【读点论文】DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learn
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
Abstract
-
虽然自监督表示学习(Self-Supervised representation Learning, SSL)受到了社会各界的广泛关注,但最近的研究认为,当模型大小减小时,其性能会急剧下降。由于目前的SSL方法主要依靠对比学习来训练网络,在这项工作中,我们提出了一种简单而有效的方法,称为蒸馏对比学习(DisCo)来缓解这个问题。
-
具体来说,我们发现主流SSL方法的最终固有嵌入包含了最丰富的信息,并提出通过约束学生的最后嵌入与教师的最后嵌入一致来提取最终嵌入,从而最大限度地将教师的知识传递给轻量级模型。
-
此外,我们还发现存在“蒸馏瓶颈”现象,并提出通过扩大嵌入维数来缓解这一问题。由于MLP仅在SSL阶段存在,因此我们的方法不会在下游任务部署期间向轻量级模型引入任何额外参数。实验结果表明,我们的方法在所有轻量化模型上都大大超过了最先进的方法。
-
特别是,当分别使用ResNet-101/ResNet-50作为老师来教授EfficientNet-B0时,EfficientNet b0在ImageNet上的线性结果分别提高了22.1%和19.7%,与参数少得多的ResNet-101/ResNet-50非常接近。代码可从 https://github.com/Yuting-Gao/DisCo-pytorch 获得。
-
论文地址:[2104.09124v7] DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning (arxiv.org)
-
该论文已被 ECCV 2022 录用!
Introduction
-
深度学习在计算机视觉任务中取得了巨大的成功,包括图像分类、目标检测和语义分割。这种成功在很大程度上依赖于人工标记的数据集,而人工标记的数据集既耗时又昂贵。因此,越来越多的研究者开始探索如何更好地利用现成的未标记数据。其中,自监督学习(Self-supervised Learning, SSL)是一种利用代理信号作为监督,探索数据本身所包含信息的有效方法。通常,在大量未标记数据上使用自监督方法对网络进行预训练,并对下游任务进行微调后,下游任务的性能将得到显著提高。因此,SSL受到了社会各界的广泛关注,并提出了许多方法。
-
其中,基于对比学习的方法以其优越的效果正在成为主流。这些方法在相对较大的网络上不断刷新SOTA结果,但同时在一些轻量级模型上却不尽人意。例如,MobileNet-v3-Large/ResNet-152的参数个数为5.2M/ 574M,使用MoCo-V2在ImageNet上相应的线性评价top-1精度为36.2%/74.1%。与完全监督的同行75.2%/78.57%相比,MobileNet-v3Large的结果远不能令人满意。同时,在实际场景中,由于硬件资源有限,有时只能部署轻量级模型。因此,提高小模型的自监督表示学习能力具有重要意义。
-
知识蒸馏是将大模型(教师)所学到的知识转移到小模型(学生)的有效方法。近年来,一些自监督表示学习方法利用知识蒸馏来提高小模型的有效性。SimCLR-V2在微调阶段使用logits以特定于任务的方式传递知识。CompRess和SEED在动态维护的队列上模拟教师和学生模型之间的相似性得分分布。虽然蒸馏是有效的,但有两个因素显著影响结果,即学生最需要哪些知识以及如何传递这些知识。在这项工作中,我们对这两个方面提出了新的见解。
-
在目前主流的基于对比学习的SSL方法中,在编码器后加入多层感知器(MLP)以获得低维嵌入。对该嵌入进行了训练损失和精度评估。因此,我们假设这个最终嵌入包含最有成果的知识,应该被视为知识迁移的首选。
-
为了实现这一点,我们提出了一个简单而有效的蒸馏对比学习(DisCo)框架,在预训练阶段将这些知识从大型模型转移到轻量级模型。DisCo将教师获得的MLP嵌入作为知识,通过MSE loss约束学生的相应嵌入与教师的嵌入一致,将其注入到学生中。
