如何编写接口自动化框架系列通过yaml来管理测试用例(四)
本文是接口自动化测试框架系列篇的第四篇 ,主要介绍yaml包的使用 。自动化测试的本质是将功能测试用例交给代码去
目录
1. yaml介绍?
2.python中的yaml包
3.项目中使用yaml包
4 项目总结
执行 ,测试人员往往是在自动化框架添加对应的测试用例即可(也叫测试脚本)。而维护测试用例的工具可能txt、excel、json、py或者yaml文件等。 当然,不同的公司、不同的项目、不同的测试人使用的工具也不同 。
曾经听一个前同事讲,有一次去面试自动化工程师时就被问到了如何管理测试用例 ?他滔滔不绝的说了半天如何使用excel去管理 ,结果面试官当场就问为什么不用yaml ,瞬间感觉就被鄙视了 。当然,面试时不应该通过一个工具判断应聘者的技术水平 ,但反过来说 ,用yaml来管理测试用例确实有着它的一些优势 ,同时个人认为,目前自动化测试管理测试数据和用例最好的工具就是yaml了 。
1. yaml介绍?
1.1 什么是yaml
YAML 是一种数据序列化语言,它的设计简洁、易于理解、可读性好,故很多开发人员使用它来做配置文件 。它还可以与其他编程语言结合使用,比如JavaScript、java、python等。YAML 文件使用 .yml 或 .yaml 扩展名,并遵循特定的语法规则。
比如下面的这个yaml文件 ,文件名:login.yaml
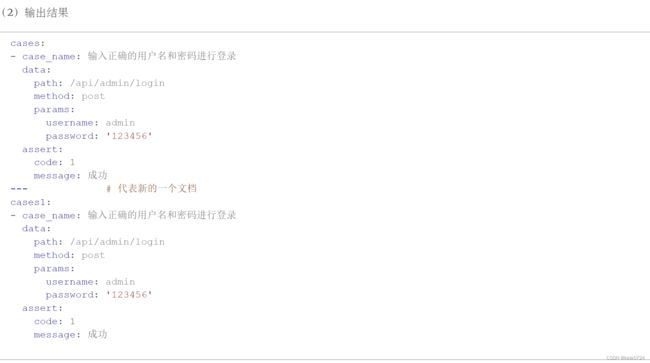
cases: - case_name: '输入正确的用户名和密码进行登录' data: path: '/api/admin/login' method: 'post' params: username: 'admin' password: '123456' assert: code: 1 message: 成功
1.2 yaml语法格式
编写的yaml文件必须要符合如下的规则 ,它的基本语法规则如下。
(1)规则
大小写敏感
使用缩进表示层级关系
缩进时不允许使用Tab键,只允许使用空格。
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
# 表示注释,从这个字符一直到行尾,都会被解析器忽略。
YAML 支持的数据结构有三种。
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
纯量(scalars):单个的、不可再分的值
以下分别介绍这三种数据结构。
(2)对象
对象的一组键值对,使用冒号结构表示。在python中其实就是字典
animal: pets
转为 python如下。
{ animal: 'pets' }
Yaml 也允许另一种写法,将所有键值对写成一个行内对象。
hash: { name: Steve, foo: bar }
转为 python如下。
{ hash: { name: 'Steve', foo: 'bar' } }
(3)数组
一组连词线开头的行,构成一个数组。在python中其实就是列表
- Cat - Dog - Goldfish
转为 python如下。
[ 'Cat', 'Dog', 'Goldfish' ]
数据结构的子成员是一个数组,则可以在该项下面缩进一个空格。
- - Cat - Dog - Goldfish
转为 python如下。
[ [ 'Cat', 'Dog', 'Goldfish' ] ]
数组也可以采用行内表示法。
animal: [Cat, Dog]
转为 python如下。
{ animal: [ 'Cat', 'Dog' ] }
(4)复合结构
对象和数组可以结合使用,形成复合结构。
languages: - Ruby - Perl - Python websites: YAML: yaml.org Ruby: ruby-lang.org Python: python.org Perl: use.perl.org
转为 python 如下。
{ languages: [ 'Ruby', 'Perl', 'Python' ],
websites:
{ YAML: 'yaml.org',
Ruby: 'ruby-lang.org',
Python: 'python.org',
Perl: 'use.perl.org' } }
(5)纯量
纯量是最基本的、不可再分的值。其实就是数据类型 ,以下数据类型都属于 python的纯量。
字符串
布尔值
整数
浮点数
Null
时间
日期
数值直接以字面量的形式表示。
number: 12.30
转为 python如下。
{ number: 12.30 }
布尔值用true和false表示。
isSet: true
转为 python如下。
{ isSet: True }
null用~表示。
parent: ~
转为 python如下。
{ parent: None }
YAML 允许使用两个感叹号,强制转换数据类型。
e: !!str 123 f: !!str true
