【 Python 全栈开发 - 语法基础篇 - 20 】数据可视化
文章目录
- 一、数据可视化
- 二、pandas
-
- 1. 折线图
- 2. 散点图
- 3. 柱状图
- 4. 饼图
- 三、matplotlib
-
- 1. 折线图
- 2. 散点图
- 3. 柱状图
- 4. 饼图
- 四、seaborn
-
- 1. 安装和导入Seaborn
- 2. 加载数据集
- 3. 绘制散点图
- 4. 绘制直方图
- 5. 绘制核密度图
- 6. 绘制条形图
- 7. 绘制热力图
- 五、plotly
-
-
- 安装plotly
- 创建图表
- 创建交互式图表
-
一、数据可视化
数据可视化是一种将数据转化成可视化图形的表现形式,目的是更好地展示和交流数据,从而更深层次地理解数据。
这种表现形式通常是基于图表、图形、地图和其他视觉元素,帮助人们识别和理解数据的趋势、模式和异常,以及进行更有效的决策。
数据可视化也是数据科学和数据分析中重要的一环,可以帮助人们发现数据中隐藏的信息,支持数据驱动的决策制定过程。
学习数据可视化需要:
-
学习基本概念和技能:学习数据可视化的基本概念、原则和技能,例如如何选择合适的图表类型、颜色和字体等。推荐学习相关的课程和书籍,例如《数据可视化之美》、《The Visual Display of Quantitative Information》等。
-
实践:通过实践来巩固理论知识和技能。可以用一些数据可视化工具,例如
Tableau、Power BI、Python 的matplotlib和Seaborn等工具,结合一些公开的数据集来做练习和项目,以便更深入地理解和掌握数据可视化。 -
学习优秀的案例:学习一些成功的数据可视化案例,了解其设计和实现过程,以及所应用的技术和原则。可以参考一些优秀的数据可视化网站,并结合课程和书籍来进行学习。
-
与其他人交流和分享:与其他数据可视化爱好者、专家和同行交流和分享经验和见解。可以参加一些线上或线下的数据可视化社群或活动,也可以在社交媒体上关注和参与相关的讨论和分享。
总体来说,学习数据可视化需要结合理论学习、实践和分享交流来进行,并需要不断地学习和拓展。
学习 Python 数据可视化需要包含以下内容:
-
Python 基础知识:包括 Python 语法、数据类型、函数、模块等基本知识,这是学习 Python 数据可视化的基础。
-
数据处理和分析:学习如何使用Python中流行的数据处理和分析库,例如
NumPy、Pandas等,以及掌握数据清洗、分组、聚合等技术。 -
数据可视化工具:了解 Python 中常用的数据可视化工具,例如
matplotlib、Seaborn、Plotly等,学习如何使用这些工具绘制各种图表。 -
数据可视化设计原则:学习数据可视化中的基本设计原则,例如如何选择合适的图表类型、颜色、标签等。
-
项目实践:通过做项目来巩固理论和技能,例如可视化一些公开的数据集或个人感兴趣的数据,如通过 Python 绘制销售数据、航班延误数据等。
-
社区交流:参加相关的 Python 数据可视化社区、论坛、博客等,与其他人交流并分享自己的经验和见解。
了解以上这些内容会对 Python 数据可视化的学习有很大的帮助。
我们主要学习四个库:
pandas可以用于创建简单的图表,例如线图,散点图和直方图等。它内置了一些绘图函数,如plot(),scatter()和hist()等。matplotlib是 Python 中最流行的可视化库,可用于创建各种类型的图表,例如线图、散点图、柱状图、饼图、热力图、轮廓图等等。可以使用其大量的函数和方法创建复杂的数据可视化。seaborn是基于matplotlib构建的高级可视化库。它提供了更高级的图表类型,如分布图、热力图、聚类图等等,并且包含了一些默认选项和美学风格。plotly是一种交互式数据可视化库,它可以创建各种类型的图表,包括散点图、折线图、柱状图、热力图、轮廓图等等。它可以生成交互式图表,其中用户可以通过鼠标悬停、缩放和平移等操作来探索数据。
