深度学习自建模型常见bug (KEModel)
在构建一个新模型时的踩坑经历,模型描述
1.(已解决) 第一轮训练loss就是nan
中间有一层特征图是拼接而成,缺少各部分分别归一化,并且有一个值一直是inf,查看特征如下:
- (tensor([[[3.8176e+01, 1.6472e+04, 2.9112e-01, 2.1578e-01, inf,
2.4098e-02, 2.4098e-02, 2.9844e-03, 3.0047e-03, 6.4136e-04]]],
dtype=torch.float64, grad_fn=<CatBackward0>),)
特征归一化
def data_normal(org_data):
d_min = org_data.min()
if d_min < 0:
org_data += torch.abs(d_min)
d_min = org_data.min()
d_max = org_data.max()
dst = d_max - d_min
norm_data = (org_data - d_min).true_divide(dst)
return norm_data
偶尔出现nan的输出可能是输入数据就含有nan值,需检查
after_total_nan_values = data.isnull().sum().sum()
print('after fillna, total_nan_values is: ', after_total_nan_values)
2.(已解决)报错RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [1, 1, 5]], which is output 0 of AddBackward0, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
参考:https://blog.csdn.net/qq_35056292/article/details/116695219
将问题1中的org_data += torch.abs(d_min)改为org_data = org_data + torch.abs(d_min)
3. (已解决)loss在训练几轮后变为nan
常见原因:如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来说低于现有学习率1-10倍即可。(未解决)
自查,发现突然出现NAN的时候都会报错这样
[ -3000 -12100 64000 -46900 -1800 -12100 15600 -11300 -4300 18600
-9800]
D:\PythonProject\ECG-Bianrized-main\ECG-Bianrized-main\src\models\KEModel1022.py:36: RuntimeWarning: invalid value encountered in sqrt
rmssd = np.sqrt(np.mean(diff_nni ** 2))
可能是数据以毫秒为单位再经过各种平方计算数据太大超出了范围导致开平方之前出现了负数,改秒为单位试一下(已解决)
4. (解决的不好)有一组数据切片后的shape是torch.Size([1, 3, 216, 1])无法计算样本熵特征
ValueError: cannot embed data of length 2 with embedding dimension 3 and lag 1, minimum required length is 3
在计算时间序列样本熵时调用了nold.sampen,sampen = nolds.sampen(nn_intervals, emb_dim=2),语法为
nolds.sampen(data, emb_dim=2, tolerance=None, dist=<function rowwise_chebyshev>, closed=False, debug_plot=False, debug_data=False, plot_file=None)[source]
看了下样本熵的介绍,dim改为1,dim改为1没有解决,暂时删掉样本熵这个特征
5. (已解决)原始数据中有一个坏数据需要删除(维度为0)
IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
原因:在原始数据切片后有个别几个tensor数据维度为([]),因此要在加载数据的初始化时删掉
解决:先用一个程序把错误数据的序号列出来,由于tensor不能删除行,转化成numpy删除,再转化回来。在得出要删除的数据的列表时经常出现差一两位的情况,数据不多的情况下多试几次就出来了。
self.x_train_temp = x_train.numpy()
self.y_train_temp = y_train.numpy()
del_list = [312, 1770, 2766]
self.x_train_temp = np.delete(self.x_train_temp, del_list, axis=0)
self.y_train_temp = np.delete(self.y_train_temp, del_list, axis=0)
self.x_train = torch.Tensor(self.x_train_temp)
self.y_train = torch.Tensor(self.y_train_temp)
6. (已解决)RuntimeError: expected scalar type Long but found Float
在问题五里dataloader转化为numpy格式又转化回tensor会出现数据类型不对的情况,添加.type(torch.long)注意不能使用类似于v = torch.tensor([0], dtype=torch.float)会报错
self.x_train = torch.Tensor(self.x_train_temp).type(torch.long)
self.y_train = torch.Tensor(self.y_train_temp).type(torch.long)
7. (已解决)五分类任务交叉熵损失函数,训练大半个epoch(小几千条数据)loss从1.5降到0.8左右突然变成nan
tensor(1.6826, grad_fn=<NllLossBackward0>)
tensor(1.3434, grad_fn=<NllLossBackward0>)
D:\anaconda\envs\py_cpu\lib\site-packages\numpy\core\_methods.py:265: RuntimeWarning: Degrees of freedom <= 0 for slice
ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
D:\anaconda\envs\py_cpu\lib\site-packages\numpy\core\_methods.py:223: RuntimeWarning: invalid value encountered in divide
arrmean = um.true_divide(arrmean, div, out=arrmean, casting='unsafe',
D:\anaconda\envs\py_cpu\lib\site-packages\numpy\core\_methods.py:257: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
D:\anaconda\envs\py_cpu\lib\site-packages\numpy\core\fromnumeric.py:3432: RuntimeWarning: Mean of empty slice.
return _methods._mean(a, axis=axis, dtype=dtype,
D:\anaconda\envs\py_cpu\lib\site-packages\numpy\core\_methods.py:190: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
tensor(nan, grad_fn=<NllLossBackward0>)
loss在这个警告后都变成nan怀疑遇到了值为nan的数据,尝试删除该条数据,成功,方法同问题六
8. 分类任务样本不均衡导致的少数类准确率低
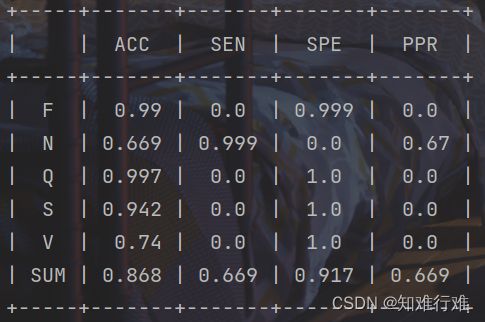
问题:为了降低损失,模型把全部数据都分类成数量较多的N样本
解决方法:
- 尝试改为Focal Loss,即使调大参数问题未解决
- 尝试重新采样,采用PyTorch采样器ImbalancedDatasetSampler
这篇博客没有详细说明,但如果报错Train_DataSet‘ object has no attribute ‘get_label‘,则说明如果用自建数据集此处应该对imbalanced.py文件进行修改,在报错出根据自定义类看着修改一下,比如我的修改为
elif isinstance(dataset, torch.utils.data.Dataset):
# return dataset.get_labels()
return dataset.y_train[:]