts().reset_index()
type_dis['rate'] = round((type_dis['type'] / type_dis['type'].sum()),3)
复制代码
type_dis.style.bar(color='skyblue',subset=['rate'])
复制代码
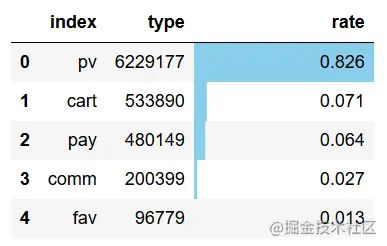
用户整体行为中,有82.6%行为为浏览,实际支付操作仅占6.4,除此之外,用户评论及收藏的行为占比也较低,应当增强网站有用户之间的互动,提高评论数量和收藏率。
df_con = behavior[['user_id', 'sku_id', 'action_time', 'type']]
复制代码
df_pv = df_con[df_con['type'] == 'pv']
df_fav = df_con[df_con['type'] == 'fav']
df_cart = df_con[df_con['type'] == 'cart']
df_pay = df_con[df_con['type'] == 'pay']
df_pv_uid = df_con[df_con['type'] == 'pv']['user_id'].unique()
df_fav_uid = df_con[df_con['type'] == 'fav']['user_id'].unique()
df_cart_uid = df_con[df_con['type'] == 'cart']['user_id'].unique()
df_pay_uid = df_con[df_con['type'] == 'pay']['user_id'].unique()
复制代码
- pv - buy
fav_cart_list = set(df_fav_uid) | set(df_cart_uid)
复制代码
pv_pay_df = pd.merge(left=df_pv, right=df_pay, how='inner', on=['user_id', 'sku_id'],
suffixes=('_pv', '_pay'))
复制代码
pv_pay_df = pv_pay_df[(~pv_pay_df['user_id'].isin(fav_cart_list)) & (pv_pay_df['action_time_pv'] < pv_pay_df['action_time_pay'])]
复制代码
uv = behavior['user_id'].nunique()
pv_pay_num = pv_pay_df['user_id'].nunique()
pv_pay_data = pd.DataFrame({'type':['浏览','付款'],'num':[uv,pv_pay_num]})
pv_pay_data['conversion_rates'] = (round((pv_pay_data['num'] / pv_pay_data['num'][0]),4) * 100)
复制代码
attr1 = list(pv_pay_data.type)
values1 = list(pv_pay_data.conversion_rates)
data1 = [[attr1[i], values1[i]] for i in range(len(attr1))]
复制代码
# 用户行为转化漏斗可视化
pv_pay=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data1,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_pay.render_notebook()
复制代码
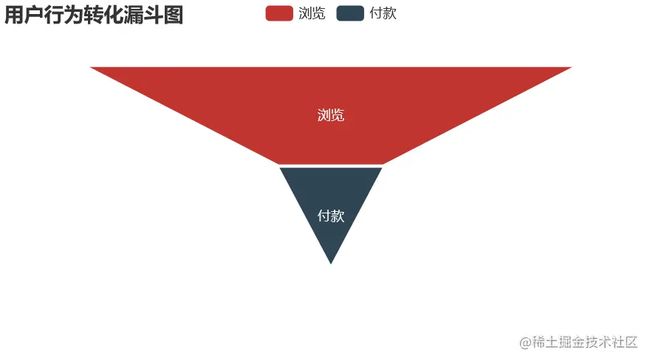
- pv - cart - pay
pv_cart_df = pd.merge(left=df_pv, right=df_cart, how='inner', on=['user_id', 'sku_id'],
suffixes=('_pv', '_cart'))
复制代码
pv_cart_df = pv_cart_df[pv_cart_df['action_time_pv'] < pv_cart_df['action_time_cart']]
pv_cart_df = pv_cart_df[~pv_cart_df['user_id'].isin(df_fav_uid)]
复制代码
pv_cart_pay_df = pd.merge(left=pv_cart_df, right=df_pay, how='inner', on=['user_id', 'sku_id'])
复制代码
pv_cart_pay_df = pv_cart_pay_df[pv_cart_pay_df['action_time_cart'] < pv_cart_pay_df['action_time']]