转为 python如下。
{ e: '123', f: 'true' }
(6)字符串
字符串是最常见,也是最复杂的一种数据类型。
字符串默认不使用引号表示。
str: 这是一行字符串
转为 python如下。
{ str: '这是一行字符串' }
如果字符串之中包含空格或特殊字符,需要放在引号之中。
str: '内容: 字符串'
转为 python如下。
{ str: '内容: 字符串' }
单引号和双引号都可以使用,双引号不会对特殊字符转义。
s1: '内容\n字符串' s2: "内容\n字符串"
转为 python如下。
{ s1: '内容\\n字符串', s2: '内容\n字符串' }
单引号之中如果还有单引号,必须连续使用两个单引号转义。
str: 'labor''s day'
转为 python如下。
{ str: 'labor\'s day' }
字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格。
str: 这是一段 多行 字符串
转为 python如下。
{ str: '这是一段 多行 字符串' }
多行字符串可以使用|保留换行符,也可以使用>折叠换行。
this: | Foo Bar that: > Foo Bar
转为 python代码如下。
{ this: 'Foo\nBar\n', that: 'Foo Bar\n' }
+表示保留文字块末尾的换行,-表示删除字符串末尾的换行。
s1: | Foo s2: |+ Foo s3: |- Foo
转为 python代码如下。
{ s1: 'Foo\n', s2: 'Foo\n\n\n', s3: 'Foo' }
字符串之中可以插入 HTML 标记。
message: | 段落
转为 python如下。
{ message: '\n\n 段落\n
\n' }
(7)引用
锚点&和别名*,可以用来引用。
defaults: &defaults adapter: postgres host: localhost development: database: myapp_development <<: *defaults test: database: myapp_test <<: *defaults
等同于下面的代码。
defaults: adapter: postgres host: localhost development: database: myapp_development adapter: postgres host: localhost test: database: myapp_test adapter: postgres host: localhost
&用来建立锚点(defaults),<<表示合并到当前数据,*用来引用锚点。
下面是另一个例子。
- &showell Steve - Clark - Brian - Oren - *showell
转为 python代码如下。
[ 'Steve', 'Clark', 'Brian', 'Oren', 'Steve' ]
(8)参考链接
-
YAML 语言教程 - 阮一峰的网络日志 (ruanyifeng.com)
-
YAML 1.2 规格
-
YAML from Wikipedia
1.3 yaml总结
上面算是比较全面的介绍了yaml的用法 ,在实际使用过程中,我们用的最多的应该就是它的复合结构 ,也就是对象(字典)和数组(列表的)的嵌套使用 ,而且这个嵌套的层级一多,很容易搞不清它的逻辑层次 。所以 ,把那里面最有用的提炼出来就是以下几点,用python的方式说明 :
-
见到冒号(:)就换成字典 ;
-
见到减号(-)就换成列表;
-
同一层级的减号(-)是在一个列表中,同一层级的键值对是在一个字典中 ;
-
子层级需要有有缩进来表示 ,
同样还是最开始的那个例子来说 ,通过上面的总结就可以直接转化过来 。
以下为转化后的结果
{
"cases": [
{
"case_name": "输入正确的用户名和密码进行登录",
"data": {
"path": "/api/admin/login",
"method": "post",
"params": {
"username": "admin",
"password": "123456"
},
"assert": {
"code": 1,
"message": "成功"
}
}
}
]
}
2.python中的yaml包
2.1 pyyaml包说明
在python中想要读取yaml格式的文件 ,需要下载一个第三方包: pyyaml。
pyyaml是一个用于在Python程序中解析和生成YAML格式数据的模块。使用pyyaml,可以将yaml格式的文件读入到Python对象中,或将Python对象转换为yaml格式的数据并输出到文件中。
2.2 安装及导入
# 安装命令:
pip install pyyaml
# 导入 :
import yaml2.3 主要方法
在pyyaml包中 ,常用的方法有如下四个,分别是:


可以看出,以上的6个方法中,常用到的就是4个方法 ,下面我们分别通过4个实例来说明 。
safe_load(f,Loader=yaml.SafeLoader)方法
作用 :将yaml格式的数据转化为python对象 。

可以看到 :
-
yaml文件若是字典格式的数据 ,转化为python对象后就是字典类型的数据 ;
-
yaml 文件若是列表格式的字典 ,转化为python对象后就是列表类型的数据 ;
load_all(f,Loader=yaml.SafeLoader)方法
作用 :将多个yaml的文档数据转化为python生成器对象 ,每个yaml文件在同一文件是用---分割 。

safe_dump(data,stream,allow_unicode,sort_keys)方法
作用 :将Python对象序列化为YAML格式的数据并输出到指定的输出流。
参数说明 :
-
data :要读取的python数据源
-
stream :要指定yaml文件的文件对象 。
-
allow_unicode :若数据中包含中文,此参数必须设置为true,否则写入yaml文件的是unicode编码。
-
sort_keys :此值默认是True , 即按键进行排序 ,排序后的显示是不对的 ,所以,最好将其设置为False .

dump_all(data,stream)方法
作用 :将Python对象序列化为YAML格式的数据并输出到指定的输出流。
参数说明 :
-
data :要读取的python数据源
-
stream :要指定yaml文件的文件对象 。
-
allow_unicode :若数据中包含中文,此参数必须设置为true,否则写入yaml文件的是unicode编码。
-
sort_keys :此值默认是True , 即按键进行排序 ,排序后的显示是不对的 ,所以,最好将其设置为False .

3.项目中使用yaml包
还是以前面介绍的接口自动化测试框架为例 ,之前框架的测试用例数据直接写在了测试用例中 ,改数据意味着就的改测试用例 ,当测试用例多了以后,后续的维护和扩展不太方便 。具体如下图