这些库都有自己的优点和适用范围,可以根据具体的需求和场景来选择使用。
二、pandas
使用 pandas 进行数据可视化通常需要先将数据组织为dataframe格式,然后使用 pandas 内置的绘图函数来创建图表。
1. 折线图
折线图是一种常见的数据可视化类型,用于显示随时间或其他连续变量的关系。在 pandas 中,可以使用plot()函数绘制折线图。
import pandas as pd
import matplotlib.pyplot as plt
# 创建数据
data = pd.DataFrame({'year': [2017, 2018, 2019, 2020], 'sales': [100, 150, 200, 250]})
# 绘制折线图
data.plot(x='year', y='sales', marker='o')
plt.title('Sales by Year')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.show()
输出图表如下:

2. 散点图
散点图用于显示两个连续变量之间的关系。在 pandas 中,可以使用plot()函数并指定kind='scatter'来绘制散点图。
import pandas as pd
import matplotlib.pyplot as plt
# 创建数据
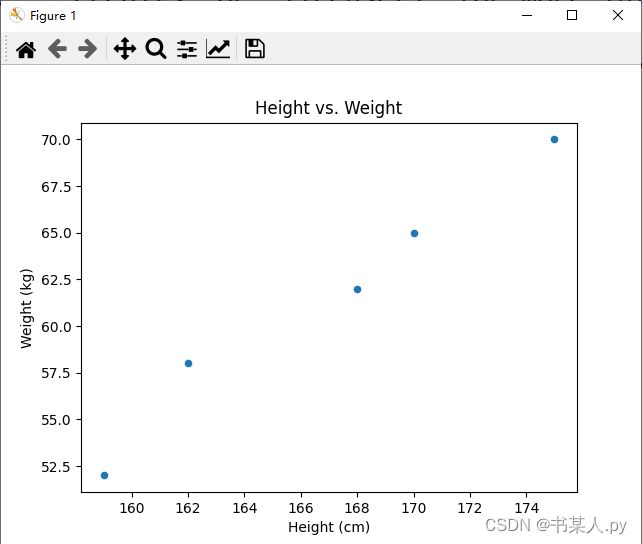
data = pd.DataFrame({'height': [162, 168, 175, 159, 170], 'weight': [58, 62, 70, 52, 65]})
# 绘制散点图
data.plot(x='height', y='weight', kind='scatter')
plt.title('Height vs. Weight')
plt.xlabel('Height (cm)')
plt.ylabel('Weight (kg)')
plt.show()
输出图表如下:
3. 柱状图
柱状图用于显示离散变量之间的比较。在 pandas 中,可以使用plot()函数并指定kind='bar'来绘制柱状图。
import pandas as pd
import matplotlib.pyplot as plt
# 创建数据
data = pd.DataFrame({'product': ['A', 'B', 'C', 'D'], 'sales': [100, 150, 200, 250]})
# 绘制柱状图
data.plot(x='product', y='sales', kind='bar')
plt.title('Sales by Product')
plt.xlabel('Product')
plt.ylabel('Sales')
plt.show()
输出图表如下:

4. 饼图
饼图用于显示不同类别之间的比例。在 pandas 中,可以使用plot()函数并指定kind='pie'来绘制饼图。
import pandas as pd
import matplotlib.pyplot as plt
# 创建数据
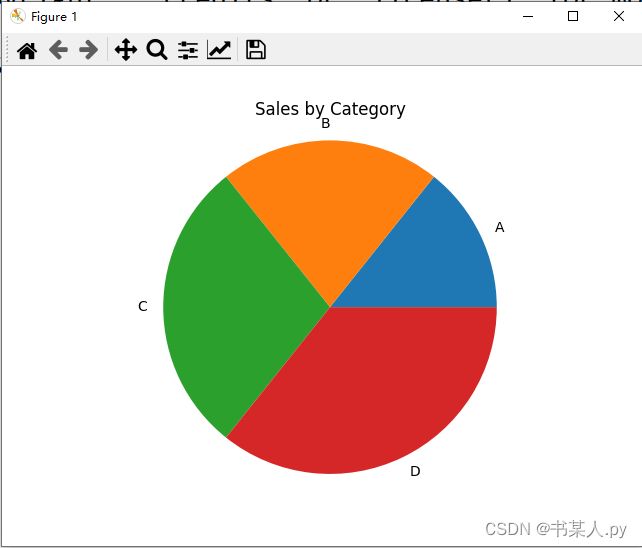
data = pd.DataFrame({'category': ['A', 'B', 'C', 'D'], 'sales': [100, 150, 200, 250]})
# 绘制饼图
data.set_index('category').plot(kind='pie', y='sales', legend=False)
plt.axis('equal')
plt.title('Sales by Category')
plt.ylabel('')
plt.show()
输出图表如下:
这些示例演示了如何使用 pandas 创建基本的数据可视化图表。根据需要,可以进一步自定义图表样式和属性以满足特定需求。