-
此外,我们发现学生的MLP中隐含层的预算维度可能会导致知识传播瓶颈。我们将这种现象称为“蒸馏瓶颈”,并提出通过扩大嵌入维数来缓解这一问题。从信息瓶颈的角度来看,这种简单而有效的操作涉及到自监督学习设置下的模型泛化能力。值得注意的是,我们的方法只在预训练阶段引入了少量额外的参数,但在微调和部署阶段,由于去掉了MLP层,因此没有额外的计算负担。
-
实验结果表明,DisCo可以有效地将教师的知识传递给学生,使学生提取的表征更具泛化性。我们的方法很简单,将其合并到现有的基于对比的SSL方法中可以带来显著的收益。我们的贡献总结如下:
-
我们提出了一种简单而有效的自监督蒸馏方法来提高轻量级模型的表示能力。
-
我们发现在自监督蒸馏阶段存在蒸馏瓶颈现象,并提出通过扩大嵌入维数来缓解这一问题。
-
我们在轻量级模型上实现了最先进的SSL结果。特别是,EfficientNet- b0在ImageNet上的线性评价结果非常接近ResNet-101/ResNet-50,而EfficientNet- b0的参数数量仅为ResNet101/ResNet-50的9.4%/16.3%。
-
-
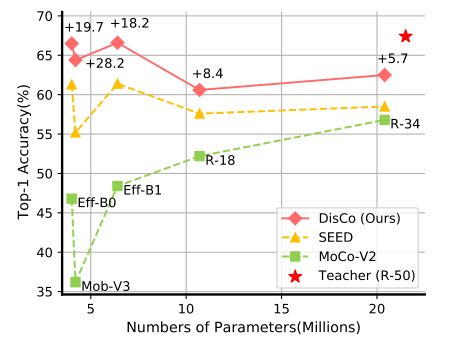
- 不同网络架构下ImageNet top-1线性评价精度。我们的方法大大超过了直接使用MoCo-V2的结果,也大大超过了最先进的SEED。特别是,效率netb0的结果与ResNet-50非常接近,而效率netb0的参数数量仅为ResNet-50的16.3%。DisCo带来的改善与MoCo-V2基线进行比较。
-
自监督学习通常指的模型在大规模无标注数据上学习通用的表征,迁移到下游相关任务。因为学习到的通用表征能显著提升下游任务的性能,自监督学习被广泛用于各种场景。通常来讲,模型容量越大,自监督学习的效果越好 。反之,轻量化的模型(EfficientNet-B0, MobileNet-V3, EfficientNet-B1) 在自监督学习上效果就远不如容量相对大的模型 (ResNet50/101/152/50*2)。
-
目前提升轻量化模型在自监督学习上性能的做法主要是通过蒸馏的方式,将容量更大的模型的知识迁移给学生模型。SEED基于MoCo-V2框架,容量大的模型作为Teacher,轻量化模型作为Student,共享MoCo-V2框架中负样本空间(Queue),通过交叉熵迫使正样本与相同的负样本在Student与Teacher空间中的分布尽可能相同。CompRess还尝试了Teacher和Student维护各自的负样本空间,同时使用KL散度来拉近分布。以上方法可以有效的将Teacher的知识迁移给Student,从而提升轻量化模型Student的效果(本文会交替使用Student与轻量化模型)。
-
本文提出了 Distilled Contrastive Learning (DisCo),一种简单有效的基于蒸馏的轻量化模型的自监督学习方法,该方法可以显著提升Student的效果并且部分轻量化模型可以非常接近Teacher的性能。该方法有以下几个观察:
-
- 基于自监督的蒸馏学习,因为最后一层的表征包含了不同样本的在整个表征空间中的全局的绝对位置和局部的相对位置信息,而Teacher中的这类信息比Student更加的好,所以直接拉近Teacher与Student最后一层的表征可能是效果最好。
- 在CompRess中,Teacher 与 Student 模型共享负样本队列(1q) 与拥有各自负样本队列(2q) 差距在1%内。该方法迁移到下游任务数据集CUB200, Car192,该方法拥有各自的负样本队列甚至可以显著超过共享负样本队列。这说明,Student并没有从Teacher共享的负样本空间学习中获得足够有效的知识。Student不需要依赖来自Teacher的负样本空间。
- 放弃共享队列的好处之一,是整个框架不依赖于MoCo-V2,整个框架更加简洁。Teacher/Student 模型可以与其他比MoCo-V2更加有效的自监督/无监督表征学习方法结合,进一步提升轻量化模型蒸馏完的最终性能。