所以 ,一个可行的办法就是将测试用例和测试数据分离 ,将测试数据单独放在一个文件中 ,放在什么文件比较好呢 ? 当然是yaml文件 。
3.1 场景1-测试数据和测试用例分离
测试数据和测试用例的分离步骤主要有以下三步 :
-
在公共类库中编写一个函数 ,用于读取yaml文件 。
-
使用yaml文件编写测试用例数据
-
在测试用例中替换成从yaml中读取测试数据 。
(1)公共函数文件名 :basic_utils.py
# 读取yaml文件
def read_yaml(filename):
with open(filename,encoding='utf-8') as f:
python_obj = yaml.safe_load(f)
return python_obj 2)登录测试用例数据 :login.yaml 
(3).更改测试用例文件 :test_login.py
import unittest
from api.login_demo_api import login
from utils.basic_utils import read_yaml, get_file_path
class TestLogin(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
yaml_path = get_file_path('login.yaml') # 获取login.yaml的全路径
result = read_yaml(yaml_path) # 转化为python对象
cls.login_data = result.get('login') # 获取字典中login的值
# case1 : 测试登录成功
def test_login_success(self):
res = self.login_data[0] # 获取列表中第一个值
login_result = login(res.get('username'),res.get("password"))
self.assertEqual(res.get("code"), login_result.get('errno'))
self.assertEqual(res.get("message"), login_result.get('errmsg'))
# case2 : 测试密码错误
def test_password_is_wrong(self):
res = self.login_data[1] # 获取列表中第二个值
login_result = login(res.get('username'),res.get("password"))
self.assertEqual(res.get("code"), login_result.get('errno'))
self.assertEqual(res.get("message"), login_result.get('errmsg',login_result))
# case3 : 测试密码为空
def test_password_is_null(self):
res = self.login_data[2] # 获取列表中第三个值
login_result = login(res.get('username'),res.get("password"))
self.assertEqual(res.get("code"), login_result.get('errno'))
self.assertEqual(res.get("message"), login_result.get('errmsg',login_result))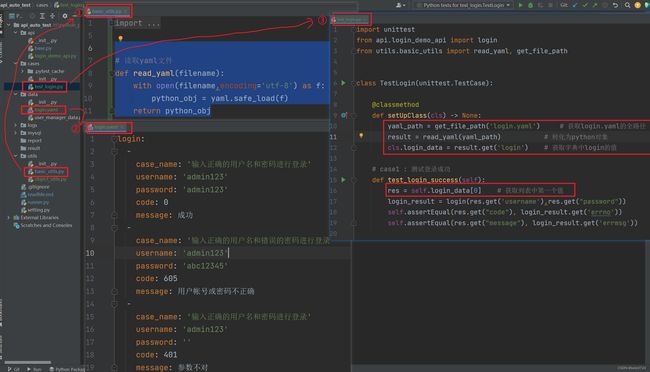
上面的这种写法就是典型的封层思想 ,其优点就是简单易懂 、容易上手 。但是它的缺点也就是维护量比较大。
比如我想现实一个登录的测试 。那么你的实现一个登录接口(在接口层) 、实现一个登录测试用例(在用例层) 、在添加一个登录测试数据(在数据层) 。也就是每个接口的测试至少要实现三个文件 。即:
-
接口请求文件 :比如登录接口
-
接口测试用例 :比如登录测试用例
-
接口测试数据 :比如登录测试数据
如果一家公司的(自动化)测试用例完全是由自动化测试工程师来写 ,无疑工作量很大 ,更主要的是它对业务相对不熟 ,因为这个测试最合适的人选还是功能测试 。但是功能测试人员要写的话 ,就必须懂这个框架 ,学习成本高 。他们的懂如何写接口 、如何写用例 以及如何写数据才能完成一个接口的测试。
以上问题该如何解决呢 ? 可以采取下面的方式去来解决 。
3.2 场景2-整体将测试用例存放在数据中
基于以上维护量大且功能测试人员学习成本高的问题 ,可以采取如下方式解决 :
(1)一个调用接口方法,所有的接口请求使用一个方法搞定,这个在介绍requests包时有介绍过 。
(2)一个测试用例方法,所有的测试用例和测试数据的参数都提取为数据 ,使用一个测试方法运行即可 ,具体那些参数可提取呢?
第四、如何使用yaml编写测试数据 ,也就是本篇的内容 。
需要说明的是,以上的这两点介绍已经超出了我们这套自动化框架的能力了 。这些内容都在我的自动化课程中有详细介绍 ,故在这里不做详细阐述 。
4 项目总结
至此,我们已经实现了四步了 ,分别是 :
第一 、如何编写一个接口自动化框架 ,在第一篇博文中介绍了 。测试新手如何去学习接口自动化测试 ?从这一套测试框架开始 。_kele0724的博客-CSDN博客
第二、如何编写测试用例 ,已经在第二篇博文中介绍了 。如何编写接口自动化框架系列之unittest测试框架的详解(二)_kele0724的博客-CSDN博客
第三、如何实现接口请求 ,并和测试用例如何对接 ,已经在第三篇博文中介绍了。如何编写接口自动化框架系列之requests详解(三)_kele0724的博客-CSDN博客
-
测试用例标题 :描述测试用例的标题
-
测试接口数据 :包括接口地址 ,请求方法 ,请求参数(其中包括了测试用例的输入数据)
-
断言数据 :主要包括所有断言的数据 。
-
初始化和清除数据 :甚至要做的初始化和清除数据都能放在这里 。
-
其它 : 一些你认为可以加的自定义数据 。

当然 ,要想实现这样的功能一般都是需要以下的两个条件 :
-
重写框架 ,目前现有的这套框架已经无法满足此要求 ,你只能重新写一个框架 ,重写设计框架 ,来满足新的需求 。
-
抽象能力 ,即找共性 ,从不同中事物中找相同属性 ,很多人把它叫底层逻辑 ,所谓的底层逻辑 = 不同中的相同 + 变化中的不变。我们设计这个新框架也是会用到这个思维 ,比如这个接口框架的每个测试接口 、测试方法、测试数据、断言结果都不一样 ,但是所不变的是它的这些公共字段 。只要把这些公共字段抽取出来 ,形成一个模板 ,接下来就是如何通过一个方法来适配这里面的所有数据就可以了 ,而我们上面的那个测试用例方法就是这样被抽取出来的 。