复制代码
uv = behavior['user_id'].nunique()
pv_cart_num = pv_cart_df['user_id'].nunique()
pv_cart_pay_num = pv_cart_pay_df['user_id'].nunique()
pv_cart_pay_data = pd.DataFrame({'type':['浏览','加购','付款'],'num':[uv,pv_cart_num,pv_cart_pay_num]})
pv_cart_pay_data['conversion_rates'] = (round((pv_cart_pay_data['num'] / pv_cart_pay_data['num'][0]),4) * 100)
复制代码
attr2 = list(pv_cart_pay_data.type)
values2 = list(pv_cart_pay_data.conversion_rates)
data2 = [[attr2[i], values2[i]] for i in range(len(attr2))]
复制代码
# 用户行为转化漏斗可视化
pv_cart_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data2,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_cart_buy.render_notebook()
复制代码
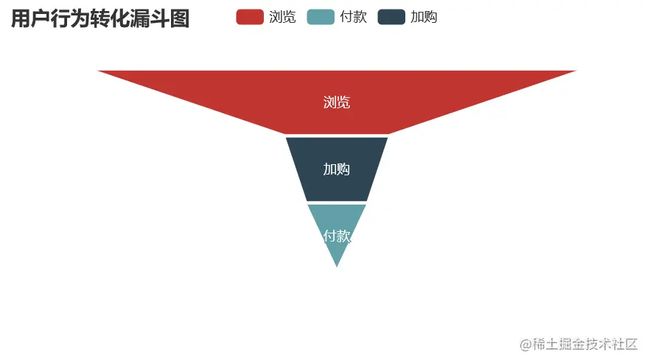
- pv - fav - pay
pv_fav_df = pd.merge(left=df_pv, right=df_fav, how='inner', on=['user_id', 'sku_id'],
suffixes=('_pv', '_fav'))
复制代码
pv_fav_df = pv_fav_df[pv_fav_df['action_time_pv'] < pv_fav_df['action_time_fav']]
pv_fav_df = pv_fav_df[~pv_fav_df['user_id'].isin(df_cart_uid)]
复制代码
pv_fav_pay_df = pd.merge(left=pv_fav_df, right=df_pay, how='inner', on=['user_id', 'sku_id'])
复制代码
pv_fav_pay_df = pv_fav_pay_df[pv_fav_pay_df['action_time_fav'] < pv_fav_pay_df['action_time']]
复制代码
uv = behavior['user_id'].nunique()
pv_fav_num = pv_fav_df['user_id'].nunique()
pv_fav_pay_num = pv_fav_pay_df['user_id'].nunique()
pv_fav_pay_data = pd.DataFrame({'type':['浏览','收藏','付款'],'num':[uv,pv_fav_num,pv_fav_pay_num]})
pv_fav_pay_data['conversion_rates'] = (round((pv_fav_pay_data['num'] / pv_fav_pay_data['num'][0]),4) * 100)
复制代码
attr3 = list(pv_fav_pay_data.type)
values3 = list(pv_fav_pay_data.conversion_rates)
data3 = [[attr3[i], values3[i]] for i in range(len(attr3))]
复制代码
# 用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data3,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_fav_buy.render_notebook()
复制代码

- pv - fav - cart - pay
pv_fav = pd.merge(left=df_pv, right=df_fav, how='inner', on=['user_id', 'sku_id'],
suffixes=('_pv', '_fav'))
复制代码
pv_fav = pv_fav[pv_fav['action_time_pv'] < pv_fav['action_time_fav']]
复制代码