- 目前的自监督方法中,MLP的隐藏层维度较低可能是蒸馏性能的瓶颈。在自监督学习与蒸馏阶段增加这个结构的隐藏层的维度可以进一步提升蒸馏之后最终轻量化模型的效果,而部署阶段不会有任何额外的开销。将隐藏层维度从512->2048,ResNet-18可以显著提升3.5%。
-
Related Work
Self-supervised Learning
-
自监督学习(Self-supervised learning, SSL)是一种通用框架,它从数据本身学习高语义模式,而不需要任何来自人类的标记。目前的方法主要依赖于三种范式,即pretext tasks、基于对比和基于聚类。
-
pretext tasks:基于pretext paradigm的方法侧重于设计更有效的替代任务,包括识别patch是否从同一图像中裁剪的example - cnn,预测输入图像旋转程度的Rotation,将打乱后的patch放回到原始位置的Jigsaw,以及恢复输入图像中受周围条件影响的缺失部分的Context encoder。
-
基于对比。基于对比的方法在自监督表示学习上表现出了令人印象深刻的性能,它强制相同输入的不同视图在特征空间中更接近。SimCLR表明,可以通过应用强数据增强、使用更大批量的负样本进行训练以及在全局平均池化后加入投影头(MLP)来增强自监督学习。然而,SimCLR依赖于非常大的批处理大小来实现相当的性能,并且不能广泛应用于许多实际场景。MoCo认为对比学习是一个查找字典,使用记忆库来保持负样本的一致表示。因此,MoCo可以在不需要大规模批量的情况下获得更优的性能,实现起来更可行。BYOL在网络的一个分支中引入了一个预测器来打破对称性并避免平凡解。DINO将对比学习应用于视觉transformer。
-
基于聚类。聚类是无监督表示学习中最有前途的方法之一。DeepCluster使用k-means赋值生成伪标签,迭代地对特征进行分组并更新网络的权值。DeeperCluster扩展到大型未经整理的数据集,以捕获互补统计。与以往工作不同的是,为了最大限度地提高伪标签与输入数据之间的互信息,SeLa将伪标签分配作为最优传输的一个实例。SwAV表示将表示映射到原型向量,原型向量是在线分配的,能够扩展到更大的数据集。
-
虽然主流方法SimCLR-V2、MoCoV2、BYOL和SwAV属于不同的自监督分类,但它们有四个共同点:
-
1)一幅图像有两个视图,
-
2)两个特征提取编码器,
-
3)两个投影头将表示映射到较低维空间,
-
4)两个低维嵌入被视为一对正样本,可以认为是一个对比过程。
-
-
然而,所有这些方法在轻量级模型上都会遭受性能的急剧下降,这是我们在这项工作中试图补救的。
Knowledge Distillation
-
知识蒸馏(Knowledge distillation, KD)试图将知识从一个较大的教师模型转移到一个较小的学生模型。根据知识的形式,可以将其分为基于逻辑的、基于特征的和基于关系的三类。
-
Logits-based。Logits是指网络分类器的输出。KD提出通过最小化类别分布的kl -散度,让学生模仿老师的逻辑。
-
基于特征的。基于特征的方法直接将知识从教师的中间层传递给学生。FitNets将教师学习到的中间表征作为提示,通过最小化表征之间的均方误差,将知识传递给更瘦、更深的学生。AT提出将教师的空间注意力作为知识,让学生将注意力集中在教师所关注的区域。SemCKD自适应地选择更合适的师生表示对。
-
Relation-based:基于关系的方法探索数据之间的关系,而不是单个实例的输出。RKD将一个批次内具有距离和角度蒸馏损失的输入数据的相互关系从教师传递给学生。IRG提出使用关系图来进一步表达关系知识。
SSL meets KD
-
最近,一些研究将自我监督学习和知识蒸馏结合起来。CRD在不同模态之间引入了传输成对关系的对比损失。SSKD让学生模拟转换后的数据和自我监督任务,从而转移更丰富的知识。
-
上述工作将自我监督作为辅助任务,进一步推动全监督设置下的知识升华过程。CompRess和SEED尝试采用知识蒸馏的方法来提高小模型的自监督视觉表示学习能力,利用MoCo中的负样本队列来约束学生的正样本与负样本的分布,使其与教师的分布一致。
