如何在 K3s 中使用网络策略
本文将介绍如何在示例项目中使用网络策略,并解释它在 K3s 中的工作原理,从而帮助用户提高部署的安全性。
关于 K3s 对网络策略的支持存在一个普遍的误解,因为 K3s 默认使用 Flannel CNI,而 Flannel CNI 不支持网络策略。其实,K3s 使用 Kube-router 网络策略控制器为网络策略提供支持,所以网络策略也可以在 K3s 中使用,就像在其他 Kubernetes 发行版中一样。
正常的 Pod 相互通信
默认情况下,在 K3s 中,一个特定命名空间中的所有 services/Pod 都可以被任何其他命名空间中的所有其他 Pod 访问。

为了举例说明 Pod 如何相互通信,让我们在两个不同的命名空间(sample1 和 sample2)中使用简单的 nginx deployment 和 service 来测试,如下所示:
nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ngnix-service
spec:
selector:
app: nginx
type: ClusterIP
ports:
- protocol: TCP
port: 80
targetPort: 80
创建测试命名空间并将 nginx 部署到对应命名空间中:
# 在 sample1 中创建第一个示例应用
kubectl create ns sample1
kubectl apply -f nginx.yaml -n sample1
# 在 sample2 中创建第二个示例应用
kubectl create ns sample2
kubectl apply -f nginx.yaml -n sample2
接下来可以尝试在 Pod 中使用 curl 来检查 Pod 间的通信。
sample1 中的 pod -> sample2 命名空间中的 service:
# 从 sample1 访问 sample2
kubectl exec -n sample1 $(kubectl get po -n sample1 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample2.svc.cluster.local
# 从 sample1 访问 sample1
kubectl exec -n sample1 $(kubectl get po -n sample1 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample1.svc.cluster.local:80
sample2 中的 pod -> sample1 命名空间中的 service:
# 从 sample2 访问 sample1
kubectl exec -n sample2 $(kubectl get po -n sample2 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample1.svc.cluster.local:80
# 从 sample2 访问 sample2
kubectl exec -n sample2 $(kubectl get po -n sample2 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample2.svc.cluster.local:80
可以看到,以上命令均可以访问到对应目的地址,也就代表相互都可以通信。
使用 NetworkPolicy 限制 Pod 相互通信
NetworkPolicy Editor(https://editor.cilium.io/)是一个很好的 UI 工具,可以用于生成 Networkploicy,下面是一个示例。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: my-namespace
spec:
podSelector:
matchLabels:
role: db <1>
policyTypes:
- Ingress
ingress: <2>
- from:
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
<1> 这会选择当前命名空间中的特定 Pod 来匹配该策略。<2> 白名单入口规则列表。每个规则都允许与 from 部分匹配的流量。
可以在 ingress from 部分中指定四种选择器:
-
ipBlock: 会选择特定的 IP CIDR 范围以允许作为入口源。通常这是集群外部 IP,因为 Pod IP 是临时的。
-
podSelector: 会在与 NetworkPolicy 相同的命名空间中选择特定的 Pod,这些 Pod 应该被允许作为入口源或出口目的地。
-
namespaceSelector: 会选择特定的命名空间,所有 Pod 都应该被允许作为入口源或出口目的地。
-
namespaceSelector** 和 podSelector**: 指定 namespaceSelector 和 podSelector 的单个 from 条目选择特定命名空间内的特定 Pod。
使用 NetworkPolicy 配置多租户隔离
现在让我们使用 NetworkPolicy 来配置隔离。
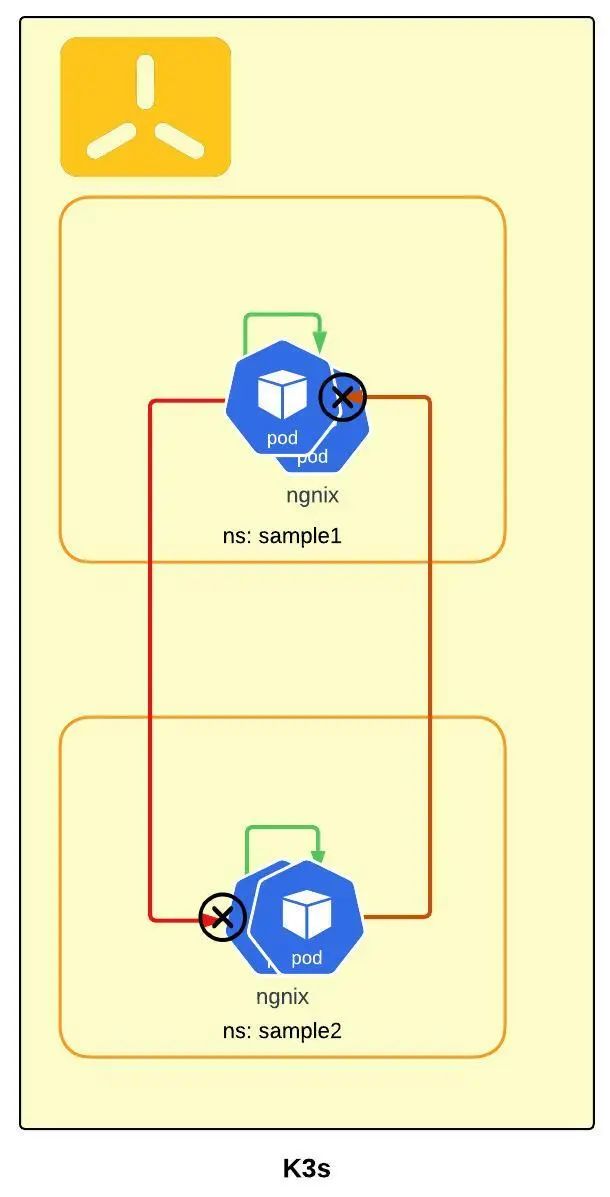
下面的 yaml 将在不同命名空间的服务之间建立隔离,只允许同一命名空间的 Pod 相互通信,同时也允许从 ingress 和监控 Pod 传入通信:
networkPolicy.yaml
# 阻止所有传入流量
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: deny-by-default
