局域网内网穿透技术
文章目录
- 一、内网穿透概述
-
- 1、传统内网穿透介绍
- 2、ZeroTier和Tailscale
- 二、ZeroTier
-
- 1、概述
-
- 1.1 介绍
- 1.2 相关概念
- 2、ZeroTier简单使用
- 3、Moon搭建
-
- 3.1 介绍
- 3.2 部署Moon服务
- 3.3 使用 Moon 服务
- 4、流量转发与局域网访问
-
- 4.1 概述
- 4.2 转发服务器配置
- 4.3 客户端配置
- 三、Tailscale
-
- 1、概述
-
- 1.1 Tailscale简介
- 1.2 优势
- 1.3 Headscale 是什么
- 2、基本使用
-
- 2.1 节点互相访问
- 2.2 访问局域网设备
- 2.3 出口流量转发
- 3、Headscale 部署
-
- 3.1 服务端部署
- 3.2 Tailscale客户端接入
- 3.3 通过 Pre-Authkeys 接入
- 3.4 局域网互通
- 3.5 常用命令总结
- 4、中继服务器概述(可选)
-
- 4.1 STUN 是什么
- 4.2 中继服务之TURN
- 4.3 DERP
- 5、自建私有 DERP server(可选)
-
- 5.1 概述
- 5.2 中继服务器搭建
- 5.3 配置 Headscale
- 5.4 客户端网络调试
- 5.5 Docker Compose 安装(可选)
一、内网穿透概述
1、传统内网穿透介绍
传统内网穿透的方式为:内网设备<——>中转服务器<———>网络设备(手机、电脑),例如frp,nps,可以参考:内网穿透工具;但是这种方法弊端也很明显
- 中转服务器需要一定的费用进行支撑(带公网的云服务器),如果是外网的服务器还可能存在被墙的风险
- 中转服务器直接决定了中转的"速度",而这个"速度"越快其对应的服务器带宽就越大,通常来说价格就越高
- 需要一定的知识储备来搭建内网穿透的服务端,而且只能转发某个特定的端口
2、ZeroTier和Tailscale
关于打洞的知识可以参考:NAT网络与内网穿透详解
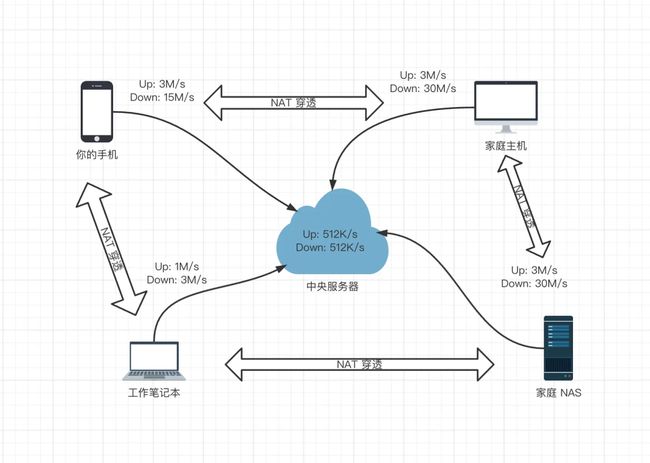
一般来说会优先进行打洞,打洞的时候连接:内网设备<——>移动、PC设备(手机、电脑),通常情况下是端到端的传输,如果网络环境差或者无法打洞也会借助中转服务器进行传输数据(自带的中间服务器在国外,最好自己部署一个自己的)。
加入到一个局域网后,能够穿透转发所有端口,正常情况下不依赖服务器进行中转传输文件,端到端连接,理论可以达到满带宽,同时也可以进行流量转发,实现一台机器加入网络,实现整个局域网的设备访问
二、ZeroTier
官网地址:https://www.zerotier.com/
1、概述
1.1 介绍
zerotier采用VLAN(虚拟局域网)技术将不同设备连接到一个“虚拟的局域网”中,从而让这些设备随时随地都可以互相访问,相比于frp等其他内网穿透来说,组建虚拟局域网更安全更便捷,每台服务器上只需要安装对应的客户端,连接到同一个网络,就可以实现 IP 互相访问。在此之上,还有自定义 DNS 服务器的功能,将通过 IP 这个步骤转换为通过域名进行访问,相当实用,甚至可以在局域网的一台主机搭建,实现整个局域网的访问
ZeroTier所有的设备都是客户端,连接方式是点对点。在路由器下面的话是用 uPnP 的方式进行转发实现客户端到客户端的直接连接。如果 uPnP 没有开启,会通过传统的服务器转发的方式进行连接。
1.2 相关概念
- Earth。根据其介绍,将地球上的所有设备连起来。那这里的 Earth 指的就是整体的一个服务
- Network。每一个 Network 包含的所有设备都在同一个网络里。每个网络有一个 Network ID。各客户端通过这个 ID 连接到此网络。当然,一个账号是可以创建多个网络的。网络氛围 Public 和Private。一般我们自己组网是要用 Private,需要在页面授权设备才可以进行访问。
- Planet。官方提供的服务器节点。各客户端都是通过这些服务来互相寻址的。相当于 zookeeper 的不同节点
- Moon。自定义的 Planet。由于 Zerotier 没有国内节点,在两个设备刚开始互连的时候有可能需要通过国外的节点寻址(不过我没发现有什么慢的)导致创建连接的速度偏慢。在自己的网络里搭建 Moon 可以使连接提速。
- Leaf。客户端。就是连接到网络上的每一个设备。其实经过测试,Moon 也是客户端的一种。这里特指没有额外功能,单纯用于连接的客户端
2、ZeroTier简单使用
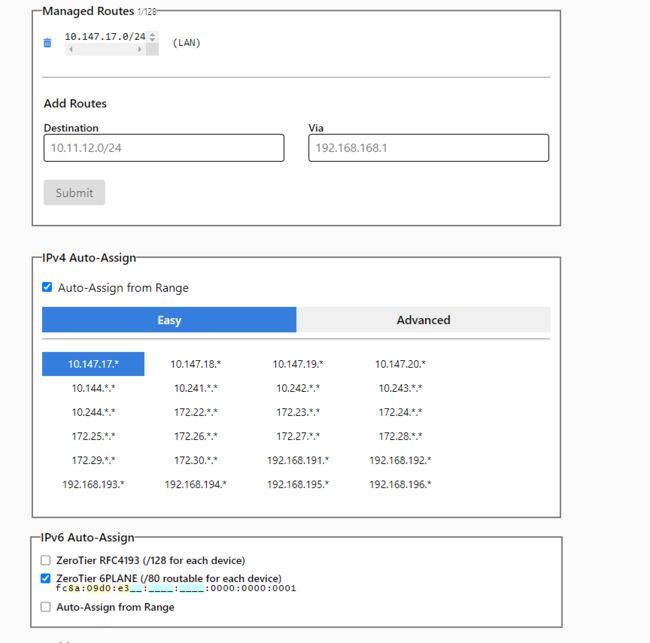
首先登陆官网进行账号注册:https://www.zerotier.com/,完成后点击创建好的网络,进入设置界面进行设置,创建网络,记住NETWORK ID,进入后选择PRIVATE网络(public加入不需要授权,不安全),之后选择自己想要的网段,其他保持默认即可