pv_fav_cart = pd.merge(left=pv_fav, right=df_cart, how='inner', on=['user_id', 'sku_id'])
复制代码
pv_fav_cart = pv_fav_cart[pv_fav_cart['action_time_fav']pv_fav_cart_pay = pd.merge(left=pv_fav_cart, right=df_pay, how='inner', on=['user_id', 'sku_id'],
suffixes=('_cart', '_pay'))
复制代码
pv_fav_cart_pay = pv_fav_cart_pay[pv_fav_cart_pay['action_time_cart']uv = behavior['user_id'].nunique()
pv_fav_n = pv_fav['user_id'].nunique()
pv_fav_cart_n = pv_fav_cart['user_id'].nunique()
pv_fav_cart_pay_n = pv_fav_cart_pay['user_id'].nunique()
pv_fav_cart_pay_data = pd.DataFrame({'type':['浏览','收藏','加购','付款'],'num':[uv,pv_fav_n,pv_fav_cart_n,pv_fav_cart_pay_n]})
pv_fav_cart_pay_data['conversion_rates'] = (round((pv_fav_cart_pay_data['num'] / pv_fav_cart_pay_data['num'][0]),4) * 100)
复制代码
attr4 = list(pv_fav_cart_pay_data.type)
values4 = list(pv_fav_cart_pay_data.conversion_rates)
data4 = [[attr4[i], values4[i]] for i in range(len(attr4))]
复制代码
# 用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data4,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_fav_buy.render_notebook()
复制代码
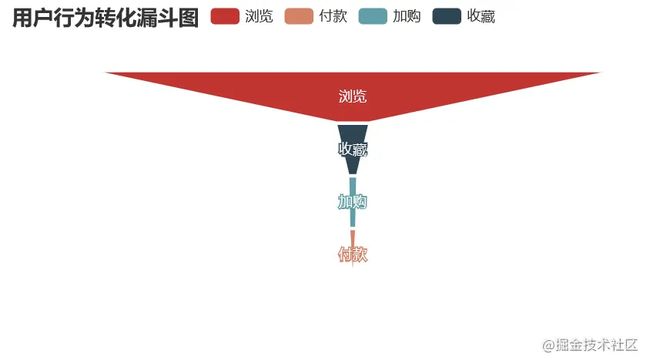
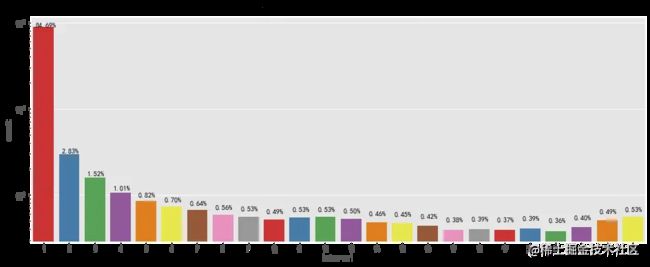
不同路径用户消费时间间隔分析
- pv - cart - pay
pcp_interval = pv_cart_pay_df.groupby(['user_id', 'sku_id']).apply(lambda x: (x.action_time.min() - x.action_time_cart.min())).reset_index()
复制代码
pcp_interval['interval'] = pcp_interval[0].apply(lambda x: x.seconds) / 3600
pcp_interval['interval'] = pcp_interval['interval'].apply(lambda x: math.ceil(x))
复制代码
fig, ax = plt.subplots(figsize=[16,6])
sns.countplot(pcp_interval['interval'],palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pcp_interval['interval'])), (p.get_x() + 0.1, p.get_height() + 100))
ax.set_yscale("log")
plt.title('pv-cart-pay路径用户消费时间间隔')
复制代码
- pv - fav - pay
pfp_interval = pv_fav_pay_df.groupby(['user_id', 'sku_id']).apply(lambda x: (x.action_time.min() - x.action_time_fav.min())).reset_index()
复制代码
pfp_interval['interval'] = pfp_interval[0].apply(lambda x: x.seconds) / 3600
pfp_interval['interval'] = pfp_interval['interval'].apply(lambda x: math.ceil(x))
复制代码
fig, ax = plt.subplots(figsize=[16,6])