三、matplotlib
使用 Matplotlib 进行数据可视化需要首先导入 Matplotlib 库。然后,数据需要被组织成可迭代的数据结构,如列表或数组。接下来,可以使用 Matplotlib 函数创建各种类型的图表。
以下是使用 Matplotlib 绘制常见图表的示例:
1. 折线图
折线图是一种常见的数据可视化类型,用于显示随时间或其他连续变量的关系。在 Matplotlib 中,可以使用plot()函数绘制折线图。
import matplotlib.pyplot as plt
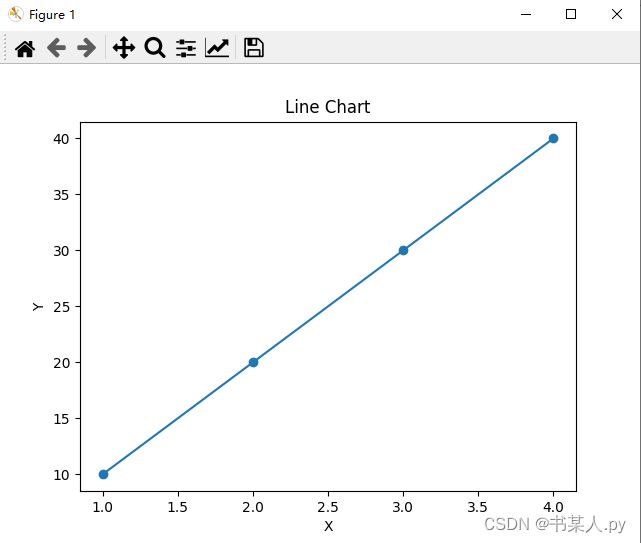
# 创建数据
x = [1, 2, 3, 4]
y = [10, 20, 30, 40]
# 绘制折线图
plt.plot(x, y, 'o-')
plt.title('Line Chart')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
输出图表如下:
2. 散点图
散点图用于显示两个连续变量之间的关系。在 Matplotlib 中,可以使用scatter()函数绘制散点图。
import matplotlib.pyplot as plt
# 创建数据
x = [162, 168, 175, 159, 170]
y = [58, 62, 70, 52, 65]
# 绘制散点图
plt.scatter(x, y)
plt.title('Scatter Plot')
plt.xlabel('Height (cm)')
plt.ylabel('Weight (kg)')
plt.show()
输出图表如下:

3. 柱状图
柱状图用于显示离散变量之间的比较。在 Matplotlib 中,可以使用bar()函数绘制柱状图。
import matplotlib.pyplot as plt
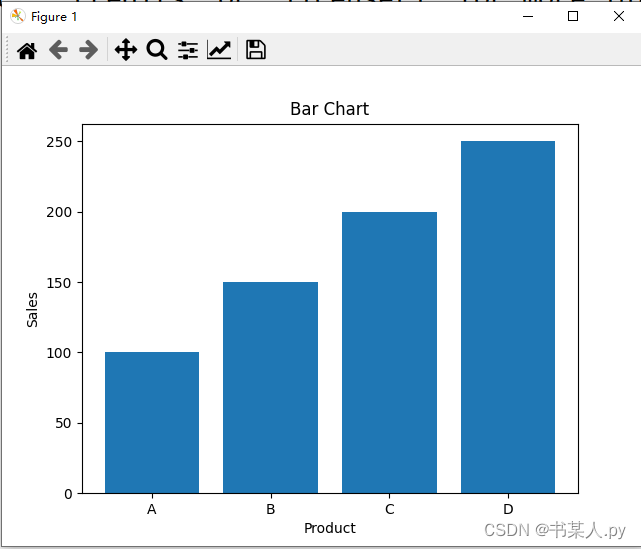
# 创建数据
x = ['A', 'B', 'C', 'D']
y = [100, 150, 200, 250]
# 绘制柱状图
plt.bar(x, y)
plt.title('Bar Chart')
plt.xlabel('Product')
plt.ylabel('Sales')
plt.show()
输出图表如下:
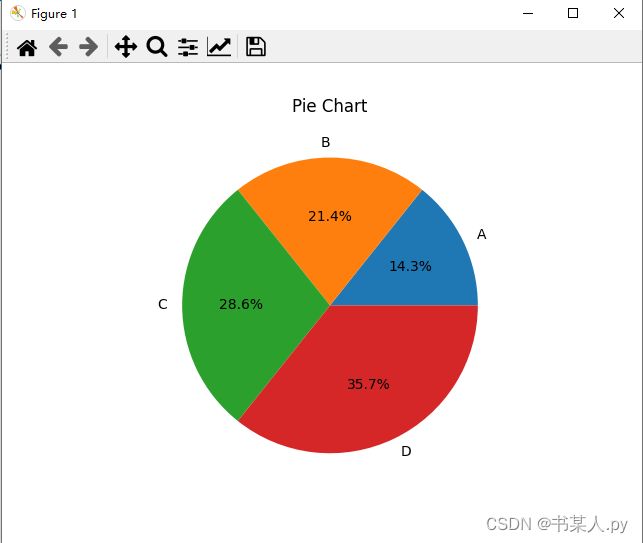
4. 饼图
饼图用于显示不同类别之间的比例。在 Matplotlib 中,可以使用pie()函数绘制饼图。
import matplotlib.pyplot as plt
# 创建数据
x = ['A', 'B', 'C', 'D']
y = [100, 150, 200, 250]
# 绘制饼图
plt.pie(y, labels=x, autopct='%1.1f%%')
plt.title('Pie Chart')
plt.show()
输出图表如下:
这些示例演示了如何使用 Matplotlib 创建基本的数据可视化图表。根据需要,可以进一步自定义图表样式和属性以满足特定需求。
四、seaborn
Seaborn 是 Python 中一个流行的数据可视化库,它基于 matplotlib,提供了更加美观的绘图风格和更高级的可视化功能。下面是使用 Seaborn 进行数据可视化的详细介绍和示例:
1. 安装和导入Seaborn
可以使用pip.install安装 Seaborn 库,命令如下:
!pip install seaborn
安装完成之后,需要导入Seaborn库,命令如下:
import seaborn as sns
import matplotlib.pyplot as plt
2. 加载数据集
Seaborn 库中内置了一些数据集,方便我们进行数据可视化实验。首先,我们需要加载数据集,以Iris数据集为例,命令如下:
iris = sns.load_dataset("iris")
3. 绘制散点图
散点图是一种常用的数据可视化方式。Seaborn 提供了sns.scatterplot()函数来生成散点图。下面是绘制Iris数据集的散点图的示例:
sns.scatterplot(x="sepal_length", y="sepal_width", hue="species", data=iris)
plt.show()
这里,我们用sepal_length和sepal_width作为 x 轴和 y 轴,用种类species来区分不同类型的鸢尾花。
4. 绘制直方图
直方图可以用来展示数据的分布情况。Seaborn 提供了sns.histplot()函数来生成直方图。下面是绘制Iris数据集sepal_length的直方图的示例:
sns.histplot(data=iris, x="sepal_length")
plt.show()
5. 绘制核密度图
核密度图是展示数据密度分布情况的一种方法。Seaborn 提供了sns.kdeplot()函数来生成核密度图。下面是绘制Iris数据集sepal_length的核密度图的示例:
sns.kdeplot(data=iris, x="sepal_length")
plt.show()
6. 绘制条形图
条形图可以用来展示类别型数据的大小比较。Seaborn 提供了sns.barplot()函数来生成条形图。下面是绘制Titanic数据集中不同性别的存活率条形图的示例:
titanic = sns.load_dataset("titanic")
sns.barplot(x="sex", y="survived", data=titanic)
plt.show()
7. 绘制热力图
热力图是一种展示矩阵数据的颜色编码图。Seaborn 提供了sns.heatmap()函数来生成热力图。下面是绘制flights数据集中航班乘客人数的热力图的示例:
flights = sns.load_dataset("flights")
flights = flights.pivot("month", "year", "passengers")
sns.heatmap(flights, annot=True, fmt="d")
plt.show()
这里,利用pivot()函数将flights数据集重新排列为一个矩阵形式,其中行为月份,列为年份,值为乘客数量。利用heatmap()函数,我们可以将矩阵数据进行颜色编码,以展示各个年份和月份的航班乘客人数。
五、plotly
Plotly 是一种用于创建交互式数据可视化的工具。它支持多种编程语言,包括 Python、R、JavaScript 等,但本文主要介绍使用 Python 的方法。以下是使用 plotly 进行数据可视化的步骤。
安装plotly
首先,需要安装 plotly 的 Python 版本。可以使用 pip 命令进行安装:
pip install plotly
创建图表
下面是一个简单的示例,展示如何使用 plotly 创建散点图:
import plotly.graph_objs as go
import plotly.offline as pyo
# 创建散点图的数据
x = [1, 2, 3, 4, 5]
y = [1, 4, 2, 3, 7]
# 创建散点图的布局
layout = go.Layout(title='Scatter Plot')
# 创建散点图的图形对象
data = [go.Scatter(x=x, y=y, mode='markers')]
# 使用plotly将图表渲染为HTML文件
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig, filename='scatter.html')
在这个例子中,我们首先创建了数据 x 和 y,然后使用go.Scatter创建了散点图的图形对象。同时还指定了散点图的布局,在这里我们只设置了一个标题。最后,使用pyo.plot方法将图表渲染为 HTML 文件。