然后根据不同平台下载客户端:zerotier.com/download/,举例linux
curl -s https://install.zerotier.com | sudo bash
# 安装完成后可以使用 systemctl 命令来控制服务
sudo systemctl enable zerotier-one.service
sudo systemctl start zerotier-one.service
# 查看节点列表
sudo zerotier-cli listpeers
# 查看安装的zerotier版本
sudo zerotier-cli status
# 加入一个network
sudo zerotier-cli join 17d7094***********(填写自己的 networkid)
# 退出一个network
sudo zerotier-cli leave 17d709************(填写自己的 networkid)
# 查看监听的列表
sudo zerotier-cli peers
sudo zerotier-cli listpeers
# 列出加入的网络信息
sudo zerotier-cli listnetworks
# 卸载已安装版本
# Debian/Ubuntu 发行版卸载方法
sudo dpkg -P zerotier-one
sudo rm -rf /var/lib/zerotier-one/
# Redhat/CentOS 发行版卸载方法
sudo rpm -e zerotier-one
sudo rm -rf /var/lib/zerotier-one/
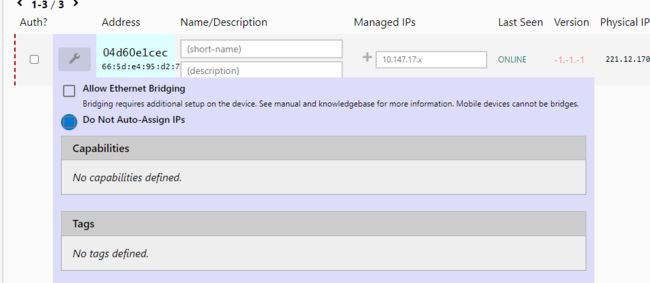
开始授权,可以选择设置按钮自行设置设备的ip,默认就是系统随机分配
windows类似,加入网络授权后,即可访问加入这个局域网中的所有设备了
3、Moon搭建
3.1 介绍
官方手册部署 Moon
Moon 节点可以是具有固定 IP 的公网设备,也可以是具有物理 IP 的内网设备. 如果使用内网设备,依然需要借助官方根服务器作为中间链路. 因此,这里我们在云服务器上搭建 Moon 服务,在机器 C 上部署 ZeroTier Moon 首先需要安装 ZeroTier One 将其部署为为 ZeroTier Node(参考前一节);当然如果打洞不成功也需要走moon流量
3.2 部署Moon服务
# 进入 root 账户
sudo su
# 进入 ZeroTier HOME 目录
cd /var/lib/zerotier-one/
# 获取 moon.json 文件
zerotier-idtool initmoon identity.public >>moon.json
# 在 moon.json 文件中添加公网 IP(s)
# moon.json 文件中的 "id": "deadbeef00" 就是公网机器 的 ZeroTier Node ID
# 修改 “stableEndpoints” 为机器 的公网的 ip,然后注意端口的开放,这里多个ip也可以填写,包括ipv6
{
"id": "7818fa6036",
"objtype": "world",
"roots": [
{
"identity": "7818fa6036:0:90a5291289a5b9f469230c138e6d34811a40df7aa2398099ad9a3e3d453c6f7f7cb1ea7cce745dd2f3005348364f7622e240ab400832cc724dc42549e4309106",
"stableEndpoints": ["1.2.3.4/9993"]
}
],
"signingKey": "9d081af8144cf01201f491484f8c3cbcd9669fe4d549c790a13eb14924417167a6d94f5b32516e78c47b1a3c0362454d297c17e5f0b5bb42b903600838349b6a",
"signingKey_SECRET": "ab9634fe2146564bf7a049b9eee41e1b9e092a19a5f743e39360f4130840c83a87aecca1f9f5dd39df08ac8a2af1b68fef7cb7f56f002f66f00bf4d02eecbbd4",
"updatesMustBeSignedBy": "9d081af8144cf01201f491484f8c3cbcd9669fe4d549c790a13eb14924417167a6d94f5b32516e78c47b1a3c0362454d297c17e5f0b5bb42b903600838349b6a",
"worldType": "moon"