sns.countplot(pfp_interval['interval'],palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pfp_interval['interval'])), (p.get_x() + 0.1, p.get_height() + 10))
ax.set_yscale("log")
plt.title('pv-fav-pay路径用户消费时间间隔')
复制代码
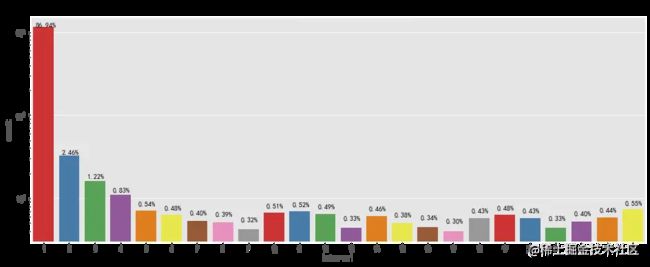
两种路径下大部分用户均在4小时内完成了支付,大部分用户的购物意向很明确,也侧面说明了网站的商品分类布局和购物结算方式比较合理。
# SQL
# 漏斗图
SELECT type, COUNT(DISTINCT user_id) user_num
FROM behavior_sql
GROUP BY type
ORDER BY COUNT(DISTINCT user_id) DESC
SELECT COUNT(DISTINCT b.user_id) AS pv_fav_num,COUNT(DISTINCT c.user_id) AS pv_fav_pay_num
FROM
((SELECT DISTINCT user_id, sku_id, action_time FROM users WHERE type='pv' ) AS a
LEFT JOIN
(SELECT DISTINCT user_id, sku_id, action_time FROM users WHERE type='fav'
AND user_id NOT IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = 'cart')) AS b
ON a.user_id = b.user_id AND a.sku_id = b.sku_id AND a.action_time <= b.action_time
LEFT JOIN
(SELECT DISTINCT user_id,sku_id,item_category,times_new FROM users WHERE behavior_type='pay') AS c
ON b.user_id = c.user_id AND b.sku_id = c.sku_id AND AND b.action_time <= c.action_time)
;
复制代码
比较四种不同的转化方式,最有效的转化路径为浏览直接付款转化率为21.46%,其次为浏览加购付款,转化率为12.47%,可以发现随着结算方式越来越复杂转化率越来越低。加购的方式比收藏购买的方式转化率要高,推其原因为购物车接口进入方便且可以做不同商家比价用,而收藏则需要更繁琐的操作才可以查看到商品,因此转化率较低。
可以优化商品搜索功能,提高商品搜索准确度、易用性,减少用户搜索时间。根据用户喜好在首页进行商品推荐,优化重排商品详情展示页,提高顾客下单欲望,提供一键购物等简化购物步骤的功能,客服也可以留意加购及关注用户,适时推出优惠福利及时解答用户问题,引导用户购买以进一步提高转化率。
对于用户消费时间间隔,可以通过限时领券购买、限时特惠价格等进一步缩短用户付款时间,提高订单量。
5. 用户留存率分析
#留存率
first_day = datetime.date(datetime.strptime('2018-03-30', '%Y-%m-%d'))
fifth_day = datetime.date(datetime.strptime('2018-04-03', '%Y-%m-%d'))
tenth_day = datetime.date(datetime.strptime('2018-04-08', '%Y-%m-%d'))
fifteenth_day = datetime.date(datetime.strptime('2018-04-13', '%Y-%m-%d'))
#第一天新用户数
user_num_first = behavior[behavior['date'] == first_day]['user_id'].to_frame()
#第五天留存用户数
user_num_fifth = behavior[behavior['date'] == fifth_day ]['user_id'].to_frame()
#第十留存用户数
user_num_tenth = behavior[behavior['date'] == tenth_day]['user_id'].to_frame()
#第十五天留存用户数
user_num_fifteenth = behavior[behavior['date'] == fifteenth_day]['user_id'].to_frame()
复制代码
#第五天留存率
fifth_day_retention_rate = round((pd.merge(user_num_first, user_num_fifth).nunique())
