微服架构基础设施环境平台搭建 -(三)Docker+Kubernetes集群搭建
微服架构基础设施环境平台搭建 -(三)Docker+Kubernetes集群搭建
通过采用微服相关架构构建一套以Kubernetes+Docker为自动化运维基础平台,以微服务为服务中心,在此基础之上构建业务中台,并通过Jekins自动构建、编译、测试、发布的自动部署,形成一套完整的自动化运维、发布的快速DevOps平台。
本文是展示了从手动方式在Linux上搭建Docker+Kubernets集群,其Master节点是ks-m1、ks-m2、ks-m3,Worker节点是ks-n1、ksn2
文章的操作过程大部分参照【基于青云LB搭建高可用的k8s集群】
微服架构基础设施环境平台搭建 系列文章
微服架构基础设施环境平台搭建 -(一)基础环境准备
微服架构基础设施环境平台搭建 -(二)Docker私有仓库Harbor服务搭建
微服架构基础设施环境平台搭建 -(三)Docker+Kubernetes集群搭建
微服架构基础设施环境平台搭建 -(四)在Kubernetes集群基础上搭建Kubesphere平台
微服架构基础设施环境平台搭建 -(五)Docker常用命令
目录
- 微服架构基础设施环境平台搭建 -(三)Docker+Kubernetes集群搭建
- 一、采用的技术架构
- 二、微服架构基础设施平台网络规划
- 三、部署架构
- 四、安装Docker并配置Docker
-
- 1、安装Docker
- 2、配置Docker
- 五、安装Kubesphere
-
- 1、下载并安装kubeadm、kubectl、kubelet
- 2、设置Table键补全
- 六、初始化master节点
-
- 1、检测安装环境
- 2、镜像下载/导入
- 3、创建配置文件
- 4、初始化
- 5、环境配置
- 6、集群重置(可选)
- 七、扩展master节点
-
- 1、拷贝配置文件
- 2、扩展master节点
- 八、扩展node节点
-
- 1、扩展Node
- 2、把ks-n1的ROLES变成work
- 3、把ks-n2的ROLES变成work
- 九、安装插件
-
- 1、安装Calico网络插件
-
- 1)、下载Calico网络插件文件
- 2)、修改calico.yaml配置文件
- 3)、下载Calico镜像
- 4)、安装Calico网络插件
- 5)、查看node节点和pod状态
- 2、安装CoreDNS域名解析插件
- 3、安装Metrics数据采集插件
-
- 1)、下载Metrics-server插件文件
- 2)、修改配置文件
- 3)、下载镜像
- 4)、调整apiserver的配置
- 5)、更新apiserver的配置
- 6)、安装metrics-server
- 7)、查看节点资源
- 8)、更新metrics-server配置操作(metrics-server.yaml配置文件发生变更时再执行)
一、采用的技术架构
| 序号 | 技术框架 | 说明 |
|---|---|---|
| 1 | Kubernetes | |
| 2 | Kubesphere | Kubernetes编排器,管理平台 |
| 3 | Docker | |
| 4 | Harbor | Docker私有仓库 |
| 5 | GitLab | 源码库 |
| 6 | Jekins | 自动编译、测试、发布平台 |
| 7 | Spring Cloud Alibaba | Spring Cloud Alibaba微服体系架构 |
| 8 | Nacos | Api网关、服务注册发现配置管理中心 |
| 9 | Sentinel | 限流溶断安全中心 |
| 10 | Seata | 分布式事务管理框架 |
| 11 | Redis | 分布式缓存服务 |
| 12 | ElasticSearch/Solr | 数据检索服务 |
| 13 | Mysql | 结构化数据存储 |
| 14 | Grafana | 监控平台 |
| 15 | Nginx | 服务代理、Web服务 |
二、微服架构基础设施平台网络规划
| 序号 | IP | HostName | 操作系统 | K8s角色 | 说明 |
|---|---|---|---|---|---|
| 1 | 192.168.1.141 | ks-m1 | CentOS7_x64 | 控制节点 | Kubernetes Master |
| 2 | 192.168.1.142 | ks-m2 | CentOS7_x64 | 控制节点 | Kubernetes Master高可用节点,如果不需要高可用,可不部署此服务器 |
| 3 | 192.168.1.143 | ks-m3 | CentOS7_x64 | 控制节点 | Kubernetes Master高可用节点,如果不需要高可用,可不部署此服务器 |
| 4 | 192.168.1.144 | ks-n1 | CentOS7_x64 | 工作节点 | Kubernetes Worker |
| 5 | 192.168.1.145 | ks-n2 | CentOS7_x64 | 工作节点 | Kubernetes Worker |
| 6 | 192.168.2.146 | ks-harbor | CentOS7_x64 | 工作节点 | Harbor服务+NFS文件服务 |
三、部署架构