}
# 7818fa6036就是机器的 ZeroTier Node ID
# 然后设置 0000007818fa6036.moon 签名文件
# 修改完 moon.json 文件后,获取 000000deadbeef00.moon 签名文件
zerotier-idtool genmoon moon.json
# 此时,在 /var/lib/zerotier-one/ 下产生 0000007818fa6036.moon 文件就是机器的 ZeroTier Node ID.
# 新建 moons.d 目录,并将 000000deadbeef00.moon 文件移动到其下:
mkdir moons.d
mv 0000007818fa6036.moon moons.d
# 重启 ZeroTier One 服务,激活设置
service zerotier-one restart
# 查看moon
sudo zerotier-cli listmoons
3.3 使用 Moon 服务
要想使用 Moon 服务,还需要在机器上添加签名文件,有两种方式:手动添加;命令行通过 ZeroTier Root Server 添加,添加后会发现延迟显著降低
手动添加签名文件
# 在 ZeroTier One 的 HOME 目录新建 moons.d 目录, 将 1.3 小节中产生的 0000007818fa6036.moon 拷贝出来并放入 {ZeroTier_One_HOME}\moons.d 目录中
# 以下是各种操作系统中 ZeroTier One 默认的 HOME 目录:
Linux: /var/lib/zerotier-one
FreeBSD / OpenBSD: /var/db/zerotier-one
Mac: /Library/Application Support/ZeroTier/One
Windows: C:\Program Files (x86)\ZeroTier\One
#----------------------------------windows
# 在 \ProgramData\ZeroTier\One 下建立 moons.d 目录,并将 0000007818fa6036.moon 拷贝放入
# 然后重启 ZeroTier One 服务.win + R 打开运行,输入 services.msc 打开服务,选择 ZeroTier One 服务并重新启动
# 测试,在 \Program Files (x86)\ZeroTier\One 下打开 cmd,测试 MOON 节点是否添加成功
# 如果出现你的公网ip就代表成功
zerotier-cli.bat listpeers
#----------------------------------linux
# Ubuntu 操作系统中 ZeroTier One HOME 目录为 /var/lib/zerotier-one,建立 moons.d 目录,并将 000000deadbeef00.moon 拷贝放入
# 重新启动 ZeroTier One 服务
sudo service zerotier-one restart
# 测试,出现 MOON 标识的节点标识添加成功
sudo zerotier-cli listpeers
命令添加
# windows下,填写自己的node id,然后重启
C:\Program Files (x86)\ZeroTier\One>zerotier-cli.bat orbit 7818fa6036 7818fa6036 # deadbeef00 twice
# Ubuntu 下
sudo zerotier-cli orbit 7818fa6036 7818fa6036 # deadbeef00 twice
# 命令行实际上是通过 ZeroTier 根服务器将 0000007818fa6036.moon 拷贝放入 {ZeroTier_One_HOME}/moons.d 目录中. 由于网络原因,可能会有延迟或无效的情况,重复、等待或使用手动方式.
# 重启 ZeroTier One 服务是非常重要的步骤,不重启 ZeroTier One 服务将无法激活设置.
4、流量转发与局域网访问
4.1 概述
可以参考:zerotier转发客户端流量
那么如何让一台局域网外的电脑访问局域网内所有设备呢,但是又不想让所有设备都安装zerotier,这时,仅使用** Ubuntu 上的 linux 内核的数据转发和 iptables 控制路由**就能实现所需功能(相当于science上网的功能)
4.2 转发服务器配置
首先需要配置内网中一台 Linux 的数据转发和路由控制,Linux 系统内核可以通过 sysctl 和 iptables 两个命令控制网络数据转
# 查看内核 IP 转发设置,0 表示处于关闭状态
sudo sysctl net.ipv4.ip_forward
# 编辑配置文件开启 Linxu 内核的 IP 数据转发
sudo vim /etc/sysctl.conf
# 将第 28 行的注释去掉,设置 net.ipv4.ip_forward=1
net.ipv4.ip_forward=1 # lin 28
# 激活配置文件设置
sudo sysctl -p
# 查看内核 IP 转发设置,1 表示开启状态
sudo sysctl net.ipv4.ip_forward
# 查看网口信息,下面两个都可以,可以发现有两个网卡,一个真实的一个zerotier提供的
ifconfig
ip link show
# ----------------------使用iptables开启流量转发--------------
# 注意下列网卡都需要换成自己的网卡信息
# 使用 iptables 启用 enp123s0f0 的网络地址转换和 IP 伪装
sudo iptables -t nat -A POSTROUTING -o enp123s0f0 -j MASQUERADE
# 允许流量转发和跟踪活动连接
sudo iptables -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
# 接下来设置从zt7u3fcxwr 到 enp123s0f0 流量转发; 反向规则不是必需的,原理同理
sudo iptables -A FORWARD -i zt7u3fcxwr -o enp123s0f0 -j ACCEPT
# -----------------保存路由规则--------------------------------
# iptables 规则在重新启动后就无效了. 将上面设置保存为配置文件中,这里我是用的是ubuntu20,centos原理类似
# 安装 iptables 配置存储工具
sudo apt-get install iptables-persistent
# 保存 iptables 配置到文件
sudo netfilter-persistent save
# 查看 iptables 配置文件内容,配置文件保存路径在 /etc/iptables/ 目录下
sudo iptables-save
然后需要配置 ZeroTier 网络路由管理,打开控制台:https://my.zerotier.com/,增加 1 条路由,Destination 填入 0.0.0.0/0 表示全网,(via) 填入 zt7u3fcxwr 的 IP 地址,点击 Submit 提交。意思就是将流量通过via转发,相当于把Via当作网关,也可以自定义特定的网关
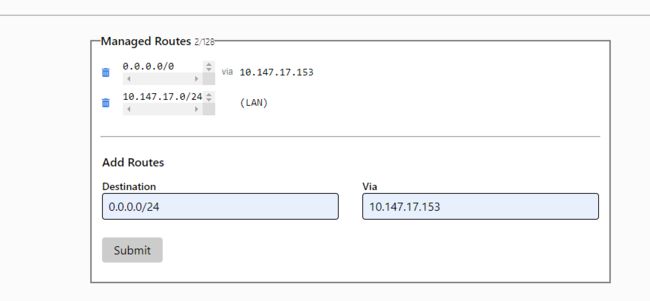
这里再举个例子
# 假设zerotier虚拟局域网的网段是192.168.88.0 局域网A 192.168.1.0 局域网B 192.168.2.0
# (如果需要互联)在局域网A和B中需要各有一台主机安装zerotier并作为两个内网互联的网关
# 分别是192.168.1.10(192.168.88.10) 192.168.2.10(192.168.88.20)#括号里面为虚拟局域网的IP地址
# 在zerotier网站的networks里面的Managed Routes下配置路由表
#如果单向连接,仅需填写下方一个即可.
