【多线程】阻塞队列

1. 认识阻塞队列和消息队列
阻塞队列也是一个队列,也是一个特殊的队列,也遵守先进先出的原则,但是带有特殊的功能。
如果阻塞队列为空,执行出队列操作,就会阻塞等待,阻塞到另一个线程往阻塞队列中添加元素(队列不空)为止
如果阻塞队列满了,执行入队列操作,就会阻塞等待,阻塞到另一个线程从阻塞队列中取出元素(队列不满)为止
上述这两条特性,希望大家能有个好的认识,有了这两条特性,也是我们后续模拟实现一个阻塞队列的基础。
消息队列也是一个特殊的队列,在阻塞队列的基础上,加上了一个 "消息类型",按照指定的类型进行先进先出。
注意这里我们谈到的消息队列仍然是一个数据结构。
由于消息队列很好用,因此就有业内牛人,把这样的数据结构,单独实现成了一个程序,这个程序,可以通过网络的方式和其他程序进行通信,类似于 MySQL 这样的客户端。
此时由于单独实现了一个程序,此时这个消息队列就能单独的部署到一组服务器上,此时存储能力和转发能力都大大提升了,在很多大型的项目里,都能看到这样的消息队列的身影,于是消息队列就能和 MySQL,redis 相提并论了,成为了一个重要的组件,称为 "中间件"。
行内常见的消息队列有:rabbit mq,active mq,rocket mq,kafka......
如何理解消息队列呢?这里用一个形象的例子来介绍:
假设你是个渣男帅哥,追你的妹子排起了很长的队伍,有可爱类型的,有高冷类型的,有憨憨类型的...
你每天都要找一个妹子约会,于是你今天发个说说:想跟我约会的妹子,来我家门口排好队等我吧,于是喜欢你的妹子纷纷来到了你家门口:

假设你今天上午想找一个憨憨类型的妹子去约会,那么就需要从排队的人中选一个憨憨类型的妹子出来,但是排在最前面的并不是憨憨类型的妹子,但是不影响,因为你今天的规划,就是憨憨类型的妹子优先级最高!
那么排队的妹子中,有两个憨憨类型的妹子,选哪个呢?这次就是按照顺序来了!谁先来,你选谁!
假设你上午睡过头了呢?家门口排满了,此时还想等你的妹子就只能等着,等下次了,假设没有妹子等你呢?那你就得坐在家门口等妹子嘛,这也是类似于阻塞队列的效果,队列为空,或者队列为满的情况。
上述这样的例子,就类似于消息队列,队列中每个元素都有类型,按照指定类型遵循先进先出的原则!
2. 生产者消费者模型
2.1 认识生产者消费者模型
为啥消息队列香?因为他和阻塞队列特性关系非常大。
而阻塞队列的一个典型应用场景就是 "生产者消费者模型",这是一种非常典型的开发模型。
这里我们也通过一个生活中的例子来理解生产者消费者模型:
不知道大家有没有包过饺子,这里把包饺子抽象成两个步骤:擀饺子皮,包饺子。