四、安装Docker并配置Docker
1、安装Docker
#安装docker
$ yum install docker-ce docker-ce-cli containerd.io -y 或指定版本 yum install docker-ce-20.10.8 docker-ce-cli-20.10.8 containerd.io -y
#启动docker并设置开机自启
$ systemctl start docker && systemctl enable docker.service && systemctl status docker
2、配置Docker
新增Dokcer配置文件
$ cat > /etc/sysconfig/modules/ipvs.modules <<EOF
{
"data-root":"/data/docker/lib",
"log-driver": "json-file",
"registry-mirrors": ["https://***.mirror.aliyuncs.com"],
"bip": "10.128.10.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"insecure-registries":["192.168.2.146"]
}
EOF
参数说明:
修改docker文件驱动为systemd,默认为cgroupfs,kubelet默认使用systemd,两者必须一致才可以。
data-root是修改默认存储路径,注意调整harbor的地址。
“insecure-registries”:[“harbor的ip+port”]
五、安装Kubesphere
1、下载并安装kubeadm、kubectl、kubelet
yum install -y kubelet-1.22.12 kubeadm-1.22.12 kubectl-1.22.12
systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet
说明:
上面可以看到kubelet状态不是running状态,这个是正常的,不用管,等k8s组件起来这个kubelet就正常了。
注:每个软件包的作用
Kubeadm: kubeadm是一个工具,用来初始化k8s集群的
kubelet: 安装在集群所有节点上,用于启动Pod的
kubectl: 通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2、设置Table键补全
让命令可用自动table键进行补全,对新手无法记住命令提供很好的支持,所在主机进行该操作方可使用table补全。
1)、Kubectl命令补全
kubectl completion bash > /etc/bash_completion.d/kubelet
2)、Kubeadm命令补全
kubeadm completion bash > /etc/bash_completion.d/kubeadm
六、初始化master节点
1、检测安装环境
检测主机环境是否达到集群的要求,可根据结果提示进行逐一排除故障
kubeadm init --dry-run
2、镜像下载/导入
1)列出需要使用的镜像列表
kubeadm config images list
2)拉取镜像
kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.12
参数说明:
–image-repository: 从哪个地方下载镜像(默认"k8s.gcr.io",但k8s.gcr.io国内无法访问);
–kubernetes-version: 指定kubernetes集群的镜像版本;
3、创建配置文件
1)、创建默认的配置文件
kubeadm config print init-defaults > kubeadm-init.yaml
2)、修改配置文件
vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.1.141
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: ks-m1
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
extraArgs:
runtime-config: "api/all=true"
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager:
extraArgs:
node-monitor-grace-period: "10s"
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
kind: ClusterConfiguration
imageRepository: "registry.aliyuncs.com/google_containers"
controlPlaneEndpoint: 192.168.1.141:6443
kubernetesVersion: 1.22.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
4、初始化
kubeadm init --config kubeadm-init.yaml --upload-certs
##upload-certs 标志用来将在所有控制平面实例之间的共享证书上传到集群,若是不加会报错.
说明:
1、问题一:
问题现象:kubeadm init过程中pull镜像超时
解决方案:配置中添加
imageRepository: "registry.aliyuncs.com/google_containers"
2、问题二:
问题现象:kubeadm init 之后,一直卡在了健康检查上
1)、日志如下
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
2)、根据提示依次执行命令
- ‘systemctl status kubelet’
- ‘journalctl -xeu kubelet’
通过执行“journalctl -xeu kubelet”命令显示日志显示:
server.go:294] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""
解决方案:在docker配置文件中配置kubelet cgroup driver为systemd
vim /etc/docker/daemon.json
daemon.json
{
"registry-mirrors": ["https://xcg41ct3.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://3hjcmqfe.mirror.aliyuncs.com"],
"insecure-registries" : ["192.168.2.146"],
"log-driver": "json-file",
"log-opts": {
"max-size": "500m",
"max-file": "2"
}
}
3、问题三
问题描述:重新执行kubeadm init命令时提下端口占用、配置文件已存在…问题
[root@ks-m1 hxyl]# kubeadm init --config kubeadm-init.yaml --upload-certs
[init] Using Kubernetes version: v1.22.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
原因:之前执行kubeadm init命令时已经在环境中产生了缓存
解决方案:
kubeadm reset
# 在对话中选择 y
# 重新执行init
kubeadm init --config kubeadm-init.yaml --upload-certs
执行成功后如下图所示

