Oracle使用纪要
一、序列的创建与使用
1、基础
1)序列(SEQUENCE)是序列号生成器,可以为表中的行自动生成序列号,产生一组等间隔的数值(类型为数字)。不占用磁盘空间,占用内存。
其主要用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。
(mysql有自增主键,oracle没有、就用序列)
2)查询当前账号下,所有序列
select * from user_sequences
2、创建
创建序列需要CREATE SEQUENCE系统权限。序列的创建语法如下:
CREATE SEQUENCE 序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE/ MINVALUE n| NOMAXVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
其中:
-
INCREMENT BY用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表Oracle序列的值是按照此步长递减的。
-
START WITH 定义序列的初始值(即产生的第一个值),默认为1。
-
MAXVALUE 定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义,这时对于递增Oracle序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
-
MINVALUE定义序列生成器能产生的最小值。选项NOMAXVALUE是默认选项,代表没有最小值定义,这时对于递减序列,系统能够产生的最小值是?10的26次方;对于递增序列,最小值是1。
-
CYCLE和NOCYCLE 表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。如果不循环,达到限制值后,继续产生新值就会发生错误。
-
CACHE(缓冲)定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
大量语句发生请求,申请序列时,为了避免序列在运用层实现序列而引起的性能瓶颈。Oracle序列允许将序列提前生成 cache x个先存入内存,在发生大量申请序列语句时,可直接到运行最快的内存中去得到序列。但cache个数也不能设置太大,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最大的序列号+1 开始存入cache x个。这种情况也能会在数据库关闭时也会导致序号不连续。
-
NEXTVAL 返回序列中下一个有效的值,任何用户都可以引用。
-
CURRVAL 中存放序列的当前值,NEXTVAL 应在 CURRVAL 之前指定 ,二者应同时有效。
创建序列示例:
/*菌毒种样本资源表*/
CREATE SEQUENCE SEQ_mic_Sample_Resource
INCREMENT BY 1
START WITH 1
MINVALUE 0
NOCYCLE
CACHE 20
创建一个序列,从1开始,步长为1,最小值为0;不循环,每次缓存20个。其他采取默认值。
上述序列创建后,用plSQL导出(即包含默认值的)
create sequence SEQ_MIC_SAMPLE_RESOURCE
increment by 1
minvalue 0
maxvalue 9999999999999999999999999999
start with 1
cache 20;
创建序列用上面的两个模板之一就可以了
3、使用
1)序列创建后,可以使用序列的NEXTVAL来获取序列的下一个值,使用CURRVAL来查看当前值。第一次使用必须先使用NEXTVAL来产生一个值后才可以使用CURRVAL进行查看。
//序列调用 产生一个新的序列
select seq_test.nextval from dual
//查看当前序列的值
select seq_test.currval from dual
如果第一次直接使用CURRVAL来访问序列,就会报错。
2)在实际开发中的应用
<insert id="saveMicMicrobeRecord" >
<selectKey resultType="java.lang.Long" order="BEFORE" keyProperty="id">
SELECT SEQ_MIC_MICROBE_RECORD.nextval as ID from DUAL
</selectKey>
insert into MIC_MICROBE_RECORD
("ID", MICROBE_NAME, DANGER_DEGREE, "USAGE", TURNOVER)
values
(#{id}, #{microbeName}, #{dangerDegree}, #{usage}, #{turnover})