spec:
podSelector: {}
ingress: []
---
# 允许所有 Pod 在同一命名空间内的所有流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-same-namespace
spec:
podSelector: {}
ingress:
- from:
- podSelector: {}
---
# 允许 ingress Pod “traefik” 与该命名空间中的所有 Pod 通信
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-svclbtraefik-ingress
spec:
podSelector:
matchLabels:
svccontroller.k3s.cattle.io/svcname: traefik
ingress:
- {}
policyTypes:
- Ingress
---
# 允许 ingress Pod “traefik” 与该命名空间中的所有 Pod 通信
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-traefik-v121-ingress
spec:
podSelector:
matchLabels:
app.kubernetes.io/name: traefik
ingress:
- {}
policyTypes:
- Ingress
---
# 允许监控系统 Pod 与该命名空间中的所有 Pod 通信(以允许抓取指标)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-cattle-monitoring-system
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: cattle-monitoring-system
podSelector: {}
policyTypes:
- Ingress
现在将策略应用于两个示例命名空间中:
kubectl apply -f networkPolicy.yaml -n sample1
kubectl apply -f networkPolicy.yaml -n sample2
应用上述 networkPolicy.yaml 后,你需要设置好 ingress Pod 或 监控 Pod 的白名单。
现在让我们再次尝试之前的 curl 来检查 Pod 之间的通信:
# 从 sample1 访问 sample2
kubectl exec -n sample1 $(kubectl get po -n sample1 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample2.svc.cluster.local
# 从 sample1 访问 sample1
kubectl exec -n sample1 $(kubectl get po -n sample1 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample1.svc.cluster.local:80
# 从 sample2 访问 sample1
kubectl exec -n sample2 $(kubectl get po -n sample2 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample1.svc.cluster.local:80
# 从 sample2 访问 sample2
kubectl exec -n sample2 $(kubectl get po -n sample2 -l app=nginx -o name) -- curl --max-time 2 http://ngnix-service.sample2.svc.cluster.local:80
现在你应该看到,不同命名空间之间的通信被阻止了,但同一命名空间内是可以正常通信的。
调试 NetworkPolicy 通信
NetworkPolicy 能够看到由于匹配的 NetworkPolicy 而丢弃的数据包。由于网络规则是通过 KUBE-BWPLCY 链中的 iptables 部署的,我们可以在当前运行 Pod 的节点上看到这些规则。因此,让我们检查生成的 iptables。
首先,我们需要检查 Pod 是在哪个节点上运行。
kubectl get po -o wide -n sample1
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sample1 nginx-6c8b449b8f-hhwhv 1/1 Running 0 3d6h 192.168.248.2 node2
登录到 node2,并获取 iptables 的 KUBE-NWPLCY 链:
node2# iptables -L | grep KUBE-NWPLCY -B 2
iptables -L | grep KUBE-NWPLCY -B 2
target prot opt source destination
Chain KUBE-NWPLCY-6MLFY7WSIVQ6X74S (1 references)
target prot opt source destination
Chain KUBE-NWPLCY-6ZMDCAWFW6IG7Y65 (0 references)
--
