Redis面试核心技术点和缓存相关问题
目录
Redis的数据结构和原理
Redis持久化:RDB和AOF
Redis的集群设计
缓存雪崩、击穿、穿透
高并发场景下缓存和数据库更新策略
Redis的大key和热key和大value
本地缓存
磁盘IO和网络开销 相比于 请求内存IO 要高上千倍,如果某个数据从数据库磁盘读出来需要 0.0045S,经过网络请求传输需要 0.0005S,那么每个请求完成最少需要 0.005S,该数据服务器每秒最多只能响应200 个请求。而如果该数据存于内存中,读出来只需要 100us,那么每秒能够响应 10000 个请求。这就是存储在硬盘的MySQL和存储在内存的Redis的差别。基于内存的缓存可以把系统响应能力提高 N 个数量级,远高于传统基于硬盘的关系型数据库。
Redis单线程有一个最大好处就是 节省线程切换的开销,更不用考虑并发读写带来的复杂操作场景,大大节省了线程间切换的时间。单线程模型避免了多线程的频繁上下文切换,这也避免了多线程可能产生的竞争问题。Reids 核心是基于非阻塞的 IO 多路复用机制。
Redis的数据结构和原理
Redis常用的5种数据结构如下,更多命令和使用场景请查看:Redis命令合集和设计场景_浮尘笔记的博客-CSDN博客
- 字符串 String: 基础的数据存储类型,可存储文本、Json、图片数据等任何二进制文件。主要命令:set/get。
- 列表 List: 按照插入顺序排序的字符串链表,在插入时如果key不存在会创建一个新的链表。主要命令:lpush/rpush/lpop/rpop。
- 哈希 Hash: 适合存储键值对信息,比如一个用户的昵称、性别、年龄等属性可以存储为一个key。主要命令:hset/hget/hgetall/hmset/hdel。
- 集合 Set: 无序集合,值不能重复。可以原来存储唯一IP、唯一用户ID 等信息。主要命令:sadd/smembers/srem。
- 有序集合 Sorted Set: 支持从小到大排序的集合,适用于排行榜结构的数据存储。主要命令:zadd/zscore/zrange[withscores]。
Redis底层原理:Redis 使用C语言编写,其中String类型使用简单动态字符串(simple dynamic string,简称 SDS)实现,有一个专门用于保存字符串长度的变量,可以通过len属性的值获取字符串长度,从一定程度上提高了读取效率。Redis中字符串的定义如下:
struct sdshdr {
int len; //记录 buf 中已经使用的空间长度
int free; //记录 buf 中还空余的空间
char buf[]; //记录字符串存储的内容
}有序集合 Sorted Set 的内部使用 哈希表(HashMap) 和跳跃表 (SkipList) 来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,跳表里存放的是所有的成员,排序依据是HashMap 里存的 score,使用跳表的结构可以获得比较高的查找效率,并且在实现上比较简单。
【问】为什么 Redis 的使用跳表结构而不用红黑树?