192.168.1.0/24 via 192.168.88.10
192.168.2.0/24 via 192.168.88.20
# 开启内核转发
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p
# 防火墙设置
iptables -I FORWARD -i ztyqbub6jp -j ACCEPT
iptables -I FORWARD -o ztyqbub6jp -j ACCEPT
iptables -t nat -I POSTROUTING -o ztyqbub6jp -j MASQUERADE
#其中的 ztyqbub6jp 在不同的机器中不一样,你可以在路由器ssh环境中用 zerotier-cli listnetworks 或者 ifconfig 查询zt开头的网卡名
iptables-save #保存配置到文件,否则重启规则会丢失.
4.3 客户端配置
Windows 可以使用客户端,需要勾选 Allow Global IP.
- 开启转发代理:勾选
Allow Default Route - 关闭转发代理:取消
Allow Default Route
对于Linux来说,启用 ZeroTIer转发代理需要设置内核,使内核允许发送数据的地址和接受数据的地址不同. 默认情况下,当发送地址与接受地址不一致的时候,内核会丢弃接收的数据.
# 编辑 /etc/sysctl.conf 文件
sudo vim /etc/sysctl.conf
# 去掉第 20 行注释,并设置如下
net.ipv4.conf.all.rp_filter=2 # line 20
# 0:不开启源地址校验。
# 1:开启严格的反向路径校验。对每个进来的数据包,校验其反向路径是否是最佳路径。如果反向路径不是最佳路径,则直接丢弃该数据包。
# 2:开启松散的反向路径校验。对每个进来的数据包,校验其源地址是否可达,即反向路径是否能通(通过任意网口),如果反向路径不同,则直接丢弃该数据包
# 激活配置文件设置
sudo sysctl -p
# 注意下面的NetworkID 换成自己的局域网id
# 允许 ZeroTier One 转发全局流量
sudo zerotier-cli set NetworkID allowGlobal=1
# 开启转发代理
sudo zerotier-cli set NetworkID allowDefault=1
# 关闭转发代理
sudo zerotier-cli set NetworkID allowDefault=0
# 如果开启转代理后没有正常工作,可以尝试重启 ZeroTier One 服务或重启计算机.
sudo systemctl restart zerotier-one.service
最后进行测试,能ping通局域网表示成功,打开转发代理,访问curl http://myip.ipip.net/,如果显示的isp和局域网的一样,说明成功
三、Tailscale
1、概述
官网:https://tailscale.com/
1.1 Tailscale简介
Tailscale 是一种基于 WireGuard 的虚拟组网工具,和 Netmaker 类似,最大的区别在于 Tailscale 是在用户态实现了 WireGuard 协议,而 Netmaker 直接使用了内核态的 WireGuard。所以 Tailscale 相比于内核态 WireGuard 性能会有所损失,
Tailscale 就是一种利用 NAT 穿透(P2P 穿透)技术的 内网穿透工具.。Tailscale 客户端等是开源的, 不过遗憾的是中央控制服务器目前并不开源; Tailscale 目前也提供免费的额度给用户使用, 在 NAT 穿透成功的情况下也能保证满速运行。不过一旦无法 NAT 穿透需要做中转时, Tailscale 官方的服务器由于众所周知的原因,在国内访问速度很拉胯; 不过有一个开源版本的中央控制服务器(Headscale), 也就是说: 我们可以自己搭建中央服务器, 完全 “自主可控”
1.2 优势
- 开箱即用:无需配置防火墙;没有额外的配置
- 高安全性/私密性:自动密钥轮换;点对点连接;支持用户审查端到端的访问记录
- 在原有的 ICE、STUN 等 UDP 协议外,实现了 DERP TCP 协议来实现 NAT 穿透
- 基于公网的控制服务器下发 ACL 和配置,实现节点动态更新
- 通过第三方(如 Google) SSO 服务生成用户和私钥,实现身份认证
当然Tailscale 是一款商业产品,个人用户在接入设备不超过 20 台的情况下是可以免费使用的(虽然有一些限制,比如子网网段无法自定义,且无法设置多个子网)。除 Windows 和 macOS 的图形应用程序外,其他 Tailscale 客户端的组件(包含 Android 客户端)是在 BSD 许可下以开源项目的形式开发的,你可以在他们的 GitHub 仓库找到各个操作系统的客户端源码
1.3 Headscale 是什么
Tailscale 的控制服务器是不开源的,而且对免费用户有诸多限制。目前有一款开源的实现叫 Headscale,Headscale 由欧洲航天局的 Juan Font 使用 Go 语言开发,在 BSD 许可下发布,实现了 Tailscale 控制服务器的所有主要功能,可以部署在企业内部,没有任何设备数量的限制,且所有的网络流量都由自己控制。
2、基本使用
2.1 节点互相访问
对应软件安装教程:https://tailscale.com/download/linux
- 首先需要有个账号,使用自己已有的谷歌、Git或者微软账户登入系统
- 根据设备类型的不同,按照官方教程安装服务,注意,iOS需要有美区账户才能下载客户端
- 安装后,Linux执行
tailscale up,会提示登录鉴权的url,其他客户端的Login或者Auth会拉起登录链接到浏览器,登入你的账户即可将节点加入局域网 - 最后,在 Tailscale 后台管理 即可查看节点的IP,并通过IP访问你的节点
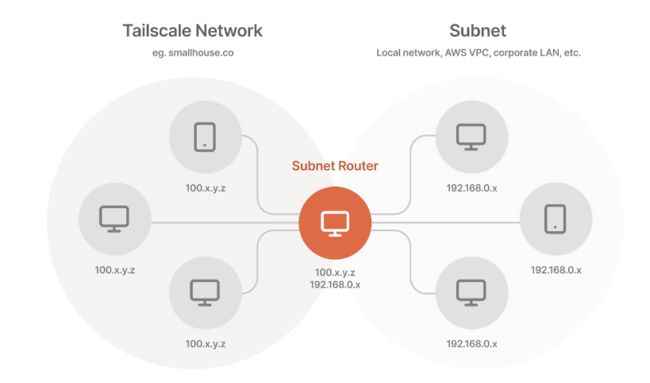
2.2 访问局域网设备
只要局域网一台设备安装了Tailscale即可访问所有设备,这里以ubuntu20作为转发机器,一般来说也都是linux作为转发,参考:https://tailscale.com/kb/1019/subnets/
# 常用操作可以参考:https://tailscale.com/kb/1080/cli/
# 首先进行服务端的配置
# 首先进行登陆,登录到局域网中
sudo tailscale up
# 查看分配到的IP地址
tailscale ip
# 要使Tailscale 网络内的装置可以互通,首先需要启用 Linux 上的 IP 转发(IP Forwarding)
# 因为「Subnet Route」的设定需要用到 IP 转发(IP Forwarding)特性
# 在 /etc/sysctl.conf中添加开启路由转发
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
# 或者
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.conf
# 不需要防火墙配置,会自动管理规则,以允许转发。设定过程也没涉及到iptable,一条指令可以完成
# 最后需要刷新一下
sudo sysctl -p /etc/sysctl.conf