5、环境配置
根据初始化成功后的提示对集群进行基础的配置。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
echo "KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bashrc && source ~/.bashrc
kubectl get nodes

6、集群重置(可选)
初始化master有问题,可将集群重置,再次初始化master
kubeadm reset
七、扩展master节点
1、拷贝配置文件
在ks-m2、ks-m3节点上创建证书存放目录:
$ cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/
##把ks-m1节点的证书拷贝到ks-m2上:
$ scp /etc/kubernetes/pki/ca.crt ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/ca.key ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/sa.key ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/sa.pub ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/front-proxy-ca.crt ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/front-proxy-ca.key ks-m2:/etc/kubernetes/pki/
$ scp /etc/kubernetes/pki/etcd/ca.crt ks-m2:/etc/kubernetes/pki/etcd/
$ scp /etc/kubernetes/pki/etcd/ca.key ks-m2:/etc/kubernetes/pki/etcd/
##ks-m3同上
2、扩展master节点
分别在ks-m2、ks-m3服务器上执行下面命令,将ks-m2、ks-m3扩展为master节点
kubeadm join 192.168.1.141:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5b8264337d30e1d0f395fef083923dd0a88a41917f5f85073d4f61027e7b8b98 \
--control-plane --certificate-key fdc99561c3c38ad9a724f69fa985bf0628dcc7a5aab46ebb3ff5119abf91551d
注意:
如果忘记了token,可以通过命令 kubeadm token create --print-join-command 可以生成新的token

根据如上图所示节点扩展成功后需要执行下面命令
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# 查看kubnates节点,会列出所有节点,如上图所示
kubectl get nodes
八、扩展node节点
1、扩展Node
kubeadm join 192.168.1.141:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5b8264337d30e1d0f395fef083923dd0a88a41917f5f85073d4f61027e7b8b98 \
--certificate-key fdc99561c3c38ad9a724f69fa985bf0628dcc7a5aab46ebb3ff5119abf91551d
1)、ks-n1服务器扩展Node节点执行结果图:

2)、ks-n2服务器扩展Node节点执行结果图:

3)、在Master节点(ks-m1)上查看集群节点状态
kubectl get nodes

注意
通过查看集群状态可以看到,状态为NotReady,是因为还未安装网络插件,安装网络插件后就正常了,且node的点的角色为空,就表示这个节点是工作节点
2、把ks-n1的ROLES变成work
kubectl label node ks-n1 node-role.kubernetes.io/worker=worker
3、把ks-n2的ROLES变成work
kubectl label node ks-n2 node-role.kubernetes.io/worker=worker

九、安装插件
1、安装Calico网络插件
1)、下载Calico网络插件文件
curl https://projectcalico.docs.tigera.io/archive/v3.22/manifests/calico.yaml -O
##或者
$ wget https://docs.projectcalico.org/v3.22/manifests/calico.yaml --no-check-certificat
2)、修改calico.yaml配置文件
# 新增配置
- name: IP_AUTODETECTION_METHOD
value: "interface=ens.*"

注意:在安装calico网络时,默认安装是IPIP网络。calico.yaml文件中,将CALICO_IPV4POOL_IPIP的值修改成 “off”,就能够替换成BGP网络。ens.*是根据自己机器的网络来调整的。这样可以避很多calico网络错误。
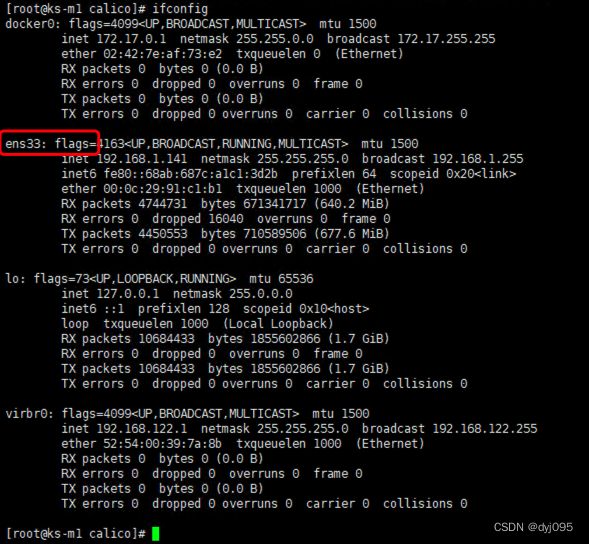
3)、下载Calico镜像
grep image calico.yaml
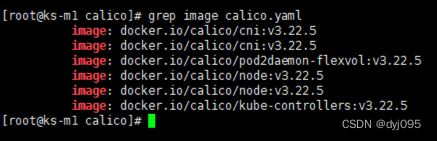
# 下载calico相关的镜像
docker pull calico/kube-controllers:v3.22.5
docker pull calico/cni:v3.22.5
docker pull calico/pod2daemon-flexvol:v3.22.5
docker pull calico/node:v3.22.5
4)、安装Calico网络插件
在其中一个Master节点上执行即可,本文中我们在ks-m1上执行安装
kubectl apply -f calico.yaml