</insert>
使用这样的方式,新插入的数据、会同时返回id;即在同一方法中做另一条插入时,就可使用刚才插入的id作为外键,mysql中也有类似的功能。
3)在mybatis的xml文件中,获取序列的两种方式
# 方式一:示例如下
<selectKey resultType="java.lang.Long" order="BEFORE" keyProperty="id">
SELECT SEQ_MIC_MICROBE_RECORD.nextval as ID from DUAL
</selectKey>
insert into MIC_MICROBE_RECORD ("ID", CREATE_TIME)
values (#{id}, sysdate)
# 方式二:直接用 序列名.NEXTVAL
insert into JC_WECOM_TAG (ID, CREATE_TIME)
values (SEQ_JC_WECOM_TAG.NEXTVAL, SYSTIMESTAMP);
二、视图的创建与使用
1、基本概念
视图(View)实际上是一张或者多张表上的预定义查询;删除视图不会影响基表的数据。
视图本质上,就是给一段select语句起了个别名,通过查询别名,来调用这段select语句;它是不占用空间的,数据来自基表。
视图具有以下优点:
可以限制用户只能通过视图检索数据。这样就可以对最终用户屏蔽建表时底层的基表。
可以将复杂的查询保存为视图。
可以对最终用户屏蔽一定的复杂性。
限制某个视图只能访问基表中的部分列或者部分行的特定数据,这样可以实现一定的安全性。
从多张基表中按一定的业务逻辑抽出用户关心的部分,形成一张虚拟表。
2、创建语法
CREATE [OR REPLACE] [{FORCE|NOFORCE}] VIEW view_name
AS
SELECT查询
[WITH READ ONLY CONSTRAINT]
语法解析:
OR REPLACE:如果视图已经存在,则替换旧视图。
FORCE:即使基表不存在,也可以创建该视图,但是该视图不能正常使用,当基表创建成功后,视图才能正常使用。
NOFORCE:如果基表不存在,无法创建视图,该项是默认选项。
WITH READ ONLY:默认可以通过视图对基表执行增删改操作,但是有很多在基表上的限制(比如:基表中某列不能为空,但是该列没有出现在视图中,则不能通过视图执行insert操作),WITH READ ONLY说明视图是只读视图,不能通过该视图进行增删改操作。现实开发中,基本上不通过视图对表中的数据进行增删改操作。
3、案例及其应用背景
eg1、背景:bi大屏展示我们系统的数据,他们数据库表的数据、都是从我们库中的多个表进行查询。一开始都是隔一段时间,他们来找我们更新一次数据,这样做bi数据不是最新的、而且每次都要找一个人给他们查数据很麻烦。
后来我们按照他们数据库的表,建立了视图,视图命名为“V-表名”;这样bi连接我们数据库,查询相应视图,由于命名规则只需要他们在前边加个V-,所以他们也很熟悉,整个功能对接非常简单。
1)下图是他们需要的表
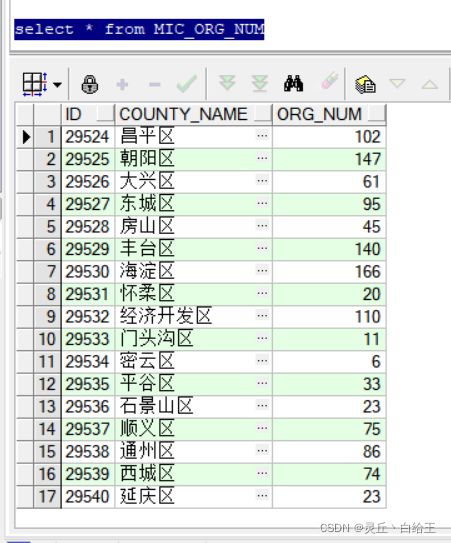
2)在我们数据库建立视图
CREATE OR REPLACE VIEW V_MIC_ORG_NUM
AS
SELECT d.dic_name as county_name, t.org_num
FROM
(SELECT o.area_id, count(distinct o.area_id || o.org_name) as org_num from MIC_ORG_INFO_COPY o
LEFT JOIN JC_SYS_USER u on u.id=o.user_id
WHERE
o.type=1
and u.is_cancel=0
and o.user_id IN (select distinct r.user_id from mic_record r where r.verify_status = 2)
GROUP BY o.area_id) t
LEFT JOIN JC_DICTIONARY_VALUE d on t.area_id=d.dic_code
where d.dic_level='2' and d.dic_category_code='SRP_AREA'
WITH READ ONLY
3)从新建视图V_MIC_ORG_NUM 查出的数据和他们的表结构一样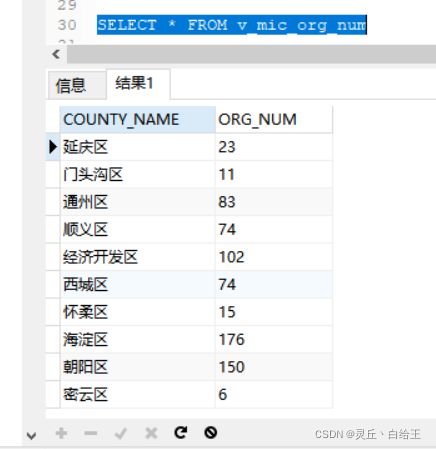
三、在SQL语句中对时间操作、运算
0、date与timestamp
1)区别
date精确到年月日时分秒,timestamp更精确一些;
但这个不重要,重要的是,实践中我从Oracle数据库取date类型字段,前端展示时分秒都是0,网上说数据库类型是date取到前端就是这样,只能精确到日,后面都是默认填0;
我给字段换成timestamp确实问题解决了,我理解不了!