# 启用IP转发功能时,请确保防火墙默认设置为禁止流量转发。这是ufw和firewall等常见防火墙的默认设置,可确保您的设备不会路由您不想路由的流量。
# 例如需要允许伪装
# firewall-cmd --permanent --add-masquerade
# --accept-routes=true接受其他节点发布的子网路由,Linux设备默认不接受路由
# --accept-dns=false表示从控制面板获取默认dns
# --advertise-routes表示暴露物理子网路由到您的整个Tailscale网络,替换为自己的网段,可以是IPV4或者IPV6,也可以多个网段
tailscale up --advertise-routes=192.168.31.0/24 --accept-routes=true --accept-dns=false
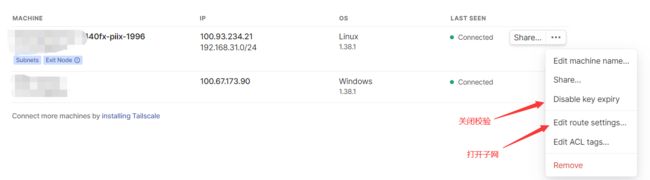
设置完后打开控制台,首先关闭key过期,不然六个月就需要重新校验了,然后可以看到子网是灰色的,这需要控制台进行同意才行,点击Edit route settings,打开对应的Subnet routes子网即可
然后进行客户端的配置,下载对应的客户端
# 首先加入对应局域网,授权登陆
# 对于windows来说,右键在Preferences配置,默认是打开Use Tailscale DNS seetings和Use Tailscale subnets
# 这样就能通过服务端的转发访问服务端内网设备,如果不需要,只需点对点,关闭访问内网即可
# 对于linux来说
# --accept-routes=true接受其他节点发布的子网路由,Linux设备默认不接受路由
# --accept-dns=false表示从控制面板获取默认dns
# 下面是能访问其他局域网的命令
tailscale up --accept-routes=true --accept-dns=false
# 重置
tailscale up --reset
# 下线
tailscale down
# 帮助文档
tailscale -h
# 设置对应的功能
tailscale set xxxx
2.3 出口流量转发
出口节点功能可以通过网络上的特定设备路由所有非tailscale访问互联网。运行出口路由的设备称为出口节点,局域网中的设备可以通过改节点访问互联网,流量都经过该台设备,参考:https://tailscale.com/kb/1103/exit-nodes
# 和访问局域网设备一样,首先需要开启ip流量转发
# 任意一台设备如果想成为出口节点,首先需要显示表示该台设备为出口节点
sudo tailscale up --advertise-exit-node
# 当然也可以加上子网设备,用来访问局域网
tailscale up --advertise-routes=192.168.31.0/24 --accept-routes=true --accept-dns=false --advertise-exit-node
# 然后打开控制台,点击Edit route settings中的Use as exit node按钮,开启后该节点就成为出口节点
# -----------------------------客户端开启----------------------------
# windows客户端右键,点击Exit nodes,这里就可以选择需要代理的节点了
# exit-node-allow-lan-access设置为true,表示当流量通过出口节点路由时,允许直接访问本地网络
# 对于linux
# 查看连接的节点
tailscale status
# 选择对应的出口节点
sudo tailscale up --exit-node=<exit-node-ip>
# 选择是否可以访问局域网
sudo tailscale up --exit-node=<exit-node-ip> --exit-node-allow-lan-access=true
# 可以访问一下,如果显示和真实isp不一致代表成功
curl http://myip.ipip.net/
3、Headscale 部署
3.1 服务端部署
Headscale 部署很简单,推荐直接在 Linux 主机上安装,理论上来说只要你的 Headscale 服务可以暴露到公网出口就行,但最好不要有 NAT,所以推荐将 Headscale 部署在有公网 IP 的云主机上。
sudo su
wget --output-document=/usr/local/bin/headscale \
https://github.com/juanfont/headscale/releases/download/v<HEADSCALE VERSION>/headscale_<HEADSCALE VERSION>_linux_<ARCH>
# 自行选择版本,例如我的
wget --output-document=/usr/local/bin/headscale \
https://github.com/juanfont/headscale/releases/download/v0.20.0/headscale_0.20.0_linux_amd64
# # 增加可执行权限
chmod +x /usr/local/bin/headscale
# 创建配置目录
mkdir -p /etc/headscale
# 创建目录用来存储数据与证书
mkdir -p /var/lib/headscale
# 创建空的 SQLite 数据库文件
touch /var/lib/headscale/db.sqlite
# 创建 Headscale 配置文件
wget https://github.com/juanfont/headscale/raw/main/config-example.yaml -O /etc/headscale/config.yaml
然后修改配置文件,主要是修改几个监听端口、文件位置(都放在/var/lib/headscale,注意权限)、子网段以及unix_socket
---
# Headscale 服务器的访问地址
# 负载均衡器之后这个地址也必须写成负载均衡器的访问地址
# 修改配置文件,将 server_url 改为公网 IP 或域名(使用域名的话要备案)
# 如果暂时用不到 DNS 功能,可以先将 magic_dns 设为 false
# server_url 设置为 http://:8080,将 替换为公网 IP 或者域名
# server_url: http://:8080
server_url: https://your.domain.com
# Headscale 实际监听的地址,不要127.0.0.1,否则外网访问不了
listen_addr: 0.0.0.0:8080
# 监控地址
metrics_listen_addr: 127.0.0.1:9090
# grpc 监听地址,也需要改成0.0.0.0
grpc_listen_addr: 0.0.0.0:50443
# 是否允许不安全的 grpc 连接(非 TLS)
grpc_allow_insecure: false
# 修改路径
private_key_path: /var/lib/headscale/private.key
# 客户端分配的内网网段
ip_prefixes:
- fd7a:115c:a1e0::/48
- 100.64.0.0/10
noise:
# 修改路径
private_key_path: /var/lib/headscale/noise_private.key
# 中继服务器相关配置
derp:
server:
# 关闭内嵌的 derper 中继服务(可能不安全, 还没去看代码)
enabled: false
# 下发给客户端的中继服务器列表(默认走官方的中继节点)
urls:
- https://controlplane.tailscale.com/derpmap/default