5)、查看node节点和pod状态
kubectl get nodes
kubectl get pods -n kube-system

2、安装CoreDNS域名解析插件
在kubeadm安装的k8s集群中,安装Calico网络插件后会自动安装CoreDNS插件。
3、安装Metrics数据采集插件
metrics-server 是一个集群范围内的资源数据集和工具,同样的,metrics-server 也只是显示数据,并不提供数据存储服务,主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标,metric-server 收集数据给 k8s 集群内使用,如 kubectl,hpa,scheduler 等!
1)、下载Metrics-server插件文件
# 下载最新版本的yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 或者指定下载v0.4.1版本
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.4.1/components.yaml
2)、修改配置文件
mv components.yaml metrics-server.yaml
vim metrics-server.yaml
template:
metadata:
labels:
k8s-app: metrics-server
spec:
hostNetwork: true
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.3
说明:
1、将配置文件中的registry.k8s.io/metrics-server/metrics-server:v0.6.3修改为registry.aliyuncs.com/google_containers/metrics-server:v0.6.3
2、新增hostNetwork: true
3、新增- --kubelet-insecure-tls,跳过验证SSL证书
3)、下载镜像
#查看需要的镜像
grep image: metrics-server.yaml
# 下载镜像
docker pull registry.aliyuncs.com/google_containers/metrics-server:v0.6.3

4)、调整apiserver的配置
需要在kube-apiserver的配置文件中添加–enable-aggregator-routing=true参数来启用聚合认证
vim /etc/kubernetes/manifests/kube-apiserver.yaml
在kube-apiserver.yaml新增配置项
- --enable-aggregator-routing=true

5)、更新apiserver的配置
# 更新apiserver配置
kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml
# 查看pods状态
kubectl get pods -n kube-system
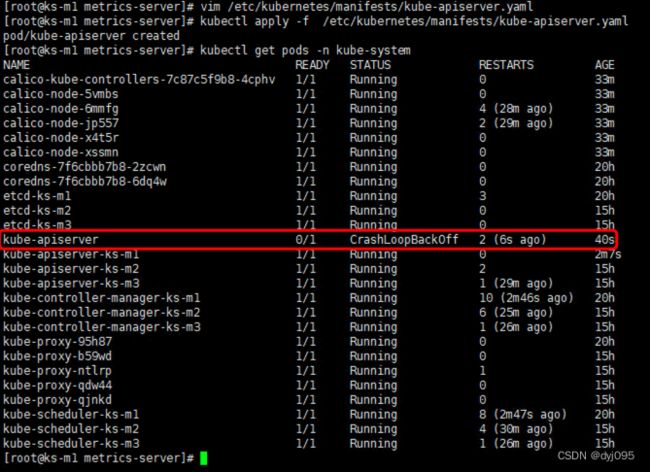
注:把CrashLoopBackOff状态的pod删除,删除后k8s会重新创建。
# 更新apiserver配置
kubectl delete pods kube-apiserver -n kube-system
6)、安装metrics-server
# 将metrics-server发布到kubernetes中的kube-system空间中
kubectl apply -f metrics-server.yaml
# 查看pods状态,确认metrics-server pod安装成功
kubectl get pods -n kube-system


7)、查看节点资源
kubectl top nodes

8)、更新metrics-server配置操作(metrics-server.yaml配置文件发生变更时再执行)
# 查看kube-system空间中的发布应用信息
kubectl get deployment -n kube-system
# 删除名称metrics-server的已发布的应用
kubectl delete deployment metrics-server -n kube-system
# 查看metrics-server的pod状态
kubectl get pods -n kube-system
# 重新发布metrics-server
kubectl apply -f metrics-server.yaml

至此Docker + Kubernetes集群搭建完成