/ (user_num_first.nunique()),4).user_id
#第十天留存率
tenth_day_retention_rate = round((pd.merge(user_num_first, user_num_tenth ).nunique())
/ (user_num_first.nunique()),4).user_id
#第十五天留存率
fifteenth_day_retention_rate = round((pd.merge(user_num_first, user_num_fifteenth).nunique())
/ (user_num_first.nunique()),4).user_id
复制代码
retention_rate = pd.DataFrame({'n日后留存率':['第五天留存率','第十天留存率','第十五天留存率'],
'Rate':[fifth_day_retention_rate,tenth_day_retention_rate,fifteenth_day_retention_rate]})
复制代码
# 留存率可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.barplot(x='n日后留存率', y='Rate', data=retention_rate,
palette='Set1')
x=list(range(0,3))
for a,b in zip(x,retention_rate['Rate']):
plt.text(a, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12)
plt.title('用户留存率')
复制代码
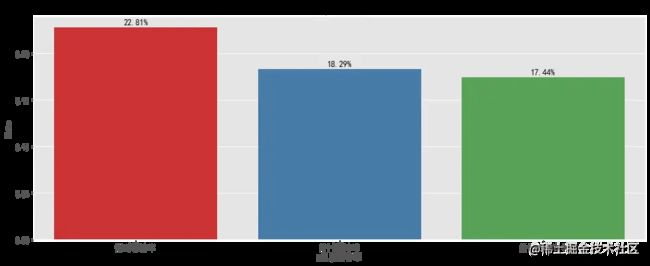
留存率反应了产品质量和保留用户的能力,按照Facebook平台流传出留存率“40–20–10”规则(规则中的数字表示的是次日留存率、第7日留存率和第30日留存率),统计周期内第五日留存率为22.81%,第15日留存率为17.44%,反映出平台的用户依赖性较高,也因平台发展已经到达稳定阶段,用户保留率不会发生较大波动,数据量足够的情况下可以以年为单位,计算按月的留存率。要合理安排消息推送,推出签到有奖等机制提高用户粘性,进一步提高留存率。
# SQL
#n日后留存率=(注册后的n日后还登录的用户数)/第一天新增总用户数
create table retention_rate as select count(distinct user_id) as user_num_first from behavior_sql
where date = '2018-03-30';
alter table retention_rate add column user_num_fifth INTEGER;
update retention_rate set user_num_fifth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-03' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
alter table retention_rate add column user_num_tenth INTEGER;
update retention_rate set user_num_tenth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-08' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
alter table retention_rate add column user_num_fifteenth INTEGER;
update retention_rate set user_num_fifteenth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-13' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
SELECT CONCAT(ROUND(100*user_num_fifth/user_num_first,2),'%')AS fifth_day_retention_rate,
CONCAT(ROUND(100*user_num_tenth/user_num_first,2),'%')AS tenth_day_retention_rate,
CONCAT(ROUND(100*user_num_fifteenth/user_num_first,2),'%')AS fifteenth_day_retention_rate
