linux下HDFS Shell命令使用 大全
hadoop fs与hdfs dfs的命令的使用是相似的,本实验使用的是hdfs dfs命令,所有命令的操作都是在hadoop用户下进行。
rm删除目录和文件
使用方法:hdfs dfs -rm [-f] [-r|-R] [-skip Trash]
表二rm命令的选项和功能
| 选项 |
说明 |
| -f |
如果要删除的文件不存在,不显示提示和错误信息 |
| -r|R |
级联删除目录下的所有文件和子目录文件 |
| -skipTrash |
直接删除,不进入垃圾回车站 |
示例1:删除文件
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
[hadoop@master ~]$ hdfs dfs -rm /test/dir0/file3
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
结果:
删除前

删除后

删除目录及目录下的目录和文件
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
[hadoop@master ~]$ hdfs dfs -rm -r /test/dir0
[hadoop@master ~]$ hdfs dfs -ls -R /test/
结果:
删除前![]()
删除后 
put/get:上传/下载
使用方法: hdfs dfs -put [-f] [-p]
hdfs dfs -get [-p] [-ignoreCrc] [-crc]
put将本地文件系统的复制到HDFS文件系统的目录下
get 将HDFS中的文件复制到本地文件系统中,与-put命令相反
-f如果文件在分布式文件系统上已经存在,则覆盖存储,若不加则会报错;-p保持源文件的属性(组、拥有者、创建时间、权限等);-ignoreCrc同上。
示例1:把本地新建的文件test.txt放到分布式文件系统主目录下,保存名为hfile;(如图2-12所示)
[hadoop@master ~]$ touch /tmp/test.txt
[hadoop@master ~]$ ls -l /tmp/test.txt
[hadoop@master ~]$ hdfs dfs -put /tmp/test.txt /test/hfile
[hadoop@master ~]$ hdfs dfs -ls /test/

把分布式文件系统目录下的文件复制到本地
[hadoop@master3 hadoop]$ hdfs dfs -get /test/hfile /home/hadoop/hfile
[hadoop@master ~]$ ls -l /home/hadoop/hfile
![]()
把本地新建的文件test.txt放到分布式文件系统主目录下,覆盖原来的文件[hadoop@master ~]$ hdfs dfs -ls /test/hfile
![]()
[hadoop@master ~]$ hdfs dfs -put -f /home/hadoop/hfile /test/hfile
[hadoop@master ~]$ hdfs dfs -ls /test/hfile

把本地新建的文件test.txt放到分布式文件系统主目录下,保持源文件属性
[hadoop@master ~]$ ls -l /home/hadoop/file
![]()
[hadoop@master ~]$ hdfs dfs -put -p /home/hadoop/file /test/
[hadoop@master ~]$ hdfs dfs -ls /test/file

mkdir:创建文件夹
使用方法:hdfs fs -mkdir [-p]
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例1:在分布式主目录下新建文件夹test
[hadoop@master ~]$ hdfs dfs -mkdir /test
[hadoop@master ~]$hdfs dfs -ls /
示例2:在根目录下新建文件夹/test/dir0/dir1,如果上一级目录不存在,需要使用到-p参数。
[hadoop@master ~]$ hdfs dfs -mkdir -p /test/dir0/dir1
[hadoop@master ~]$ hdfs dfs -ls /test/dir0

touchz:新建文件
使用方法:hdfs fs -touchz URI [URI …]
当前时间下创建大小为0的空文件,若大小不为0,返回错误信息。
示例:在/test/下新建文件file1
[hadoop@master ~]$ hdfs dfs -touchz /test/file1
[hadoop@master ~]$ hdfs dfs -ls /test/
ls 列指定目录文件和目录
使用方法:hdfs dfs -ls [-d][-h][-R]
表一ls命令选项和功能
| 选项 |
功能说明 |
| -d |
返回paths |
| -h |
按照KMG数据大小单位显示文件大小,如果没有单位,默认认为B |
| -R |
级联显示paths下文件,这里paths是个多级目录 |
示例1:列出/test目录下的所有文件和目录信息
[hadoop@master ~]$ hdfs dfs -ls /test

示例2:列出/test目录信息
[hadoop@master ~]$ hdfs dfs -ls -d /test
![]()
列出目录和文件的大小
[hadoop@master ~]$ hdfs dfs -ls -h /test

cat、text、tail:查看文件内容
使用方法:hdfs dfs -cat/text [-ignoreCrc]
Hdfs dfs -tail [-f]
其中:-ignoreCrc忽循环检验失败的文件;-f动态更新显示数据,如查看某个不断增长的文件的日志文件。
3个命令都是在命令行窗口查看指定文件内容。区别是text不仅可以查看文本文件,还可以查看压缩文件和Avro序列化的文件,其他两个不可以;tail查看的是最后1KB的文件(Linux上的tail默认查看最后10行记录)。
[hadoop@master ~]$ hdfs dfs -cat /test/file

[hadoop@master ~]$ hdfs dfs -text /test/file
[hadoop@master ~]$ hdfs dfs -tail /test/file
appendToFile:追写文件
使用方法:hdfs dfs -appendToFile
示例1.把本地文件系统文件追加到分布式文件系统中
[hadoop@master ~]$ cat /home/hadoop/file2
[hadoop@master ~]$ hdfs dfs -appendToFile /home/hadoop/file2 /test/file2
[hadoop@master ~]$ hdfs dfs -cat /test/file2

