词云-将豆瓣短评制作成词云
词云
什么是词云
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
比如 哔哩哔哩周杰伦—《Mojito》弹幕的词云

我们能清楚这些弹幕中次数最多的次东西,**好听,杰伦,爷青回…**请忽略内裤…
词云生成规则
我们这种关键词云是对海量文字内容中出现频率较高的“关键词”的视觉突出,即出现越多的“关键词”字体越大
如何制作词云呢
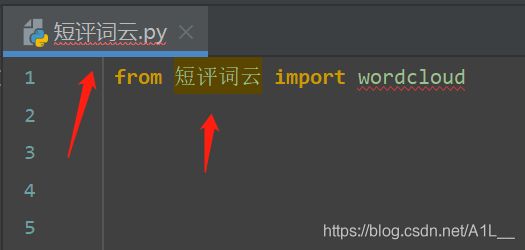
首先我们创建一个python文件取名为wordcloud(注意不要取名为跟库一样的名字,我在踩坑)
然后我们在pycharm中的Treminal安装词云库
pip install wordcloud
首先我们导入模块就给我们提示报错了ImportError: cannot import name 'wordcloud' from 'wordcloud'
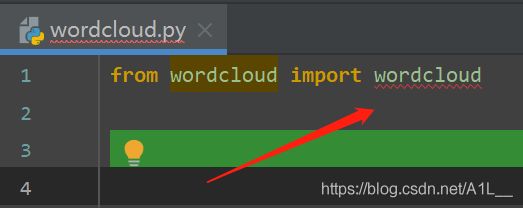
这个错误就是我们把文件名取成了模块名(修改文件名)
我们调用词云的绘制方法WordCloud,Word cloud object for generating and drawing.
这里我们主要用到其中的几个参数就可以画出一个简单的词云图
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
我们先设置绘制方法 字体为彩云,高200宽400,比例15,然后背景为粉红
w = wordcloud.WordCloud(
font_path=r"C:\Windows\Fonts\STCAIYUN.TTF"", # 打开C盘搜索font就可以了 这是华文彩云字体
width=400,
height=200,
scale=15,
background_color="pink"
)
然后我们再打开我们需要的文件,将它读取
with open("['肖申克的救赎 短评'].txt", "rt", encoding="utf-8")as f:
text = f.read()
读取之后啊我们就可以用之前定义的w方法来绘制了
w.generate(text) # Generate wordcloud from text 从文档中生成词云
w.to_file("肖申克.jpg") # Export to image file 导出图像文件 png or jpg

这样我们就得到了一个简单的词云图
改进
但是这样还是不太明确对吧有些都还是句子, 而且效果也不是很好,我们再修改一下w的参数 换个字体换个背景,如果我们要让词云生成更精确的单词我们就需要用到 jieba库还是老方法 pip install jieba
ieba是python的一个中文分词库,下面介绍它的使用方法
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
在这里我们主要用它的精确模式
运用jieba库中的lcut方法,他会根据语义,组成精确的最匹配的词语并直接给我们返回一个词语的列表

我们把这个短评文本处理一下
txt_list = jieba.lcut(txt) # 结巴处理文件返回词语列表
for i in txt_list: # 我们要去除列表中的干扰字符,书名号,冒号 列表符号等等....
if i in "[],,'《》":
txt_list.remove(i)
string = ",".join(txt_list) # 然后再将列表拼接成字符串
最后我们得到了一个更精确的词云图
完整代码附上
from wordcloud import wordcloud
import jieba
w = wordcloud.WordCloud(font_path=r"C:\Windows\Fonts\simhei.ttf", # 雅黑
width=400,
height=200,
scale=10,
background_color="white" # 背景颜色
)
with open("['肖申克的救赎 短评'].txt", "rt", encoding="utf-8")as f: # 文件可自选
txt = f.read()
txt_list = jieba.lcut(txt)
for i in txt_list:
if i in "[],,'《》":
txt_list.remove(i)
string = ",".join(txt_list)
w.generate(string)
w.to_file('肖申克.png')
词云与结巴库的方法后续介绍