此时有小明,小强,小王,小李这四个人一起包饺子,怎么包呢?有两个可选方案:
每个人分别擀自己的饺子皮,自己包

小明负责擀饺子皮,擀完后放在盘子里,小强,小王,小李从盘子中取饺子皮负责包饺子。
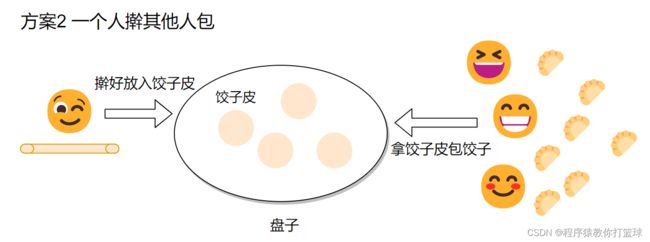
那么方案二就类似于生产者消费者模型:
擀饺子皮的人:生产者
盘子:阻塞队列/消息队列
取饺子皮包饺子的人:消费者
如果小明擀的慢,盘子上没有饺子皮了,其他人就得等着,如果小明擀的快,盘子上饺子皮放满了,小明就得等着,不要擀了。
这里与我们前面说的阻塞队列满/阻塞队列空的情况相互对应上了!
2.2 阻塞队列实际中的实用
有了上面的例子,我们再来结合实际中开发的情况,进一步了解阻塞队列/消息队列在实际开发中的实用吧:
服务器之间的调用:
假设现在有一个客户端程序(游戏),需要充值钻石了,没有使用阻塞队列/消息队列的情况:
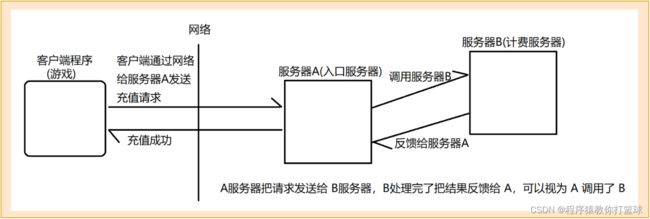
上述没有使用阻塞队列的情况,就是属于耦合太高了,写代码通常追求高内聚,低耦合,高耦合指的是什么呢?
高耦合:两个程序之间关联太高了,如果一方出现问题可能会影响另一方。
就比如上述情况,服务器A 想给服务器B 发送请求(调用B),必须知道 B 的存在,如果 服务器B 挂了,是有可能引起服务器A 的 BUG 的!此时如果还需要增加一个存放充值日志的服务器C,那么 服务器A 的代码是要进行调整的,对于程序猿来说,显然不喜欢麻烦!
那么这样的场景,使用生产者消费者模型就能有效的降低耦合,让两个服务器之间的关联变低。
引入消息队列:
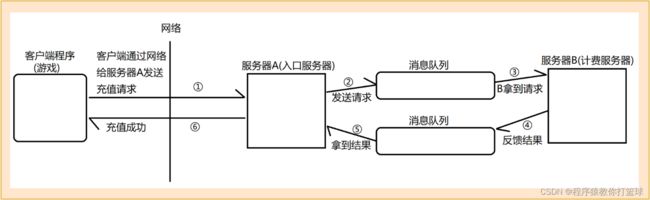
这样一来,服务器A 和 服务器B 之间就没多大的关系了,服务器A 只需要知道往哪个队列放,从哪个队列取,服务器B 也是同理,而且在实现服务器A 的代码中,没有一行与服务器B 相关的代码,实现服务器B 的代码中,也没有一行与服务器 A 相关的代码。
此时耦合就被大大的降低了,如果服务器B 挂了,对服务器A 是没有影响的,此时如果 A 从队列中取,发现没有结果,就可以视为充值失败,这样一来,就可以排查 B 的问题了。
同时利用生产者消费者模型,还可以有效控制请求的访问量,不至于一下子并发太高了,把服务器B 给搞挂了,就比如之前鹿晗官宣的时候,此时用户发送的请求量是不可预估的,而利用生产者消费者模型就能很好的解决这个问题。
3. 模拟实现一个阻塞队列
Java 本身也是给我们提供了阻塞队列的:BlockingQueue 这是一个接口,实现这个接口的有如下类:
LinkedBlockingQueue 基于链表实现的阻塞队列
PriorityBlockingQueue 基于堆实现的阻塞队列
ArrayBlockingQueue 基于数组实现的阻塞队列
阻塞队列本身是一种特殊的队列,就是在普通队列上引入阻塞的功能,主要的阻塞方法有两个:
入队列:put
出队列:take
想要实现一个阻塞队列,就需要先实现一个普通的队列,然后再将这个队列改造成带有阻塞功能的队列即可。
对于普通队列的实现,我们可以采取链表,数组的方式,这里我们就基于数组的结构来实现(环形队列)。
实现环形队列,我们需要区分队列满了,和队列空的两种情况。
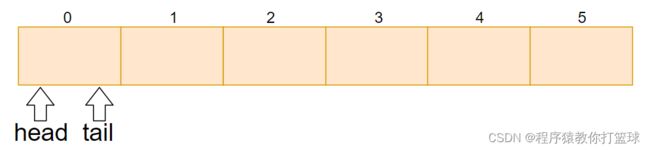
初始的时候,head 和 tail 指向同一个位置,当插入元素的时候在 tail 位置插入,然后 tail++ 即可,出元素的时候,head++即可,所以当 head == tail 的时候,队列为空。
那么问题来了:

此时队列是满的,但是 head == tail 条件也成立!这样一来我们就无法判断队列为空,还是队列满了。
有两种解决方案:
浪费一个空间上述当 tail 走到 5 下标位置就判断满了
定一个 size 变量,记录当前队列中元素个数
这里我们就采用 size 来记录队列中元素个数吧:
public class MyArrayBlockQueue {
private T[] elem;
private int head;
private int tail;
private int size;
public MyArrayBlockQueue(int capacity) {
elem = (T[])new Object[capacity];
head = 0;
tail = 0;
size = 0;
}
public void put(T value) {
// 如果队列满了, 则不能插入元素
if (size == elem.length) {
return;
}
elem[tail++] = value;
// 防止 tail 越界, 修正 tail 位置
if (tail >= elem.length) {
tail = 0;
}
size++;
}
public T take() {
// 如果队列为空, 则不能出队列
if (size == 0) {
return null;
}
T result = elem[head++];
// 防止 head 越界
if (head >= elem.length) {
head = 0;
}
size--;
return result;
}
} 最基本的环形队列我们就写好了,接下来就要在这个基础上,增加阻塞功能,保证多线程情况下的线程安全问题。
public synchronized void put(T value) throws InterruptedException {
// 如果队列满了, 则阻塞等待
while (size == elem.length) {
this.wait();
}
elem[tail++] = value;
// 防止 tail 越界, 修正 tail 位置
if (tail >= elem.length) {
tail = 0;
}
size++;
// 唤醒 take() 中的 wait, 告诉他队列不为空, 可以出队列了
this.notify();
}
public synchronized T take() throws InterruptedException {
T result;
// 如果队列为空, 则也需要阻塞等待
while (size == 0) {
this.wait();
}
result = elem[head++];
// 防止 head 越界
if (head >= elem.length) {
head = 0;
}
size--;
// 唤醒 put() 中的 wait, 告诉他队列没有满, 可以入队列了
this.notify();
return result;
}这样就能保证线程安全了,上述我们把队列满和空的情况时使用的 if 替换成了 while,这是因为在 Java 标准中,表述了使用 wait 方法可能会中断,存在虚假唤醒的情况,建议使用 wait 方法时,应该在循环内使用。
有了这个阻塞队列,大家就能多创建几个线程,利用阻塞队列模拟包饺子的场景了,这里我就不提供代码了。
下期预告:【多线程】模拟实现定时器