-
然而,CompRess和SEED严重依赖于MoCo框架,这意味着在蒸馏过程中必须始终保留内存库。我们的方法还旨在通过提取来提高轻量级模型的自监督表示学习能力,然而,我们没有限制自监督框架,因此更加灵活。此外,在相同设置下,我们的方法在所有轻量级模型上都大大超过SEED。
Method
- 在本节中,我们将介绍轻量级模型上的蒸馏对比学习(DisCo)框架。我们首先对基于对比的SSL进行了一些初步的介绍,然后介绍了DisCo的总体架构以及DisCo如何将知识从教师传递给学生。最后,我们介绍了DisCo如何与现有的基于对比的SSL方法相结合。
Preliminary on Contrastive Learning Based SSL
-
主流的基于对比学习的SSL方法有四个共同的特点。
-
两个视图:一个输入图像x通过两个剧烈的数据增强操作转换成两个视图 v v v和 v ′ v' v′。
-
两个编码器:两个增强视图输入到两个相同结构的编码器,一个是可学习的基编码器s(·),另一个m(·)根据基编码器更新,共享或动量更新。这里的编码器可以使用任何网络架构,比如常用的ResNet。给定一幅输入图像,编码器最后一次全局平均池化得到的提取表示记为Z,其维数为D.
-
投影头:两个编码器后面都有一个小的投影头 p ( ⋅ ) p(·) p(⋅),它将表示Z映射到包含几个线性层的低维嵌入E。可表示为 E = p ( Z ) = W ( n ) ⋅ ⋅ ⋅ ( σ ( W ( 1 ) Z ) ) E = p(Z) = W_{(n)}···(σ(W_{(1)}Z)) E=p(Z)=W(n)⋅⋅⋅(σ(W(1)Z)),其中W为线性层的权重参数,n为大于等于1的层数,σ为非线性函数ReLU。SimCLR-V2和MoCo-V2解决了投影头的重要性。在MoCo-V2之后,投影头的默认配置是两个线性层,其中第一层保持原始特征维数D,第二层将特征维数降为128。
-
损失函数:在得到这两个视图的最终嵌入后,将它们作为一对正样本来计算损失。
-
Overall Architecture
-
DisCo的框架如下图所示,由三个编码器和投影头组成。中间的学生s(·)是我们想要改进的编码器,平均学生m(·)根据s(·)更新,教师t(·)是自监督预训练的大型编码器,用作蒸馏中的教师。
-

-
提出的方法的框架是DisCo。首先通过两次激烈的数据增强操作将一张图像转换为两个视图。在原有的约束性SSL部分之外,引入了一个自我监督的预训练教师,并要求可学习的学生和冻结的教师得到的最终嵌入在每个视图中都是一致的。
-
对于每个输入图像x,首先通过两次剧烈的数据增强操作将其转换为两个视图v和v0。一方面,将v输入到s(·)和t(·),生成两个表示 Z s = s ( v ) , Z t = t ( v ) Z_s = s(v), Z_t = t(v) Zs=s(v),Zt=t(v),然后在投影头之后,将这两个表示分别映射到低维嵌入, E s = p s ( Z s ) , E t = p t ( Z t ) E_s = p_s(Z_s), E_t = p_t(Z_t) Es=ps(Zs),Et=pt(Zt)。另一方面,将 v ′ v' v′ 同时输入到s(·)、m(·)和t(·),经过编码和投影,得到三个低维向量 E s ′ = p s ( s ( v ′ ) ) 、 E m ′ = p m ( m ( v ′ ) ) E'_s = p_s(s(v'))、E'_ m = p_m(m(v')) Es′=ps(s(v′))、Em′=pm(m(v′))和 E t ′ = p t ( t ( v ′ ) ) E'_t = p_t(t(v')) Et′=pt(t(v′))。
-
E m ′ E'_m Em′和 E s E_s Es是两个不同视图的嵌入,它们被视为一对正样本,在现有的SSL方法中被拉到一起。 E s E_s Es和 E t E_t Et, E s ′ E'_s Es′和 E t ′ E'_t Et′是同一视图的学生和教师的两对嵌入,在提取过程中,每对嵌入都被约束为一致。