# 可以在本地通过 yaml 配置定义自己的中继接待
paths: []
# 可自定义私有网段,也可同时开启 IPv4 和 IPv6
ip_prefixes:
# - fd7a:115c:a1e0::/48
- 10.1.0.0/16
# SQLite config,修改位置
db_type: sqlite3
db_path: /var/lib/headscale/db.sqlite
tls_letsencrypt_cache_dir: /var/lib/headscale/cache
# 修改位置
unix_socket: /var/run/headscale/headscale.sock
# 使用自动签发证书是的域名
tls_letsencrypt_hostname: ""
# 使用自定义证书时的证书路径
tls_cert_path: ""
tls_key_path: ""
# 是否让客户端使用随机端口, 默认使用 41641/UDP
randomize_client_port: false
dns_config:
# 如果暂时用不到 DNS 功能,可以先将 magic_dns 设为 false
magic_dns: false
配置文件有几点需要说明,可能很多人希望使用 ACME 自动证书, 又不想占用 80/443 端口, 又想通过负载均衡器负载, ;这里详细说明一下 Headscale 证书相关配置和工作逻辑:
- Headscale 的 ACME 只支持 HTTP/TLS , 所以使用后必定占用 80/443
- 当配置了
tls_letsencrypt_hostname时一定会进行 ACME 申请 - 在不配置
tls_letsencrypt_hostname时如果配置了tls_cert_path则使用自定义证书 - 两者都不配置则不使用任何证书, 服务端监听 HTTP 请求
- 三种情况下(ACME 证书、自定义证书、无证书)主服务都只监听
listen_addr地址, 与server_url没关系 - 只有在有证书(ACME 证书或自定义证书)的情况下或者手动开启了
grpc_allow_insecure才会监听 grpc 远程调用服务
综上所述, 如果你想通过 Nginx、Caddy 反向代理 Headscale, 则你需要满足以下配置:
- 删除掉
tls_letsencrypt_hostname或留空, 防止 ACME 启动 - 删除掉
tls_cert_path或留空, 防止加载自定义证书 server_url填写 Nginx 或 Caddy 被访问的 HTTPS 地址- 在你的 Nginx 或 Caddy 中反向代理填写
listen_addr的 HTTP 地址
Nginx 配置参考 官方 Wiki, Caddy 只需要一行 reverse_proxy headscale:8080 即可(地址自行替换)。至于 ACME 证书你可以通过使用 acme.sh 自动配置 Nginx 或者使用 Caddy 自动申请等方式。
下一步创建 SystemD service 配置文件,让其能够自己开机自启,vim /etc/systemd/system/headscale.service
# /etc/systemd/system/headscale.service
[Unit]
Description=headscale controller
After=syslog.target
After=network.target
[Service]
Type=simple
User=headscale
Group=headscale
ExecStart=/usr/local/bin/headscale serve
Restart=always
RestartSec=5
# Optional security enhancements
NoNewPrivileges=yes
PrivateTmp=yes
ProtectSystem=strict
ProtectHome=yes
ReadWritePaths=/var/lib/headscale /var/run/headscale
AmbientCapabilities=CAP_NET_BIND_SERVICE
RuntimeDirectory=headscale
[Install]
WantedBy=multi-user.target
最后环节
# 创建 headscale 用户
useradd headscale -d /home/headscale -m
# 修改 /var/lib/headscale 目录的 owner
chown -R headscale:headscale /var/lib/headscale
# Reload SystemD 以加载新的配置文件
systemctl daemon-reload
# 启动 Headscale 服务并设置开机自启
systemctl enable --now headscale
# systemctl stop headscale
# systemctl disable headscale
# 查看运行状态
systemctl status headscale
# 查看占用端口
ss -tulnp|grep headscale
# 如果出现问题,可以检查一下
journalctl -u headscale.service
# 最后Tailscale 中有一个概念叫 tailnet,可以理解成租户,租户与租户之间是相互隔离的,具体看参考 Tailscale 的官方文档: https://tailscale.com/kb/1136/tailnet/
# Headscale 也有类似的实现叫 namespace,即命名空间。我们需要先创建一个 namespace,以便后续客户端接入,例如
headscale namespaces create default
# 查看命名空间
headscale namespaces list
3.2 Tailscale客户端接入
https://github.com/juanfont/headscale
--login-server: 指定使用的中央服务器地址 (必填)--advertise-routes: 向中央服务器报告当前客户端处于哪个内网网段下, 便于中央服务器让同内网设备直接内网直连 (可选的) 或者将其他设备指定流量路由到当前内网(可选)--accept-routes: 是否接受中央服务器下发的用于路由到其他客户端内网的路由规则 (可选)--accept-dns: 是否使用中央服务器下发的 DNS 相关配置 (可选, 推荐关闭)--advertise-exit-node:是否声明为出口节点,即流量都从这个节点转发(可选,根据自己需求来)--exit-node=:选择出口节点id(设置了才有)--exit-node-allow-lan-access=true:是否还可以访问本地地址(设置了出口才可以有)
Linux
Tailscale 官方提供了各种 Linux 发行版的软件包,官方还提供了 静态编译的二进制文件,我们可以直接下载
# 可以直接sh下载,不行就下面
wget https://pkgs.tailscale.com/stable/tailscale_1.38.1_amd64.tgz
tar zxvf tailscale_1.38.1_amd64.tgz
# 将二进制文件复制到官方软件包默认的路径下
cp tailscale_1.38.1_amd64/tailscaled /usr/sbin/tailscaled
cp tailscale_1.38.1_amd64/tailscale /usr/bin/tailscale
