阅读ConcurrentHashMap源码,我学到了什么?
文章目录
-
- ConcurrentHashMap怎样保证线程安全的
- put元素的流程
- 具体对于红黑树是怎样保证线程安全的
- 如何并发安全的初始化一个数组
- 如何统计存储元素个数的
- 怎样进行多线程扩容的
首先说明, 本篇分析基于jdk1.8.
ConcurrentHashMap怎样保证线程安全的
ConcurrentHashMap主要是通过Unsafe操作+synchronized关键字保证并发安全.
Unsafe操作主要负责并发安全的修改对象的属性或数组某个位置的值.
synchronized主要负责在需要操作某个位置时进行加锁. 这个位置不会为空,下面挂着一个链表或者红黑树.
put元素的流程
当向ConcurrentHashMap中put一个key,value时:
- 首先根据key计算对应的下标数组i,如果该位置没有元素,则通过自旋的方式向该位置赋值.
- 如果该位置与元素, 则会使用synchronized加锁.
- 加锁成功后,判断该元素的类型.
(1).如果是链表就添加到链表节点中.
(2).如果是红黑树就添加到红黑树中. - 添加成功后,根据该位置元素个数判断是否需要转成红黑树.
- 利用LongAdder的思想统计添加元素个数
- 判断是否需要扩容, 需要的话进行多线程扩容.
具体对于红黑树是怎样保证线程安全的
根据key计算对应的数组下标位置时, 如果该位置是红黑树,需要通过synchronized锁住该位置的节点去保证线程安全.
但是我们要想象一个场景,如果我们要锁这个红黑树的话,就需要锁它的根节点, 但是在并发的情况下,我们知道红黑树存在左移右移这些操作,就可能导致它的根节点发生变化,所以就不能锁这个根节点.那应该怎样做呢?
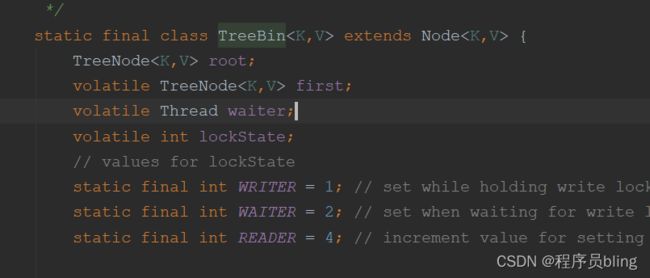
在源码中,对于红黑树结构, 其实会封装成TreeBin,这样有什么好处呢?
这个时候我们我们就把这个红黑树看作一个整体,封装成一个TreeBin对象,直接锁这个对象,就可以解决这个问题.而根节点作为这个对象的一个属性,这样即使发生变化, TreeBin对象也不会变.
如何并发安全的初始化一个数组
ConcurrentHashMap内部结构依然是数组+链表+红黑树.
而在最开始我们 new ConcurrentHashMap<>();的时候,并不会初始化Node数组, 只有在put的时候, 发现数组为null,才会进行初始化.
那这个步骤也就会涉及到并发问题, 那如果是你你会怎么初始化这个数组.其实就容易想到的就是双IF单例模式.源码中并没有这样做,让我们一起看一看是怎样处理的.
源码中主要是依靠数值去区分的,也就是这个sc.初始化是正数.
首先所有某个线程通过CAS去修改这个sc,修改成-1,只会有一个线程修改成功, 这个成功的线程就会去真正的初始化这个数组.
而其他的失败线程会重新循环, 这个时候这个数值就是负数,代表有其他线程正在初始化这个数组.此时调用yield()方法,让出cpu.
当数组初始化完毕后,所有线程都退出循环.

如何统计存储元素个数的
在map中我们需要统计存储元素的个数, 这个也是并发的.那怎样保证这个线程安全呢?
如果是我们自己的话,大概率会直接使用AtomicInteger, 但是这个在高并发的情况下,效率并不算高,因为是针对一个变量进行CAS的,也就是假如有一百个线程在put,在进行到统计总数的时候,这些线程得串行的一个一个处理成功才行.
在ConcurrentHashMap底层是怎样做的?
这里其实用了一个分散的思想,就是如果针对一个变量进行计数的话,竞争很激烈,那就利用hash,将其分散到不同的变量中去, 最后再统计数量的时候,就把这些数量相加即可.
如下:
在源码中会有一个baseCount,还会有一个Cell数组.
在计数的时候, 会对baseCount利用CAS+1,如果失败,会hash到Cell数组中的某个位置,对该位置上的数值利用CAS+1. 总之就是不断尝试, 利用CAS对不同位置进行+1,直到执行成功.
在最后计算总和的时候,会把baseCount和Cell数组中的每一个都加起来返回.

那这里使用分散的思想,又引入了一个数组,其实又带来了很多问题.
-
这个Cell数组设置多大呢?
不能设置的很大,因为如果在并发小的情况下,大了纯属浪费空间,应该最开始比较小,需要的话后面进行扩容. -
那什么时候应该扩容呢?什么时候不应该扩容?
(1).这个数组中的空值比较多不进行扩容
(2).如果冲突少也不进行扩容
怎么判断?
连续两次尝试遇到的位置都不为空,并且都没有CAS成功,这个时候才进行扩容. -
那数组的大小最大有没有什么限制?
肯定是有最大大小限制的,不能无限扩容,源码中用的是cpu核心数. -
这个数组是多线程操作的,怎么保证线程安全?
其实用了一个变量CellBusy,代表是否繁忙, 就相当于一个锁,当有线程在操作该数组的时候,会利用CAS把CellBusy设置为1,这个时候其他线程就不能对数组进行操作.从而保证线程安全.
那这种方法优点就是,利用分散的思想,减少竞争,提高了效率,这个其实也就是LongAdder的思想,在并发比较高的情况,可以优先使用这个.
怎样进行多线程扩容的
其实大体流程和HashMap中的扩容差不多, 都是新建一个数组, 按下标位置进行移动.如果这里不太熟悉的话,可以先看一下这个文章HashMap源码详解.
区别有两点:
-
怎样保证线程安全?
其实和它put元素时保证线程安全是一样的,直接对数组中的首节点Node进行synchronized加锁. -
单线程扩容容易理解, 但在源码中为了提升效率会使用多线程扩容, 是怎样处理的呢?
首先在进入扩容方法的瞬间会保证只有一个线程先进去,用CAS保证.
其次这里是可以多线程扩容关键就是分配步长, 就比如一个数组长度是4, 那么就分配前两个节点由线程1进行扩容,后两个节点由线程2进行扩容.
在分配步长的时候, 有两个关键变量, 就是即将分配的未来线程要处理的起始位置和末尾位置, 表示这个区间将由这个线程进行转移处理.
通过不断维护更新这两个变量, 对不同线程进行分配不同的区间,从而进行多线程扩容.当然这个维护更新这两个变量的这个动作是用CAS保证线程安全的.
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.
