OLAP系列:四、clickhouse分布式表使用指南
一、背景
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于innodb之于Mysql。 而且基于MergeTree,还衍生出了很多小弟,也是非常有特色的引擎。
本篇简单介绍基于MergeTree引擎建表以及分布式表的使用,更多基础概念和知识点请关注官网文档介绍。
二、分布式表实践
1、前序准备
请参考系列-上篇文章关于集群部署的说明。
2、查询集群信息
SELECT * FROM system.clusters;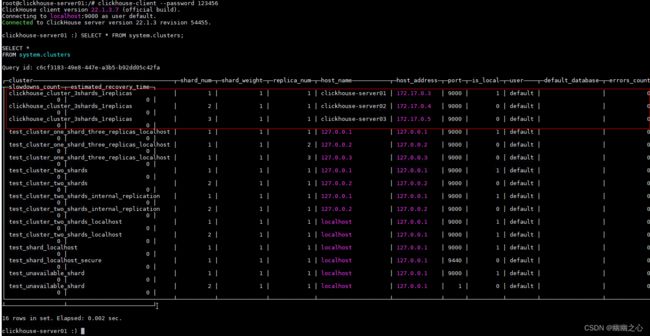
3、创建数据库
CREATE DATABASE IF NOT EXISTS db_crm_sh
ON CLUSTER clickhouse_cluster_3shards_1replicas;4、创建本地表
/****************
【选一个节点】创建好本地表后,在1个节点创建,会在其他节点都存在。
clickhouse_cluster_3shards_1replicas 集群名字
****************/
create table IF NOT EXISTS db_crm_sh.T_C_BAL_FUND_LOCAL
ON CLUSTER clickhouse_cluster_3shards_1replicas
(
cust_no String,
fund_acco_no String,
agency_no String,
fund_code String,
share_type String,
last_shares Decimal(16,2),
f_netvalue String,
fdate String,
last_asset Decimal(16,2),
ta_no String,
cust_type String,
trade_acco_no String,
version Int
) ENGINE = MergeTree()
ORDER BY cust_no
PARTITION BY version
;5、创建分布式表
分布式表实际上是一个视图,因此它需要与分片(服务器节点)具有相同的表结构定义。创建视图后,将在每个分片(服务器节点)上查询数据,并将结果聚合到最初调用查询的节点上。
/***************
【选一个节点】创建分布式表名 T_C_BAL_FUND,在1个节点创建,会在其他节点都存在。
clickhouse_cluster_3shards_1replicas集群名
db_crm_sh数据库名
T_C_BAL_FUND_SH表名
***************/
CREATE TABLE IF NOT EXISTS db_crm_sh.T_C_BAL_FUND
ON CLUSTER clickhouse_cluster_3shards_1replicas
as db_crm_sh.T_C_BAL_FUND_LOCAL
ENGINE = Distributed(clickhouse_cluster_3shards_1replicas,
db_crm_sh,
T_C_BAL_FUND_LOCAL,
hiveHash(cust_no));6、插入数据(操作分布式表)
/******************
【插入数据到分布式表 会根据策略存储在不同节点的本地表中】
******************/
INSERT INTO db_crm_sh.T_C_BAL_FUND
(cust_no, fund_acco_no, version)
VALUES
('000001','000001', 6),
('000002','000002', 6),
('000003','000003', 6);7、查询分布式表(合并各节点数据)
/***************
【任意节点查询-分布式,全部数据】
***************/
select * from db_crm_sh.T_C_BAL_FUND t;8、查询节点本地表(只查询本节点存储数据)
select * from db_crm_sh.T_C_BAL_FUND_LOCAL tcbfl;9、删除分布式表(本地表数据不会被删除)
drop table IF EXISTS db_crm_sh.T_C_BAL_FUND
ON CLUSTER clickhouse_cluster_3shards_1replicas;10、删除本地表(需要标明集群)
drop table IF EXISTS db_crm_sh.T_C_BAL_FUND_LOCAL
ON CLUSTER clickhouse_cluster_3shards_1replicas;11、批量删除表数据(操作本地表指定集群)
alter table db_crm_sh.T_C_BAL_FUND_LOCAL
ON CLUSTER clickhouse_cluster_3shards_1replicas
delete where version <= 8;12、修改数据(操作本地表,OLAP数据库尽量避免使用)
想要更新分布式表的数据时,可以通过更新本地表的数据来完成。不过在更新本地表的数据时,必须指定 on cluster xxx。否则只会在其中一个节点中进行操作。另外,不能直接更新分布式表。
alter table db_crm_sh.T_C_BAL_FUND_LOCAL
ON CLUSTER clickhouse_cluster_3shards_1replicas
update fund_acco_no = '000022' where cust_no = '000002';
13、修改本地表名(存在问题:集群其他节点数据未被修改)
rename table db_crm_sh.T_C_BAL_FUND_LOCAL
to db_crm_sh.T_C_BAL_FUND_LOCAL1;三、补充说明
1、抛砖引玉
本章主要介绍了分布式表的基本操作,读者可以结合实际的业务使用场景探索适合自己项目的使用模式。
2、MergeTree的扩展
MergeTree存在一系列扩展引擎,比如ReplacingMergeTree、SummingMergeTree等,读者可以参考官方说明尝试使用。
参考文档
ClickHouse实战--使用分布式表_clickhouse 分布式表_一 铭的博客-CSDN博客
表引擎 | ClickHouse Docs