【答】红黑树的查找效率很高,但是在进行重新平衡时会涉及到大量节点的变化,因此实现和操作起来都比较复杂。而跳表通过简单的多层索引结构,实现简单,且能达到近似于红黑树的查找效率,插入多层节点不需要像红黑树那样有额外操作;而且跳表还能实现范围查找及输出,而红黑树只支持单个元素查找,对于范围查找效率低。
关于Redis底层的更多细节请查看:Redis底层数据结构和原理_浮尘笔记的博客-CSDN博客
缓存的淘汰策略:缓存相比于磁盘更加昂贵,因此不能把所有数据都放入缓存,只能把最重要的或者要求查询速度最快的数据缓存起来,因此需要有一定的策略来让过期的缓存失效。常见的缓存淘汰策略有下面几个:
- FIFO(First In First Out): 先进先出算法,先放入缓存的先被移除。
- LRU(Least Recently Used): 最近最少使用算法,使用时间距离现在最久的那个被移除。
- LFU(Least Frequently Used): 最不常用算法,一定时间段内使用次数(频率)最少的那个被移除。
Redis持久化:RDB和AOF
RDB 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中,会在指定目录下生成一个 dump.rdb 文件。Redis 如果重启了,会通过加载 dump.rdb 文件恢复数据。可以使用 SAVE 和 BGSAVE 两个命令来生成 RDB 文件,SAVE是阻塞的,BGSAVE 是后台 fork 子进程进行,不会阻塞主进程处理命令请求。载入 RDB 文件不需要手工运行,而是 server 端自动进行。只要启动时检测到 RDB 文件存在,server 端便会载入 RDB 文件重建数据集。如果同时存在 AOF 的话会优先使用 AOF 重建数据集,因为其保存的数据更完整。
如果业务对数据完整性和一致性要求不高,RDB 的启动速度更快; RDB 的性能很好,需要持久化时,主进程会 fork 一个子进程出来,然后把持久化的工作交给子进程,自己不会有相关的 I/O 操作。缺点就是可能丢失间隔时间内的数据,而且RDB备份时会创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍),最后再将临时文件替换之前的备份文件。
AOF 默认不开启,它采用日志的形式记录每个写操作,生成一个 appendonly.aof 文件,并将日志追加到文件末尾。Redis 重启的时候会根据日志文件的内容,将写指令从前到后执行一次以完成数据的恢复工作,有点类似 MySQL 的 binlog。优点就是能最大限度地保证数据不丢失,数据的完整性和一致性更高。缺点就是AOF备份产生的 appendonly.aof 文件较大,数据恢复的时候也会比较慢,Redis 针对 AOF 文件大的问题,提供了重写的瘦身机制:可以通过bgrewiteaof手动触发,或者配置相关选项自动触发重写。
关于Redis持久化的更多内容请查看:redis笔记06-持久化rdb和aof
Redis的集群设计
稍微优点规模的项目,不管是用 MySQL还是 Redis,单机基本上扛不住,差不多都得使用集群了。Reids 官方给出了 Redis-cluster 方案,无中心架构,可线性扩展到 1000 个节点。
Redis Cluster 是官方在 Redis 3.0 版本正式推出的高可用以及分布式的解决方案,内置数据自动分片机制,由多个 Redis 实例组成的整体,数据按照槽(slot) 存储分布在多个 Redis 实例上,集群内部将所有的 key 映射到 16384 个 Slot 中。