显示占用磁盘空间大小
使用方法: hdfs dfs -du [-s] [-h]
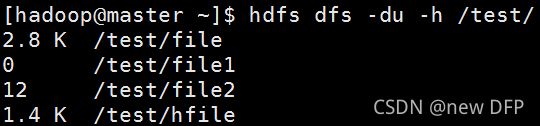
默认按字节显示指定目录所占空间大小。其中,-s显示指定目录下文件总大小;-h按照KMG数据大小单位显示文件大小,如果没有单位,默认为B。
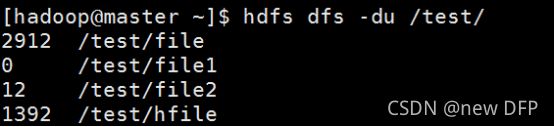
示例1:显示分布式主目录下文件和目录大小(如图2-22所示)
[hadoop@master ~]$ hdfs dfs -du /test/
[hadoop@master ~]$ hdfs dfs -du -h /test/
[hadoop@master ~]$ hdfs dfs -du -s /test/

cp复制文件
将文件从SRC复制到DST,如果指定了多个SRC,则DST必须为一个目录
使用方法:hdfs fs –cp SRC [SRC …] DST
示例1(如图2-25所示):
[hadoop@master ~]$ hdfs dfs -mkdir /test/dir0
[hadoop@master ~]$ hdfs dfs -cp /test/file2 /test/dir0
[hadoop@master ~]$ hdfs dfs -ls /test/dir0

chmod修改文件权限
使用方法:hdfs fs -chmod [-R]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
示例1(如图2-26所示):
[hadoop@master ~]$ hdfs dfs -chmod 777 /test/file2
[hadoop@master ~]$ hdfs dfs -ls /test/file2
![]()
[hadoop@master ~]$ hdfs dfs -chmod -R 777 /test/dir0/
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0

chown修改文件属主和组
使用方法:hdfs dfs -chmod [-R]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
示例1(如图2-28所示):
[hadoop@master ~]$ hdfs dfs -chown hadoop:hadoop /test/file2
[hadoop@master ~]$ hdfs dfs -ls /test/file2

[hadoop@master ~]$ hdfs dfs -chown -R hadoop:hadoop /test/dir0
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0

chgrp修改文件属组
使用方法:hdfs fs -chgrp [-R] GROUP URI [URI …]
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
[hadoop@master ~]$ hdfs dfs -ls /test/file5
[hadoop@master ~]$ hdfs dfs -chgrp hadoop /test/file5
[hadoop@master ~]$ hdfs dfs -ls /test/file5

[hadoop@master ~]$ hdfs dfs -ls -R /test/dir1
[hadoop@master ~]$ hdfs dfs -chgrp -R hadoop /test/dir1
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir1

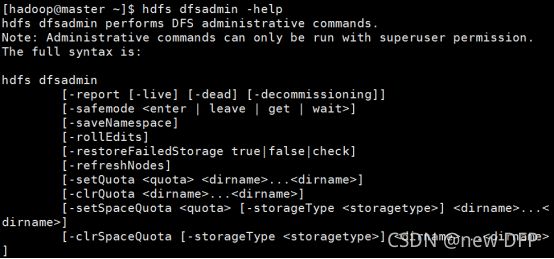
dfsadmin显示HDFS运行状态和管理HDFS
dfsadmin是一个多任务客服端工具,用来显示HDFS运行状态和管理HDFS,文件的命令(如图2-32所示):
[hadoop@master ~]$ hdfs dfsadmin -help

Namenode 格式化升级回滚
运行namenode进行格式化、升级回滚等操作
表四namenode选项和功能
| 命令选项 |
功能描述 |
| -format |
格式化元数据节点。先启动元数据节点,然后格式化,最后关闭 |
| -upgrade |
元数据节点版本更新后,应该以upgrade方式启动 |
| -rollback |
回滚到前一个版本。必须先停止集群,并且分发旧版本才可用 |
| -importCheckpoint |
从检查点目录加载镜像,目录由fs.checkpoint.dir指定 |
| -finalize |
持久化最近的升级,并把前一系统状态删除,这个时候再使用rollback |
fsck检查实用程序
fsck命令运行HDFS文件系统检查实用程序,用于和MapReduce作业交互。
表五fsck选项和功能
| 命令选项 |
功能描述 |
| -path |
检查这个目录中的文件是否完整 |
| -move |
移动找到的已损坏的文件到/lost+found |
| -rollback |
回滚到前一个版本。必须先停止集群,并且分发旧版本才可用 |
| -delete |
删除已损坏的文件 |
| -openforwrite |
打印正在打开写操作的文件 |
| -files |
打印正在检查的文件名 |
| -blocks |
打印block报告(需要和-files参数一起使用) |
| -locations |
打印每个block的位置信息(需要和-files参数一起使用) |
| -racks |
打印位置信息的网络拓扑图(需要和-files参数一起使用) |
检查目录中文件完整性
[hadoop@master ~]$ hdfs fsck /test/dir0

移动找到已损坏的文件(
[hadoop@master ~]$ hdfs fsck -move

删除已损坏的文件
[hadoop@master ~]$ hdfs fsck -delete

检查HDFS系统上/test目录下的块信息和文件名
[hadoop@master ~]$ hdfs fsck /test -blocks -files