2)转换
timeStamp --> date
TO_DATE(to_char(xxxTimestamp, 'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
date -->timeStamp
TO_TIMESTAMP(to_char(xxxDate, 'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
1、获取系统当前时间
date类型的:
sysdate
timestamp类型的:
SYSTIMESTAMP
char类型的:
to_char(sysdate, ‘yyyy-mm-dd hh24:mi:ss’)
2、ORACLE里获取一个时间的年、季、月、周、日的函数:
select to_char(sysdate, ‘yyyy’ ) from dual; --年
select to_char(sysdate, ‘MM’ ) from dual; --月
select to_char(sysdate, ‘dd’ ) from dual; --日
select to_char(sysdate, ‘Q’) from dual; --季
select to_char(sysdate, ‘iw’) from dual; --周–按日历上的那种,每年有52或者53周
3、日期操作
当前时间减去7分钟的时间
select sysdate - interval ‘7’ MINUTE from dual;
当前时间减去7小时的时间
select sysdate - interval ‘7’ hour from dual;
当前时间减去7天的时间
select sysdate - interval ‘7’ day from dual;
当前时间减去7月的时间
select sysdate - interval ‘7’ month from dual;
当前时间减去7年的时间
select sysdate - interval ‘7’ year from dual;
时间间隔乘以一个数字
select sysdate - 8*interval ‘7’ hour from dual;
4、常用的时间戳
//获取当年的一月一号
to_date(concat((select to_char(sysdate,‘yyyy’) from dual), ‘-01-01 00:00:00’),‘yyyy-MM-dd HH24:mi:ss’) //date格式
//获取这个月的一月一号
SELECT LAST_DAY(ADD_MONTHS(SYSDATE, -1)) + 1 FROM DUAL; //date格式
char格式
SELECT TO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, -1)) + 1,‘yyyy-mm-dd HH24:mi:ss’) FROM DUAL;
5、查询某时间范围
SELECT users.*
FROM users
WHERE create_time >= '2021-12-01 00:00:00'
AND create_time <= '2021-12-06 00:00:00'
或者
SELECT users.*
FROM users
WHERE create_time
BETWEEN '2021-12-01' AND '2021-12-07';
四、Oracle分页
1、分页适用场景
关于数据库查询,如果一次将所有查询结果返回返回,会有以下问题:
一是查询量较大时,查询时间会很长
二是前台的数据展示能力有限.