Redis Cluster 实现的功能:
- 将数据分片到多个实例 (按照 slot 存储);
- 集群节点宕掉会自动 failover;
- 提供相对平滑扩容 (缩容) 节点。
Redis Cluster 的优点:
- 无中心架构:三机房部署,其中一主一从构成一个分片,之间通过异步复制同步数据,异步复制存在数据不一致的时间窗口,保证高性能的同时牺牲了部分一致性(CAP定理)。一旦某个机房掉线,则分片上位于另一个机房的 slave 会被提升为 master 从而可以继续提供服务。
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除。
- 降低运维成本,提高系统的扩展性和可用性。
- Redis Cluste 可以线性扩展至 1000 个节点。Redis Cluster 本身就能自动进行 master 选举和故障转移。
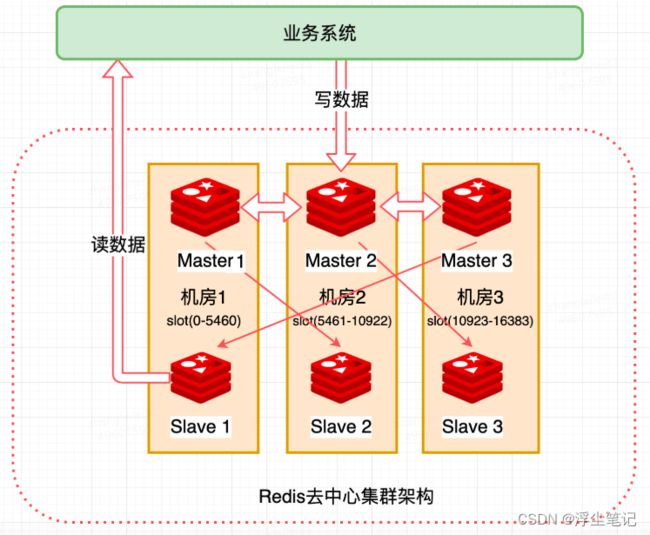
- 三机房部署,每个机房有一主一从,即一个 Master 对应一个 Slave。机房 1 中的 Master 1 连接的 Slave 在机房 2,机房 2 中的 Master 2 连接的 Slave 在机房 3,机房 3 中的 Master 3连接的 Slave 在机房 1,这样构成了一个环。
- 其中一主一从构成一个分片,之间通过异步复制同步数据,一旦某个机房掉线,则分片上位于另一个机房的 slave 会被提升为 master,从而可以继续提供服务;每个 master 负责一部分slot,数目尽量均摊;客户端对于某个 Key 操作先通过公式计算出所映射到的slot,然后直连某个分片,写请求一律走 master,读请求根据路由规则选择连接的分片节点。
- Master 负责写,Master 会自动同步到 Slave,假设机房 1 的机器全部断电了,机房1的Master 写服务宕机,此时 Slave 读服务会被提升为 Master ,也就是说机房 1 的数据在机房 2 的 Slava2 上还有备份,数据还在,在宕机的 master 没有恢复前 Slave 要同时承担读写服务,虽然累一点,但是系统仍然能提供服务。
- 如果单个机房距离很远, Master 1 的数据同步到 Slave2 上是跨机房同步,肯定不如同机房快,这样一来 Slave2 负责的读就会有延迟,Master1 要更新的数据还没有同步到他在另一个机房的备份前,读操作就是不一致的,这样设计牺牲掉一致性(C)。
缓存雪崩、击穿、穿透
很多人在处理缓存和数据库同步问题的思路是这样的:先查缓存,如果缓存没有,则去查数据库,然后更新缓存,如下图所示:
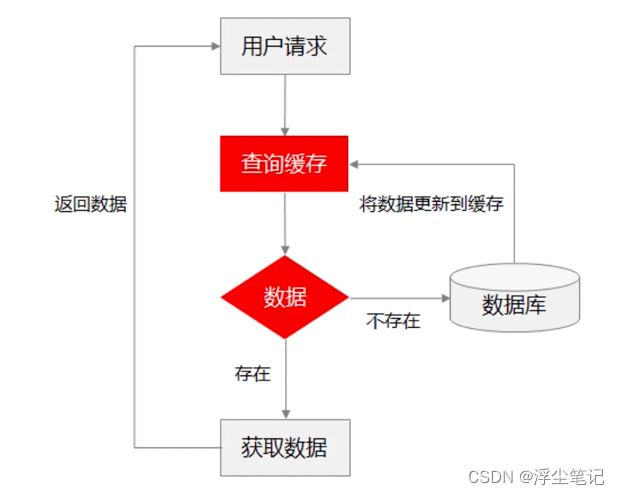
这样设计在数据量小的时候基本没啥问题,如果数据量大,遇到缓存中热点key集中失效,就很可能引发雪崩或者穿透;
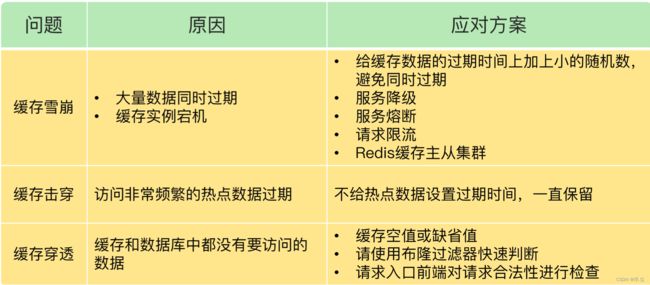
雪崩 就是缓存中大批量热点数据过期后,系统的大量请求犹如雪崩一般涌入,引起数据库压力,造成数据库查询堵塞甚至宕机。解决办法:
- 将缓存失效时间分散开,比如每个 key 的过期时间是随机,防止同一时间大量数据过期现象发生,这样不会出现同一时间全部请求都落在数据库层。如果缓存数据库是分布式部署,将热点数据尽可能均匀分布在不同 Redis 和数据库中,有效分担压力,别让一台机器扛着压力。
- 简单粗暴,让 Redis 数据永不过期,人为手动控制删除已过期的数据。