from retention_rate;
复制代码
6. 商品销量分析
# 商品总数
behavior['sku_id'].nunique()
复制代码
# OUTPUT
239007
复制代码
# 商品被购前产生平均操作次数
sku_df = behavior[behavior['sku_id'].isin(behavior[behavior['type'] == 'pay']['sku_id'].unique())].groupby('sku_id')['type'].value_counts().unstack(fill_value=0)
sku_df['total'] = sku_df.sum(axis=1)
sku_df['avg_beha'] = round((sku_df['total'] / sku_df['pay']), 2)
复制代码
fig, ax = plt.subplots(figsize=[8,6])
sns.scatterplot(x='avg_beha', y='pay', data=sku_df, palette='Set1')
ax.set_xscale("log")
ax.set_yscale("log")
plt.xlabel('平均操作次数')
plt.ylabel('销量')
复制代码
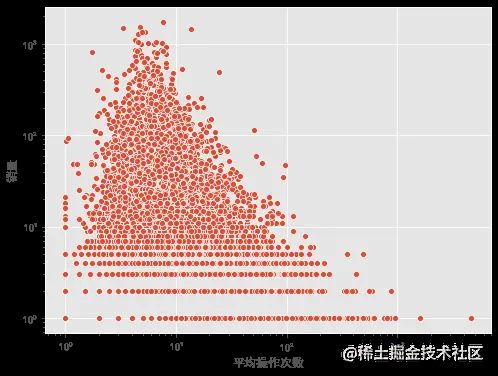
左下角操作少购买少,属于冷门购买频率较低的产品。
左上角操作少购买多,属于快消类产品,可选择品牌少,少数品牌垄断的行业。
右下角操作多购买少,品牌多,但是购买频率低,应为贵重物品类。
右上角操作多购买多,大众品牌,可选多,被购买频次高。
# 商品销量排行
sku_num = (behavior[behavior['type'] == 'pay'].groupby('sku_id')['type'].count().to_frame()
.rename(columns={'type':'total'}).reset_index())
# 销量大于1000的商品
topsku = sku_num[sku_num['total'] > 1000].sort_values(by='total',ascending=False)
# 单个用户共购买商品种数
sku_num_per_user = (behavior[behavior['type'] == 'pay']).groupby(['user_id'])['sku_id'].nunique()
复制代码
topsku.set_index('sku_id').style.bar(color='skyblue',subset=['total'])
复制代码
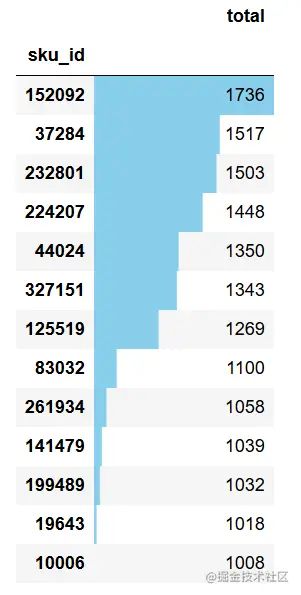
在计算周期内订单数均突破1000以上的共有13款产品,其中152092这款产品订单数最高为1736. 推出商品组合有优惠等,提高单个用户购买产品种数。
# SQL
# sku销量排行
SELECT sku_id, COUNT(type) sku_num FROM behavior_sql
WHERE type = 'pay'
GROUP BY sku_id
HAVING sku_num > 1000
ORDER BY sku_num DESC;
复制代码
7. RFM用户分层
#RFM
#由于缺少M(金额)列,仅通过R(最近一次购买时间)和F(消费频率)对用户进行价值分析
buy_group = behavior[behavior['type']=='pay'].groupby('user_id')['date']
复制代码
#将2018-04-13作为每个用户最后一次购买时间来处理
final_day = datetime.date(datetime.strptime('2018-04-14', '%Y-%m-%d'))
复制代码
#最近一次购物时间
recent_buy_time = buy_group.apply(lambda x:final_day-x.max())
recent_buy_time = recent_buy_time.reset_index().rename(columns={'date':'recent'})
recent_buy_time['recent'] = recent_buy_time['recent'].map(lambda x:x.days)
复制代码
#近十五天内购物频率
buy_freq = buy_group.count().reset_index().rename(columns={'date':'freq'})
复制代码
RFM = pd.merge(recent_buy_time,buy_freq,on='user_id')
复制代码
RFM['R'] = pd.qcut(RFM.recent,2,labels=['1','0'])
#天数小标签为1天数大标签为0