-
如上图所示,通过数据增广 (Data Augmentation) 操作将图像生成为两个视图 (View)。 除了自监督学习,还引入一个自监督学习获得的Teacher模型。要求相同样本的相同视图,经过Student和固定参数的Teacehr的最终表征保持一致。在本文的主要实验中,自监督学习基于MoCo-V2 (Contrastive Learning),而保持相同样本通过Teacher与Student的输出表征的表征相似是通过一致性正则化(Consistency Regularization)。本文采用均方误差来使Student学习到样本在对应Teacher空间中的分布。
-
Distilling Procedure
-
在大多数基于对比的SSL方法中,损失函数的计算和精度的评估都是在最后的嵌入向量E上进行的。因此,我们假设最后的嵌入向量E包含了最丰富的知识,在提取时应该首先考虑。
-
对于自监督预训练的教师模型,我们将上次嵌入中的知识提取到学生中,即对于视图v和视图 v ′ v' v′,冻结的教师和可学习的学生输出的嵌入向量应该是一致的。具体来说,我们使用一致性正则化项将嵌入向量 E s E_s Es拉得更接近 E t E_t Et,将 E s ′ E'_s Es′拉得更接近 E t ′ E'_t Et′。
-
L d i s = ∣ ∣ E s − E t ∣ ∣ 2 + ∣ ∣ E s ′ − E t ′ ∣ ∣ 2 , ( 1 ) L_dis=||E_s-E_t||^2+||E'_s-E'_t||^2,(1) Ldis=∣∣Es−Et∣∣2+∣∣Es′−Et′∣∣2,(1)
-
为了验证嵌入E包含最有意义的知识,我们在下表中实验了其他几种常用的蒸馏方案。结果证明,我们传递的知识和传递的方式确实是最有效的。
-

-
在ImageNet上对不同蒸馏方法的top-1精度(%)进行线性评价。
-
-
蒸馏的瓶颈。在我们的蒸馏实验中,我们发现了一个有趣的现象。当该学生的编码器为ResNet-18/34时,采用默认的MLP配置,即编码器输出的嵌入维数从D投影到D再投影到128时,DisCo的结果并不令人满意。我们假设这种退化是由于MLP中隐藏层的维度太小造成的,并将这种现象称为蒸馏瓶颈。
-
在下图中,我们展示了ResNet-18/34、EfficientNet-B0/B1、MobileNet-v3Large和ResNet-50/101/152的投影头的默认配置。可以看出,与其他网络相比,ResNet-18/34的隐藏层维度太小。
-
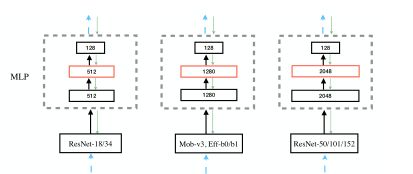
-
Default MLP of multiple networks.
-
-
为了缓解蒸馏瓶颈问题,我们扩展了MLP中隐藏层的维度。值得注意的是,该操作仅在自监督蒸馏阶段引入少量参数,并且在微调和部署过程中直接丢弃MLP,这意味着不会带来额外的计算负担。我们在下表中通过实验验证了这样一个简单的操作可以带来显著的收益。
-

-
在ImageNet上线性评价前1的精度(%)。MLPd表示MLP的隐藏维数,-表示直接移除MLP的隐藏层。
-
-
这种操作可以从信息瓶颈(Information Bottleneck, IB)的角度来解释。[Opening the black box of deep neural networks via information,Evaluating capability of deep neural networks for image classification via information plane]利用IB通过可视化互信息 ( I ( X ; T ) a n d I ( T ; Y ) ) (I(X;T) and I(T;Y)) (I(X;T)andI(T;Y)),其中I(X;T)为输入与输出之间的互信息,I(T;Y)为输出与标签之间的互信息。深度网络的训练可以用两个阶段来描述:第一个拟合阶段,网络记忆输入的信息,导致I(X)的增长和I(T;Y)在随后的压缩阶段,网络去除输入的不相关信息以更好地泛化,导致I(X)减小。