RETURN all -- anywhere anywhere /* rule to ACCEPT traffic from all sources to dest pods selected by policy name: allow-all-svclbtraefik-ingress namespace sample1 */ match-set KUBE-DST-AZLS65URBWHIM4LV dst mark match 0x10000/0x10000
Chain KUBE-NWPLCY-CMW66LXPRKANGCCT (1 references)
--
RETURN all -- anywhere anywhere /* rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: allow-from-cattle-monitoring-system namespace sample1 */ match-set KUBE-SRC-RCIDLRVZOORE5IEC src match-set KUBE-DST-T5UTRUNREWDWGD44 dst mark match 0x10000/0x10000
Chain KUBE-NWPLCY-DEFAULT (2 references)
--
MARK all -- anywhere anywhere /* rule to mark traffic matching a network policy */ MARK or 0x10000
Chain KUBE-NWPLCY-EM64V3NXOUG2TAJZ (1 references)
--
RETURN all -- anywhere anywhere /* rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: allow-same-namespace namespace sample1 */ match-set KUBE-SRC-DSEC5V52VOYVVZ4H src match-set KUBE-DST-5TPLTTXGTPDHQ2AH dst mark match 0x10000/0x10000
Chain KUBE-NWPLCY-IF5LSB2QJ2HY5MD6 (0 references)
--
...
省略...
...
--
ACCEPT all -- anywhere anywhere /* rule for stateful firewall for pod */ ctstate RELATED,ESTABLISHED
ACCEPT all -- anywhere 192.168.248.2 /* rule to permit the traffic traffic to pods when source is the pod's local node */ ADDRTYPE match src-type LOCAL
KUBE-NWPLCY-DEFAULT all -- 192.168.248.2 anywhere /* run through default egress network policy chain */
KUBE-NWPLCY-CMW66LXPRKANGCCT all -- anywhere 192.168.248.2 /* run through nw policy allow-from-cattle-monitoring-system */
KUBE-NWPLCY-EM64V3NXOUG2TAJZ all -- anywhere 192.168.248.2 /* run through nw policy allow-same-namespace */
KUBE-NWPLCY-RJITOIYNFGLSMNHT all -- anywhere 192.168.248.2 /* run through nw policy deny-by-default */
现在我们观察链 KUBE-NWPLCY-EM64V3NXOUG2TAJZ(在你的环境中会有不同的名称),它是 allow-same-namespace namespace sample1,同时再次运行 curl 测试:
watch -n 2 -d iptables -L KUBE-NWPLCY-EM64V3NXOUG2TAJZ -nv
Every 2.0s: iptables -L KUBE-NWPLCY-EM64V3NXOUG2TAJZ -nv node2: Mon Mar 6 20:18:38 2023
Chain KUBE-NWPLCY-EM64V3NXOUG2TAJZ (1 references)
pkts bytes target prot opt in out source destination
4 240 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* rule to ACCEPT traffic from source pods to dest pods selected by policy name allow-same-namespace namespace sample1 */
match-set KUBE-SRC-OPGXQ4TCHJJUUOWB src match-set KUBE-DST-5TPLTTXGTPDHQ2AH dst MARK or 0x10000
4 240 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 /* rule to ACCEPT traffic from source pods to dest pods selected by policy name allow-same-namespace namespace sample1 */