# systemD service 配置文件复制到系统路径下
cp tailscale_1.38.1_amd64/systemd/tailscaled.service /lib/systemd/system/tailscaled.service
# 将环境变量配置文件复制到系统路径下
cp tailscale_1.38.1_amd64/systemd/tailscaled.defaults /etc/default/tailscaled
# 启动 tailscaled.service 并设置开机自启
systemctl enable --now tailscaled
# 查看服务状态
systemctl status tailscaled
# Tailscale 接入 Headscale
# 这里推荐将 DNS 功能关闭,因为它会覆盖系统的默认 DNS。如果你对 DNS 有需求,可自己研究官方文档,这里不再赘述
# 将 换成你的 Headscale 公网 IP 或域名
tailscale up --login-server=http://<HEADSCALE_PUB_IP>:8080 --accept-routes=true --accept-dns=false
# 执行完上面的命令后,会出现授权信息,在浏览器中打开该链接,获得一条链接
# 将其中的命令复制粘贴到 headscale 所在机器的终端中,并将 NAMESPACE 替换为前面所创建的 namespace
headscale nodes register --user default--key nodekey:746f2e464177e2cabe1d018940a11041f7d368a022dbd9caad7e9a641ad09803
# 注册成功,查看注册的节点
headscale nodes list
# 回到 Tailscale 客户端所在的 Linux 主机,可以看到 Tailscale 会自动创建相关的路由表和 iptables 规则
ip route show table 52
# 查看 iptables 规则
iptables -S
iptables -S -t nat
Windows
Windows Tailscale 客户端想要使用 Headscale 作为控制服务器,只需在浏览器中打开 URL:http://,按照其中的步骤操作即可
Android
Android 客户端从 1.30.0 版本开始支持自定义控制服务器(即 coordination server),你可以通过 Google Play 或者 F-Droid 下载最新版本的客户端。安装完成后打开 Tailscale App,开右上角的"三个点",你会看到只有一个 About 选项,你需要反复不停地点开再关闭右上角的"三个点",重复三四次之后,便会出现一个 Change server 选项,点击 Change server,将 headscale 控制服务器的地址填进去,然后点击 Save and restart 重启,点击 Sign in with other,将其中的命令粘贴到 Headscale 所在主机的终端,将 NAMESPACE 替换为之前创建的 namespace,然后执行命令即可。注册成功后可将该页面关闭
MacOS
可以参考:https://github.com/tailscale/tailscale/wiki/Tailscaled-on-macOS
3.3 通过 Pre-Authkeys 接入
前面的接入方法都需要服务端同意,步骤比较烦琐,其实还有更简单的方法,可以直接接入,不需要服务端同意。
# 首先在服务端生成 pre-authkey 的 token,有效期可以设置为 24 小时
# headscale preauthkeys create -e 24h -n default
headscale preauthkeys create -e 24h --user default
# 查看已经生成的 key,一个是老版命令
# headscale -n default preauthkeys list
headscale --user default preauthkeys list
# 现在新节点就可以无需服务端同意直接接入了
tailscale up --login-server=http://<HEADSCALE_PUB_IP>:8080 --accept-routes=true --accept-dns=false --authkey $KEY
3.4 局域网互通
和之前一样,通过一台设备转发达到局域网互通
# 首先需要设置 IPv4 与 IPv6 路由转发
echo 'net.ipv4.ip_forward = 1' | tee /etc/sysctl.d/ipforwarding.conf
echo 'net.ipv6.conf.all.forwarding = 1' | tee -a /etc/sysctl.d/ipforwarding.conf
sysctl -p /etc/sysctl.d/ipforwarding.conf
# 客户端修改注册节点的命令,在原来命令的基础上加上参数 --advertise-routes=192.168.31.0/24,告诉 Headscale 服务器"我这个节点可以转发这些地址的路由"
tailscale up --login-server=http://<HEADSCALE_PUB_IP>:8080 --accept-routes=true --accept-dns=false --advertise-routes=192.168.31.0/24 --reset
# 在 Headscale 端查看路由,可以看到相关路由是关闭的
headscale nodes list
# 查看具体某台设备路由信息
headscale routes list -i 1
# 开启第一条路由规则,以此类推
headscale routes enable -r 1
# 之前版本好像是如下命令,但在1.38这里报错
# 这是开启所有
# headscale routes enable -i 6 -a
# 开启特定路由
# headscale routes enable -i 6 -r "192.168.100.0/24,xxxx"
# 其他节点查看路由结
ip route show table 52|grep "192.168.31.0/24"
# 其他节点启动时需要增加 --accept-routes=true 选项来声明 “我接受外部其他节点发布的路由”
最后是设置出口节点,如果要设置,登陆时加上--advertise-exit-node即可,然后在headscale可以看到0.0.0.0/0的路由,将其放行,最后在客户端选择--exit-node=以及--exit-node-allow-lan-access=true自定义选项
3.5 常用命令总结
headscale namespace list # 查看所有的namespace
headscale namespace create default # 创建namespace
headscale namespace destroy default # 删除namespace
headscale namespace rename default myspace # 重命名namespace
# 老版本--namespace/-n 替换成--user
headscale node list # 列出所有的节点
headscale node ls -t # 列出所有的节点,同时显示出tag信息
headscale -user default node ls # 只查看namespace为default下的节点