-
通常,在压缩阶段,I(X;T)可以表示模型的泛化能力,而I(T;Y)表示模型拟合标签的能力。在一个下游传递分类任务的信息平面上,我们用预训练蒸馏阶段的隐藏层的不同维数来可视化模型的压缩阶段。下图的结果显示了两个有趣的现象:
-

-
训练压缩阶段从过渡点到收敛点的互信息路径。T表示过渡点,C(X%)表示Cifar10上top-1精度为X%的收敛点。I(T;Y)相似但I(X;T)较小的点可以更好地推广。
-
1.隐藏层不同维数的模型i (T,Y)非常相似,表明模型具有几乎相等的拟合标签的能力。
-
2.隐藏层中维数越大的模型I(X;T)越小,表明有较强的泛化能力。
-
-
这些现象表明,在自监督迁移学习环境下,MLP确实与模型泛化能力有关。
Overall Objective Function
-
总体目标函数定义如下:
-
L = L d i s + λ L c o , ( 2 ) L=L_{dis}+\lambda L_{co},(2) L=Ldis+λLco,(2)
-
其中 L d i s L_{dis} Ldis 来自蒸馏部分, L c o L_{co} Lco 可以是任何SSL方法的对比损失, λ λ λ 是控制蒸馏损失和对比损失权重的超参数。在我们的实验中, λ λ λ 被设为1。由于实现简单,我们在实验中使用MoCo-V2作为测试平台,没有额外的说明。
-
Experiments
Settings
-
数据集。所有的自监督预训练实验都在ImageNet上进行。下游分类任务则在Cifar10和Cifar100上进行实验。下游检测任务在PASCAL VOC和MSCOCO上进行实验,分别使用train+val/test和train2017/val2017进行训练/测试。对于下游的分割任务,提出的方法在MS-COCO上进行了验证。
-
Teacher Encoders. 使用四个大型编码器作为教师,ResNet-50(22.4M), ResNet-101(40.5M), ResNet152(55.4M), ResNet-50*2(55.5M),其中X(Y)表示编码器X有Y百万参数,Y不考虑线性层。
-
Student Encoders. 五个广泛使用的小型有效网络分别是student、EfficientNet-B0(4.0M)、MobileNet-v3-Large(4.2M)、EfficientNet-B1(6.4M)、ResNet-18(10.7M)和ResNet-34(20.4M)。
-
Teacher Pre-training Setting. ResNet-50/101/152使用带有默认超参数的MoCo-V2进行预训练。在SEED之后,ResNet-50和ResNet-101训练了200个epoch, ResNet-152训练了400个epoch。ResNet-50*2由SwAV预训练,SwAV是一个开源模型,训练了800个epoch。
-
Student Fine-tuning Setting. 为了在ImageNet上进行线性评估,学生被微调为100个epoch。EfficientNet- b0 /EfficientNet b1 /MobileNet-v3-Large的初始学习率为3,ResNet-18/34的初始学习率为30。对于Cifar10和Cifar100的线性评估,初始学习率为3,所有模型都微调了100个epoch。采用SGD作为优化器,在60次和80次时学习率分别降低10%进行线性评估。对于下游的检测和分割任务,遵循SEED,对所有参数进行微调。对于VOC的检测任务,初始学习率为0.1,预热迭代200次,在18k, 222k步时衰减10。检测器训练48k步,批大小为32。在SEED之后,图像的尺度在训练期间随机从[400,800]中采样,在推理时为800。对于COCO上的检测和实例分割,模型被训练了180k次迭代,初始学习率为0.11,在训练过程中随机从[600,800]中抽取图像的尺度。
Linear Evaluation
-