这时一般采用分页查询功能。
Mysql数据库:
- 使用Limit (page, size)关键字做分页查询
Oracle数据库:
- 因为Oracle中没有Limit关键字,所以使用rownum伪列做分页
2、分页方法
方法一:
# 查询11~20数据
select
a.* from ( select t.*,rownum from test t where rownum <= 20 ) a
where rownum >= 11;
方法二:
select
a.* from ( select t.*,rownum from test t ) a
where rownum >= 11 and rownum <= 20;
经过测试, 第一种方法性能更好,而且随着数量的增大,几乎不受影响。第二种随着数据量的增大,查询速度也越来越慢。
原因是,方法一先查20条,再取第11条后的结果;方法二是先查询全部数据,再取第11条到20条的结果。方法一中,返回结果集很少,再过滤;方法二,返回结果集很大,再进行过滤,明显方法一效率更高。
补充:有机会看一下mybatis分页,使用的是哪种分页策略。
五、常用查询语句、函数
1、case…when…
1)可以实现多个字段合并成一个字段的效果
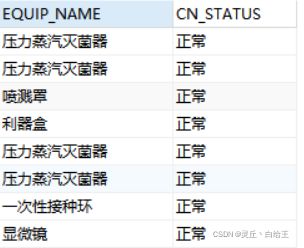
2)可以根据字段值不同,返回对应的字典值;比如查询设备表,根据设备状态status(0,1,2),返回(停用、正常、维修)
SELECT EQUIP_NAME,
case
when status=0 then '停用'
when status=1 then '正常'
when status=2 then '维修'
else '其他'
end cn_status
from MIC_LABORATORY_EQUIPMENT_COPY
效果如下
3)配合其他函数使用
例1:
SELECT lab_name,
case
when instr(lab_safe_level,'BSL-1')>0 then 'P1'
when instr(lab_safe_level,'BSL-2')>0 then 'P2'
when instr(lab_safe_level,'BSL-3')>0 then 'P3'
else '其他'
end SAFE_LEVEL
from mic_laboratory_copy
例2:
SELECT count(*) PERSON_AMOUNT,
sum(CASE WHEN PERSON_TYPE='HB_PERSONNEL_TYPE_001' THEN 1 ELSE 0 END) PERSON_TYPE_fz,
sum(CASE WHEN PERSON_TYPE='HB_PERSONNEL_TYPE_002' THEN 1 ELSE 0 END) PERSON_TYPE_js,
sum(CASE WHEN PERSON_TYPE='HB_PERSONNEL_TYPE_003' THEN 1 ELSE 0 END) PERSON_TYPE_bc,
sum(CASE WHEN PERSON_TYPE='HB_PERSONNEL_TYPE_004' THEN 1 ELSE 0 END) PERSON_TYPE_ab,
sum(CASE WHEN PERSON_TYPE='HB_PERSONNEL_TYPE_005' THEN 1 ELSE 0 END) PERSON_TYPE_qt
FROM MIC_LAB_PERSON_COPY
2、instr(字段, ‘截取字段’) > 0
该sql语法效果和 like ‘%’ 截取字段 ‘%’ 相同,但是查询效率更高,语法也更简洁
<select id="queryMyNotice" resultType="com.hys.spr.dto.SprNoticeReadDto">
select p.ID noticeId, p.TITLE, p.PUBLISHER, p.PUBLISHER_ID, p.CREATE_TIME sendTime,
u.ID nuId, u.READ_STATUS readStatus
from SPR_NOTICE p
left join SPR_NOTICE_USER u on u.NOTICE_ID=p.ID
<where>
u.USER_ID=#{readQueryDto.readerId} and p.NOTICE_STATUS='1'
<if test="readQueryDto.title!=null and readQueryDto.title!=''">
and instr(p.TITLE, #{readQueryDto.title})>0
</if>
</where>
</select>
3、把一个list结果,弄成一个字段
例如 查询一个班里的所有男生姓名,
select p.name from class_2 p where sex='man'
上述sql理论返回一个list,但是我们现在不想要list,而是想要一个字符串字段。
这时可用oracle 自带函数wm_concat() ,这是oracle 自带函数,如果超过4000会报错,超过4000就只能自己写函数了。
该方法是将记录的值使用逗号间隔拼接,如果想其它分隔符分割,可用replace
使用方法如下:
select wmsys.wm_concat(p.name) name from class_2 p where sex='man'
4、去重
1)distinct去重
#不去重
SELECT p.SEP_SOC_ID,p.SEP_CUSTOMER_NAME from SPR_USER p