RFM['F'] = pd.qcut(RFM.freq.rank(method='first'),2,labels=['0','1'])
#频率大标签为1频率小标签为0
复制代码
RFM['RFM'] = RFM['R'].astype(int).map(str) + RFM['F'].astype(int).map(str)
复制代码
dict_n={'01':'重要保持客户',
'11':'重要价值客户',
'10':'重要挽留客户',
'00':'一般发展客户'}
复制代码
#用户标签
RFM['用户等级'] = RFM['RFM'].map(dict_n)
复制代码
RFM_pie = RFM['用户等级'].value_counts().reset_index()
RFM_pie['Rate'] = RFM_pie['用户等级'] / RFM_pie['用户等级'].sum()
复制代码
fig, ax = plt.subplots(figsize=[16,6])
plt.pie(RFM_pie['Rate'], labels = RFM_pie['index'], startangle = 90,autopct="%1.2f%%",
counterclock = False,colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'])
plt.axis('square')
plt.title('RFM用户分层')
复制代码
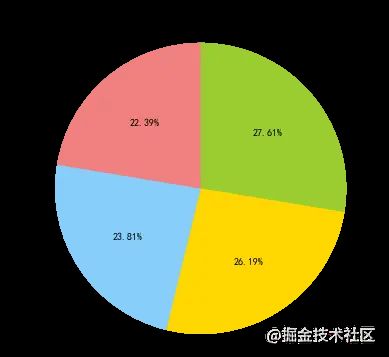
不同类型用户占比差异较小,应提升重要价值各户的占比,减小一般发展客户的占比。 通过RFM模型对用户价值进行分类,对不同价值用户应采取不同的运营策略,对于重要价值客户来说,要提高该部分用户的满意度,服务升级,发放特别福利,增大该部分用户留存率,在做运营推广时也要给与特别关注,避免引起用户反感。 对于重要保持客户,他们购物频次较高,但最近一段时间没有消费,可以推送相关其他商品,发放优惠卷、赠品和促销信息等,唤回该部分用户。 对于重要挽留客户,他们最近消费过,但购物频次较低,可以通过问卷有礼的方式找出其对平台的不满,提升购物体验,增大用户粘性。 对于一般发展客户,做到定期发送邮件或短信唤回,努力将其转化为重要保持客户或重要挽留客户。
# SQL
# RFM
CREATE VIEW RF_table AS
SELECT user_id, DATEDIFF('2018-04-14',MAX(date)) AS R_days,
COUNT(*) AS F_count
FROM behavior_sql WHERE type='pay' GROUP BY user_id;
SELECT AVG(R_days), AVG(F_count)
FROM RF_table
create view RF_ layer as
SELECT user_id, (CASE WHEN R_days < 7.1697 THEN 1 ELSE 0 END) AS R,
(CASE WHEN F_count < 1.2129 THEN 0 ELSE 1 END) AS F
FROM RF_table
ORDER BY user_id DESC;
create view customer_value as
select user_id, R, F, (CASE WHEN R=1 and F=1 THEN "重要价值客户"
WHEN R=1 and F=0 THEN "重要挽留客户"
WHEN R=0 and F=1 THEN "重要保持客户"
WHEN R=0 and F=0 THEN "一般发展客户" ELSE 0 END) as 用户价值
FROM RF_ layer;
SELECT * FROM customer_value;
复制代码
五. 总结
1.可以增加渠道推广投入,进行精准人群推广,推出新用户福利,吸引新用户,推出团购、分享有礼等活动促进老带新,推出促销活动刺激老用户,提高访客数和浏览量。提高产品质量,提高商品详情页对用户的吸引力,降低跳失率。
2.根据用户操作随时间变化规律来开展营销活动,使活动更容易触达用户,在用户访问高峰期多推送用户感兴趣商品。
3.复购率较低,说明用户对平台购物体验不满,需要找出用户槽点,提高用户购物满意度,优化商品推送机制,对老用户给予特别福利,提高他们所享受权益。转化率也偏低,需要改善平台搜索机制降低提高搜索效率,优化购物路径降低购物复杂度,改善商品详情信息展示方式便于信息的获取。
4.留存率相对稳定,为进一步提高留存率,可以定期推出秒杀活动,推出专享优惠券,推出签到有礼环节,增加用户浏览时长和深度,提高用户粘性。分析用户对产品的真实使用感受与评价,提高用户忠诚度。
5.通过RFM对用户进行分层,将用户从一个整体拆分成特征明显的群体,有针对性的采取不同的营销方法进行精准化营销,用有限的公司资源优先服务于公司最重要的客户。