我们在ImageNet上进行了线性评估来验证我们方法的有效性。如下表所示,DisCo提取的学生模型比MoCo-V2 (Baseline)预训练的模型要好得多。
-

-
ImageNet在不同的学生架构上使用线性分类测试准确率(%)。♦表示教师/学生模型是用MoCo-V2预训练的,这是我们的实现;†表示教师是用SwAV预训练的,这是一个开源模型。当使用R50*2作为教师时,SEED提取800个epoch, DisCo提取200个epoch。绿色下标表示与MoCo-V2基线相比的改善。
-
-
此外,在相同设置下,DisCo超过了最先进的SEED,超过了教师ResNet-50/101/152的各种学生模型,特别是在ResNet-50蒸馏的MobileNet-v3-Large上,在top-1精度下差异为9.2%。当使用R50*2作为教师时,SEED提取了800个epoch, DisCo仍然提取了200个epoch,但使用DisCo的EfficientNet-B0、ResNet-18和ResNet-34的结果也超过了SEED。
-
在EfficientNet-B1和MobileNet-v3-Large上的性能与蒸馏时代密切相关。例如,当对EfficientNet-B1进行290个epoch的蒸馏时,top-1准确率达到70.4%,超过了SEED;当对MobileNet-v3-Large进行340个epoch的蒸馏时,top-1准确率达到64%。
-
我们相信,当DisCo蒸馏800个epoch时,结果会进一步改善。此外,由于CompRess使用的老师比SEED和我们训练的时间长600个epoch,提炼的时间长400个epoch,因此进行比较是不公平的,因此我们没有在表中报告结果。此外,当DisCo使用更大的模型作为老师时,学生会得到进一步的提高。
-
例如,使用ResNet-152代替ResNet-50作为教师,ResNet-34从62.5%提高到68.1%。值得注意的是,当使用ResNet101/ResNet-50作为教师时,EfficientNet- b0的线性评价结果与教师非常接近,而EfficientNet- b0的参数数量仅为ResNet101/ResNet-50的9.4%/16.3%。
Semi-supervised Linear Evaluation
-
在SEED之后,我们在半监督设置下评估了我们的方法。ImageNet训练数据的两个1%和10%采样子集(每个类分别为~ 12.8和~ 128张图像)用于微调学生模型。如下图所示,DisCo提炼的学生模型在任何数量的标记数据下都优于基线。此外,DisCo还显示了不同分数注释下的一致性,即学生作为教师总是受益于更大的模型。更多的标签将有助于提高学生模型的最终性能,这是预期的。
-

-
1%、10%和100%训练数据下半监督线性评价的ImageNet top-1准确率(%)。教师网络参数个数为0的点为MoCo-V2未蒸馏的结果。
-
Transfer to Cifar10/Cifar100
-
为了分析DisCo获得的表征的泛化,我们进一步以ResNet-18/EfficientNet-B0为学生,ResNet-50/ResNet101/ResNet152为教师,对Cifar10和Cifar100进行了线性评价。由于Cifar数据集的图像分辨率为32 × 32,因此在输入模型之前,所有图像都通过双三次重采样调整为224 × 224,如下[Seed: Self-supervised distillation for visual representation]。
-
结果如下图所示,可以看到,在不同的学生和教师架构上和Cifar100上,所提出的DisCo大大超过了MoCo-V2基线。此外,与目前最先进的SEED方法相比,我们的方法也有显著的改进。值得注意的是,随着教师水平的提高,DisCo带来的提升也更加明显。Cifar10和Cifar100的性能趋势一致。
-

-
Top-1 accuracy of students transferred to Cifar100 without and with distillation from different teachers.