穿透 是调用者发起的请求参数(key)在缓存和数据库中都不存在,绕过 Reids,通过不存在的 key成功穿透到数据库层或者更底层,大规模不断发起不存在的 key 的请求,会导致系统压力过大最后故障。解决办法:
- 分布式布隆过滤器:Redis 自身支持布隆(BloomFilter),参考:Redis(十) 布隆过滤器
- 返回空值:遇到数据库和 Redis 都查询不到的值,在 Redis 里设置一个缺省值,过期时间很短,目的在于同一个 key 再次请求时直接返回 null,避免穿透。
击穿 和穿透类似,是指一个 key 是热点 key,某个瞬间会有成千上万次请求(比如微博热点排行榜,key 是小时时间戳,value 是个 list 的榜单)。每个小时产生一个 key,这个key 会有百万 QPS,如果这个 key 失效了,就像保险丝熔断,百万 QPS 直接压垮数据库。解决办法:
- 对于访问特别频繁的热点数据就不设置过期时间了,让key永久有效,然后手动控制删除key。
关于缓存雪崩、穿透、击穿的更多内容请查看:缓存雪崩、缓存击穿、穿透穿透具体指哪些问题?_浮尘笔记的博客-CSDN博客
高并发场景下缓存和数据库更新策略
如果更新一个数据,先更新据库再更新缓存,可能出现高并发场景下的缓存和数据库中数据不一致问题。如果有多个线程同时更新数据库,然后更新缓存,可能出现下面的情况:
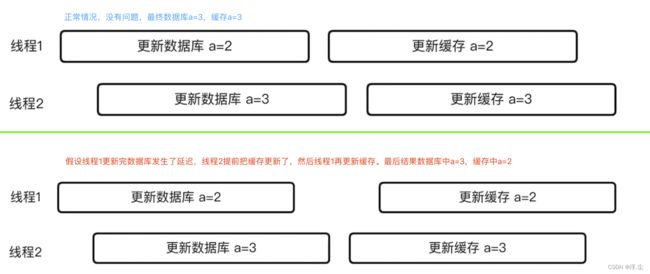
针对这个问题,有一个办法,就是先更新数据库,再删除缓存,等待下次读取数据的时候再从数据库读取最新值,然后写入新的缓存:
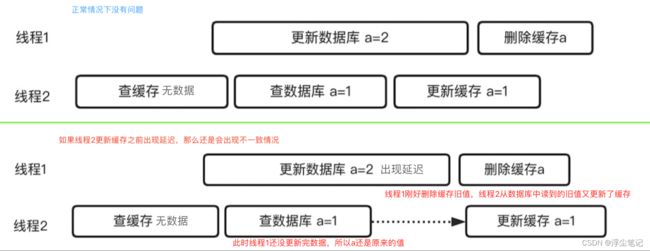
怎么解决?可以使用 延迟双删,具体二次删除缓存延迟多久,基本上要大于一次更新操作所花费的时间。如果第二次删除失败,可以放到队列中循环删除。

总结:优先查询缓存,如果缓存未命中则查询数据库,将结果写入缓存;数据更新时先更新数据库,再删除缓存,然后一段时间后再延迟删缓存(防止并发场景下操作出现问题)。
Redis的大key和热key和大value
正常情况下,Redis 集群中数据都是均匀分配到每个节点,请求也会均匀的分布到每个分片上,但在一些特殊场景中(比如外部爬虫、攻击、热点商品、热搜话题等),这种短时间内某些 key 访问量过于大,对于这种相同的 key 会请求到同一台数据分片上,导致该分片负载较高成为瓶颈,导致雪崩等一系列问题。
热点数据最大的问题会造成 Reids 集群负载不均衡(也就是数据倾斜)导致的故障,这些问题对于 Redis 集群都是致命打击。造成 Reids 集群负载不均衡故障的主要原因:
- 高访问量的 Key,也就是热 key,如果一个 key 访问的 QPS 超过 1000 就要特别注意了,比如热门商品,热门话题等。
- 大 Value,有些 key 访问 QPS 虽然不高,但是由于 value 很大,造成网卡负载较大,网卡流量被打满,单台机器可能出现千兆/秒,IO 故障。
- 热点 Key + 大 Value 同时存在,服务器杀手。
热点 key 或大 Value 会造成哪些故障:
- 数据倾斜问题:大 Value 会导致集群不同节点数据分布不均匀,造成数据倾斜问题,大量读写比例非常高的请求都会落到同一个 redis server 上,该 redis 的负载就会严重升高,容易打挂。
- QPS 倾斜:分片上的 QPS 不均。
- 大 Value 会导致 Redis 服务器缓冲区不足,造成 get 超时。
- Redis 缓存失效导致数据库层被击穿的连锁反应。
如何准确定位热点数据?