LEFT JOIN SPR_USER_SUBJECT s on s.SEP_SOC_ID=p.SEP_SOC_ID
WHERE p.SEP_SYSTEM_ID='1527199036575698946' and s.SEP_YEAR_ID='2022'
and p.STATUS=1 and s.STATUS=1
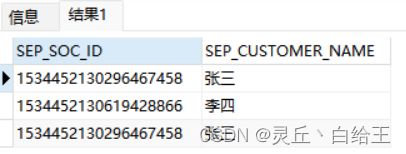
#去重
SELECT DISTINCT p.SEP_SOC_ID,p.SEP_CUSTOMER_NAME from SPR_USER p
LEFT JOIN SPR_USER_SUBJECT s on s.SEP_SOC_ID=p.SEP_SOC_ID
WHERE p.SEP_SYSTEM_ID='1527199036575698946' and s.SEP_YEAR_ID='2022'
and p.STATUS=1 and s.STATUS=1
2)distinct也可以用在单个字段
#写法一
SELECT DISTINCT(p.SEP_SOC_ID) from SPR_USER p
LEFT JOIN SPR_USER_SUBJECT s on s.SEP_SOC_ID=p.SEP_SOC_ID
WHERE p.SEP_SYSTEM_ID='1527199036575698946' and s.SEP_YEAR_ID='2022'
and p.STATUS=1 and s.STATUS=1
#写法二
SELECT DISTINCT p.SEP_SOC_ID from SPR_USER p
LEFT JOIN SPR_USER_SUBJECT s on s.SEP_SOC_ID=p.SEP_SOC_ID
WHERE p.SEP_SYSTEM_ID='1527199036575698946' and s.SEP_YEAR_ID='2022'
and p.STATUS=1 and s.STATUS=1
5、trim()删除空值
delete from 表 where trim(字段);
六、使用mybatis/mybatis-plus实现批量新增、更新(适用于Oracle数据库)
0、前言
oracle不同于mysql,不能用批量新增/更新sql,所以它实现“批量”新增/更新的方式,就是有多少条数据、就写多少条新增/更新语句,把他们用;隔开,然后一起执行。
和单条执行的效率是一样的,但是只需要用一次数据库连接。
1、批量新增
1)DAO接口
int saveByJson(@Param("pam") List<WecomTagVo> params);
2)xml文件
<insert id="saveByJson">
begin
<foreach collection="pam" item="tag">
insert into JC_WECOM_TAG
(
ID, TAG_ID, TAG_NAME, TAG_GROUP_ID, TAG_GROUP_NAME, CREATE_TIME
)
values(
SEQ_JC_WECOM_TAG.NEXTVAL,
#{tag.tag_id},
#{tag.tag_name},
#{tag.tag_group_id},
#{tag.tag_group_name},
SYSTIMESTAMP
);
</foreach>
end;
</insert>
3)有3个小细节需要注意:
第一,begin…end;不能省略,否则会执行失败。
第二,用来分割每个新增sql的;号,只能加在sql中的后面,不能用separator=";"属性来设置。
因为
第三,end后的;号不能省略,省略会无法执行。
2、批量更新
1)DAO接口
int updateByJson(@Param("pam") List<WecomTagVo> params);
2)xml文件
<update id="updateByJson">
begin
<foreach collection="pam" item="tag">
update JC_WECOM_TAG set
TAG_NAME = #{tag.tag_name},
TAG_GROUP_ID = #{tag.tag_group_id},
TAG_GROUP_NAME = #{tag.tag_group_name},
UPDATE_TIME = SYSTIMESTAMP
where TAG_ID = #{tag.tag_id};
</foreach>
end;
</update>
3)更新也要注意上述3个小细节,为了强调其重要性,这里重复写一遍:
第一,begin…end;不能省略,否则会执行失败。
第二,用来分割每个更新sql的;号,只能加在sql中的后面,不能用separator=";"属性来设置。
因为
第三,end后的;号不能省略,省略会无法执行。
七、常见问题记录
1、Mybatis-XML文件的sql(用Oracle),不能以分号;结尾
以分号结尾就会报"java.sql.SQLException: ORA-00911: 无效字符"

针对mysql来说,在mybatis的xml文件中两种形式都是支持的。
而对于Oracle,加分号的写法会报“ora-00911: 无效字符”的异常。
网上说是因为 “Oracle数据库接口对书写格式要求非常严格,有时候即使多加一个空格,多加一个逗号,分号,回车等都不行”。
注意,我个人实测,(用Oracle)一般单句sql都不能加分号,但是如果用begin…end;语法,中间的sql结尾加分号就没有问题。