创建交互式图表
使用 plotly 还可以创建更高级的交互式图表,例如饼图、条形图、热力图等。下面是一个例子,展示如何使用 plotly 创建带有下拉菜单的折线图:
import plotly.graph_objs as go
import plotly.offline as pyo
import pandas as pd
# 读取数据
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
# 创建折线图数据
data = []
for column in df.columns[1:]:
trace = go.Scatter(x=df['Date'], y=df[column], mode='lines', name=column)
data.append(trace)
# 创建折线图布局
layout = go.Layout(title='Apple Stock Prices')
# 将下拉菜单绑定到折线图
updatemenus = [
dict(
buttons=[{
'args': [{'visible': [True, False, False, False, False, False]},
{'title': 'Open'}],
'label': 'Open',
'method': 'update'
}, {
'args': [{'visible': [False, True, False, False, False, False]},
{'title': 'High'}],
'label': 'High',
'method': 'update'
}, {
'args': [{'visible': [False, False, True, False, False, False]},
{'title': 'Low'}],
'label': 'Low',
'method': 'update'
}, {
'args': [{'visible': [False, False, False, True, False, False]},
{'title': 'Close'}],
'label': 'Close',
'method': 'update'
}, {
'args': [{'visible': [False, False, False, False, True, False]},
{'title': 'Volume'}],
'label': 'Volume',
'method': 'update'
}, {
'args': [{'visible': [False, False, False, False, False, True]},
{'title': 'Adj Close'}],
'label': 'Adj Close',
'method': 'update'
}],
direction='down',
pad={'r': 10, 't': 10},
showactive=True,
x=0.1,
xanchor='left',
y=1.1,
yanchor='top'
),
]
layout.updatemenus = updatemenus
# 创建折线图图形对象
fig = go.Figure(data=data, layout=layout)
# 使用plotly将图表渲染为HTML文件
pyo.plot(fig, filename='linechart.html')
在这个例子中,我们首先使用pd.read_csv方法读取了股票历史数据,然后根据数据创建了多个折线图。与之前的例子不同的是,我们使用了updatemenus属性创建了一个下拉菜单,用于切换折线图的不同数据。最后,使用pyo.plot方法将图表渲染为 HTML 文件。
以上是使用 plotly 进行数据可视化的基本步骤和示例。plotly 具有丰富的功能和可定制性,可以用于创建各种类型的图表。