- 根据业务情况,人工预估统计可能会成为热点的数据,比如 促销活动商品,热门话题等。
- 在调用端统计某些key的请求次数,但是无法预知具体是哪些key,代码侵入性强。
- Redis 集群代理层统计:像 Twemproxy、codis 这些基于代理的 Redis 分布式架构,统一的入口,可以在 Proxy 层做收集上报,但是缺点很明显,并非所有的 Redis 集群架构都有 proxy。
- Redis 服务端收集:监控 Redis 单个分片的 QPS,发现 QPS 倾斜到一定程度的节点进行 monitor,获取热点 key, Redis 提供了 monitor 命令,可以统计出一段时间内的某 Redis 节点上的所有命令,分析热点 key,在高并发条件下,会存在内存暴涨和 Redis 性能的隐患,所以此种方法适合在短时间内使用;同样只能统计一个Redis 节点的热点 key,对于集群需要汇总统计,实现起来比较麻烦。
如何解决热点数据问题:主要从两个方面考虑,第一是数据分片,让压力均摊到集群的多个分片上,防止单个机器打挂;第二是迁移隔离。
- key 拆分:如果当前 key 的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前 hash 进行拆分,这样该热点 key 可以拆分为若干个新的 key 分布到不同 Redis 节点上,从而减轻压力。
- 迁移热点 key:以 Redis Cluster 为例,可以将热点 key 所在的 slot 单独迁移到一个新的 Redis 节点上,这样这个热点 key 即使 QPS 很高,也不会影响到整个集群的其他业务,还可以定制化开发,热点 key 自动迁移到独立节点上,这种方案也叫做:多副本。
- 热点 key 限流:对于读命令 可以通过迁移热点 key 然后添加从节点来解决,对于写命令 可以通过单独针对这个热点 key 来限流。
- 增加本地缓存:对于数据一致性不是很高的业务,可以将热点 key 缓存到业务机器的本地缓存中,因为是业务端的本地内存中,省去了一次远程的 IO 调用。但是当数据更新时,可能会造成业务和 Redis 数据不一致。
Redis存储的大 Value 如何优化?
- 由于 Redis 是单线程运行的,如果一次操作的value 很大会对整个 redis 的响应时间造成影响,因为 Redis 是 Key-Value 结构数据库,大 value 就是单个 value 占用内存较大,对 Redis 集群造成最直接的影响就是数据倾斜。
- 一般如果 string 类型的 value > 10KB,set、list、hash、zset 等集合数据类型中的元素个数 > 1000个就算是大value;如果string 类型 value > 100KB,set、list、hash、zset 等集合数据类型中的元素个数 > 10000个就算是超大value。
- 一个较大的 key-value 可以拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响;可以将拆分后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
更多关于Redis的优化方案请查看:Redis 常见的性能问题和优化方案
本地缓存
同样是内存里读写数据,为啥使用本地缓存就会更快?
因为本地缓存的请求是当前服务器上的,相比于请求 Redis或者MySQL都是要转发一次到对应的数据库服务器,而当前代码和Redis服务器可能都不在同一个机房(跨机房,甚至是异地),Redis 相比本地缓存,多一次网络 IO,那肯定不如在本地获取数据快。
常用的本地缓存框架:Google Guava、Ehcache、Spring Cache、Java Map。