match-set KUBE-SRC-OPGXQ4TCHJJUUOWB src match-set KUBE-DST-5TPLTTXGTPDHQ2AH dst mark match 0x10000/0x10000
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: allow-same-namespace namespace sample1 */ match-set KUBE-SRC-DSEC5V52VOYVVZ4H src match-set KUBE-DST-5TPLTTXGTPDHQ2AH dst MARK or 0x10000
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 /* rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: allow-same-namespace namespace sample1 */ match-set KUBE-SRC-DSEC5V52VOYVVZ4H src match-set KUBE-DST-5TPLTTXGTPDHQ2AH dst mark match 0x10000/0x10000
你会看到在运行 curl 测试期间,计数器不断变化,显示已接受和已丢弃的数据包。
被网络策略丢弃的数据包也可以被记录下来。被丢弃的数据包被发送到 iptables NFLOG,它显示了数据包的详细信息,包括阻止它的网络策略。
要将 NFLOG 转换为日志条目,可以安装 ulogd2/ulogd 包并将 [log1] 配置为在 group=100 上读取。然后,重新启动 ulogd2 服务提交新配置。
要将所有这些数据包记录到文件中,ulogd2 需要在 /etc/ulogd.conf 中进行配置,示例如下:
[global]
logfile="syslog"
loglevel=3
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_inppkt_NFLOG.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_filter_IFINDEX.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_filter_IP2STR.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_filter_IP2BIN.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_filter_PRINTPKT.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_filter_HWHDR.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_raw2packet_BASE.so"
plugin="/usr/lib/x86_64-linux-gnu/ulogd/ulogd_output_LOGEMU.so"
# 这是一个堆栈,用于记录系统通过 LOGEMU 发送的数据包
stack=log1:NFLOG,base1:BASE,ifi1:IFINDEX,ip2str1:IP2STR,print1:PRINTPKT,emu1:LOGEMU
[log1]
group=100
[emu1]
file="/var/log/ulog/syslogemu.log"
sync=1
修改配置文件后,重启 ulogd:
systemctl restart ulogd2.service
如果数据包被网络策略规则阻止,日志消息将出现在 /var/log/ulog/syslogemu.log 中:
# cat /var/log/ulog/syslogemu.log
Mar 7 09:35:43 cluster-k3s-masters-a3620efa-5qgpt IN=cni0 OUT=cni0 MAC=da:f6:6e:6e:f9:ce:ae:66:8d:d5:f8:d1:08:00 SRC=10.42.0.59 DST=10.42.0.60 LEN=60 TOS=00 PREC=0x00 TTL=64 ID=50378 DF PROTO=TCP SPT=47750 DPT=80 SEQ=3773744693 ACK=0 WINDOW=62377 SYN URGP=0 MARK=20000
如果有大量的流量,日志文件可能增长得非常快。为了控制这种情况,通过在相关的网络策略中添加以下注释,适当地设置 "limit "和 "limit-burst "iptables 参数:
# 默认值是limit=10/分钟和limit-burst=10。
kube-router.io/netpol-nflog-limit=
kube-router.io.io/netpol-nflog-limit-burst=
参考:
- Kubernetes Network Policies:https://kubernetes.io/docs/concepts/services-networking/network-policies
- K3s:https://github.com/k3s-io/k3s/blob/master/README.md
- 强化指南 – NetworkPolicies:https://docs.k3s.io/security/hardening-guide#networkpolicies
- K3s Network Policy:https://docs.k3s.io/advanced#additional-network-policy-logging