-
Transfer to Detection and Segmentation
-
我们还对检测和分割任务进行了实验,以进行泛化分析。基于C4的Faster R-CNN用于VOC上的目标检测,Mask R-CNN用于COCO上的目标检测和实例分割。结果如下表所示。在目标检测方面,我们的方法对VOC和COCO数据集都有明显的改进。此外,正如SEED所言,相比于VOC, COCO的改进相对较小,因为COCO训练数据集有118k张图像,而VOC只有16.5k张训练图像,因此权值初始化带来的增益相对较小。在实例分割任务上,DisCo也显示出优越性。
-

-
以ResNet-34为骨干的VOC07测试和COCO val2017的目标检测和实例分割结果。‡表示我们的实施。绿色下标表示与MoCo-V2基线相比的改善。
-
Distilling BottleNeck Phenomenon
-
在自监督蒸馏阶段,我们首先使用ResNet-50作为教师,尝试在MoCo-V2的默认MLP配置下对小模型进行蒸馏,结果如下表所示,用DisCo *表示。
-

-
在ImageNet上线性评价前1的精度(%)。
-
-
值得注意的是,DisCo*中隐藏层的维度与SEED完全相同。可以看出,与SEED相比,DisCo*在EfficientNet-B0和MobileNet-v3-Large上显示出优越的结果,并且在ResNet-18上具有相当的结果。然后我们将学生的MLP中隐含层的维度展开,使其与老师的MLP一致,即2048D,可以看出结果可以进一步提高,记录在第三行。特别是,这次扩展操作分别为ResNet-18和ResNet-34带来了3.5%和3.6%的收益。
-
IB视角下的理论分析。在下图中,在下游Cifar10分类任务上,我们将同一位老师在信息平面上提炼的具有不同隐藏维度的ResNet-18/34的压缩阶段可视化。我们使用分箱策略来估计互信息。可以看出,当我们将ResNet-18和ResNet-34的MLP中的隐藏维数从512D调整到2048D时,I(X;T)变小,而I(T;Y)基本不变,这说明在自监督迁移学习环境下,扩大隐维可以使学生模型更加一般化。
Ablation Study
-
在本节中,我们验证了DisCo中两个重要模块的有效性,即蒸馏损失和MLP隐藏维数的扩展,结果如下表所示。由此可见,蒸馏损失会带来本质的变化,结果会有很大的改善。即使只有蒸馏损失,也能取得良好的效果。此外,随着隐藏维数的增加,top-1的准确率也会增加,但当隐藏维数已经很大时,增长趋势会放缓。
-

-
在ImageNet上线性评价前1的精度(%)。MLPd表示MLP的隐藏维数,- 表示直接移除MLP的隐藏层。
-
Comparison against other Distillation
-
为了验证该方法的有效性,我们将其与三种广泛使用的蒸馏方案进行了比较,即:
-
1)以AT表示的注意力转移,
-
2)以RKD表示的关系知识蒸馏,
-
3)以KD表示的知识蒸馏。
-
-
A - T和RKD分别是基于特征和基于关系的,可以在自监督预训练阶段使用。KD是一种基于逻辑的方法,只能在监督微调阶段使用。对比结果如下表所示。单知识是指单独使用这些方法中的一种,可以看出,所有的蒸馏方法都可以改善基线,但DisCo的增益最显著,这表明DisCo选择转移的知识和传输方式确实更有效。
-

-
在ImageNet上对不同蒸馏方法的top-1精度(%)进行线性评价。
-
-
然后,我们还尝试将DisCo与其他方案相结合,将教师的多种知识传递给学生。可以看出,将DisCo与AT/RKD/KD相结合可以大大提高性能,这进一步证明了DisCo的有效性。
More SSL Methods
-
为了演示我们方法的多功能性,我们进一步试验了两种SSL方法,它们与我们在前几节中使用的MoCo-V2基线完全不同。
-
i) SwAV用于证明对学习范式的兼容性,其中差异是在集群而不是实例之间测量的;
-
ii)使用DINO来证明对骨干类型的兼容性,其中编码器是视觉transformer,而不是常用的CNN,如下表所示。
-

-
以DINO为试验台,在ImageNet上线性评价top-1精度(%)。vitc -small和XCiT-small用DINO预训练100 epoch。可以看出DisCo并不局限于特定的SSL方法,在大多数流行的SSL框架下都能带来显著的改进。
-
-
本文还可视化了相同样本在 经过MoCo-2得到的EfficientNet-B0, 经过MoCo-V2得到的ResNet-50,以及本文的方法得到的EfficientNet-B0的表征。可以观察到ResNet-50形成比EfficientNet-B0更多的分离簇,单独使用MoCo-V2,本文的方法得到的EfficientNet-B0有更清晰的分离簇,也与ResNet-50更接近。

Conclusion
- 在本文中,我们提出了蒸馏对比学习(DisCo)来弥补轻量级模型上的自监督学习。该方法约束轻量化学生的最终嵌入与教师的最终嵌入一致,以最大限度地传递教师的知识。DisCo不局限于特定的对比学习方法,可以在很大程度上纠正学生的表现。
B0的表征。可以观察到ResNet-50形成比EfficientNet-B0更多的分离簇,单独使用MoCo-V2,本文的方法得到的EfficientNet-B0有更清晰的分离簇,也与ResNet-50更接近。