headscale node delete -i<ID> # 根据id删除指定的节点,这里面的id是node list查询出来的id
# 参考headscale nodes delete -i=6
headscale node tag -i=2 -t=tag:test # 给id为2的node设置tag为tag:test
headscale routes list -i=9 # 列出节点9的所有路由信息
headscale routes enable -i=9 -r=192.168.10.0/24 #将节点9的路由中信息为192.168.10.0/24的设置为true,
# 这样除了虚拟内网ip,原先的内网ip网段为192.168.10的也能访问了
# 后面的/24表示子网掩码是24个1,就是255.255.255.0
# 新版本命令开启第一条路由规则,以此类推
headscale routes enable -r 1
# # 老版本--namespace/-n 替换成--user
# preauthkeys主要是方便客户端快速接入,创建了preauthkeys后客户端直接使用该key就可以直接加入namespace
# headscale -n default preauthkeys list # 查看名称为default的namespace中已经生成的preauthkeys
# headscale preauthkeys create -e 24h -n default # 给名称为default的namespace创建preauthkeys
headscale --user default preauthkeys list
headscale preauthkeys create -e 24h --user default
4、中继服务器概述(可选)
4.1 STUN 是什么
Tailscale 的终极目标是让两台处于网络上的任何位置的机器建立点对点连接(直连),但大部分情况下机器都位于 NAT 和防火墙后面,这时候就需要通过打洞来实现直连,也就是 NAT 穿透。NAT 按照 NAT 映射行为和有状态防火墙行为可以分为多种类型,但对于 NAT 穿透来说根本不需要关心这么多类型,只需要看 NAT 或者有状态防火墙是否会严格检查目标 Endpoint,根据这个因素,可以将 NAT 分为 Easy NAT 和 Hard NAT。
-
Easy NAT 及其变种称为 “Endpoint-Independent Mapping” (EIM,终点无关的映射)
这里的 Endpoint 指的是目标 Endpoint,也就是说,有状态防火墙只要看到有客户端自己发起的出向包,就会允许相应的入向包进入,不管这个入向包是谁发进来的都可以。
-
hard NAT 以及变种称为 “Endpoint-Dependent Mapping”(EDM,终点相关的映射)
这种 NAT 会针对每个目标 Endpoint 来生成一条相应的映射关系。 在这样的设备上,如果客户端向某个目标 Endpoint 发起了出向包,假设客户端的公网 IP 是 2.2.2.2,那么有状态防火墙就会打开一个端口,假设是 4242。那么只有来自该目标 Endpoint 的入向包才允许通过
2.2.2.2:4242,其他客户端一律不允许。这种 NAT 更加严格,所以叫 Hard NAT。
对于 Easy NAT,我们只需要提供一个第三方的服务,它能够告诉客户端“它看到的客户端的公网 ip:port 是什么”,然后将这个信息以某种方式告诉通信对端(peer),后者就知道该和哪个地址建连了!这种服务就叫 STUN (Session Traversal Utilities for NAT,NAT会话穿越应用程序)。
对于 Hard NAT 来说,STUN 就不好使了,即使 STUN 拿到了客户端的公网 ip:port 告诉通信对端也于事无补,因为防火墙是和 STUN 通信才打开的缺口,这个缺口只允许 STUN 的入向包进入,其他通信对端知道了这个缺口也进不来。通常企业级 NAT 都属于 Hard NAT。这种情况下可以选择一种折衷的方式:创建一个中继服务器(relay server),客户端与中继服务器进行通信,中继服务器再将包中继(relay)给通信对端。至于中继的性能,那要看具体情况了:
- 如果能直连,那显然没必要用中继方式;
- 但如果无法直连,而中继路径又非常接近双方直连的真实路径,并且带宽足够大,那中继方式并不会明显降低通信质量。延迟肯定会增加一点,带宽会占用一些,但相比完全连接不上,还是可以接受的。
4.2 中继服务之TURN
TURN 即 Traversal Using Relays around NAT,这是一种经典的中继实现方式,核心理念是:
- 用户(人)先去公网上的 TURN 服务器认证,成功后后者会告诉你:“我已经为你分配了 ip:port,接下来将为你中继流量”,
- 然后将这个 ip:port 地址告诉对方,让它去连接这个地址,接下去就是非常简单的客户端/服务器通信模型了。
与 STUN 不同,这种协议没有真正的交互性,不是很好用,因此 Tailscale 并没有采用 TURN 作为中继协议。
4.3 DERP
DERP 即 Detoured Encrypted Routing Protocol,这是 Tailscale 自研的一个协议:
- 它是一个通用目的包中继协议,运行在 HTTP 之上,而大部分网络都是允许 HTTP 通信的。
- 它根据目的公钥(destination’s public key)来中继加密的流量(encrypted payloads)
Tailscale 使用的算法很有趣,所有客户端之间的连接都是先选择 DERP 模式(中继模式),这意味着连接立即就能建立(优先级最低但 100% 能成功的模式),用户不用任何等待。然后开始并行地进行路径发现,通常几秒钟之后,我们就能发现一条更优路径,然后将现有连接透明升级(upgrade)过去,变成点对点连接(直连)。因此,DERP 既是 Tailscale 在 NAT 穿透失败时的保底通信方式(此时的角色与 TURN 类似),也是在其他一些场景下帮助我们完成 NAT 穿透的旁路信道。 换句话说,它既是我们的保底方式,也是有更好的穿透链路时,帮助我们进行连接升级(upgrade to a peer-to-peer connection)的基础设施。
5、自建私有 DERP server(可选)
5.1 概述
Tailscale 的私钥只会保存在当前节点,因此 DERP server 无法解密流量,它只能和互联网上的其他路由器一样,呆呆地将加密的流量从一个节点转发到另一个节点,只不过 DERP 使用了一个稍微高级一点的协议来防止滥用。Tailscale 开源了 DERP 服务器的代码,如果你感兴趣,可以阅读 DERP 的源代码。
Tailscale 官方内置了很多 DERP 服务器,分步在全球各地,惟独不包含中国大陆。这就导致了一旦流量通过 DERP 服务器进行中继,延时就会非常高。而且官方提供的 DERP 服务器是万人骑,存在安全隐患。为了实现低延迟、高安全性,我们可以参考 Tailscale 官方文档自建私有的 DERP 服务器。有两种部署模式,一种是基于域名,另外一种不需要域名,可以直接使用 IP,可以直接参考:部署私有 DERP 中继服务器
5.2 中继服务器搭建
这里搭建的是官方推荐的,属于http搭建,docker搭建可以参考其他。首先需要注意的是, 在需要搭建 DERP Server 的服务器上, 请先安装一个 Tailscale 客户端并注册到 Headscale; 这样做的目的是让搭建的 DERP Server 开启客户端认证, 否则你的 DERP Server 可以被任何人白嫖
# 目前 Tailscale 官方并未提供 DERP Server 的安装包, 所以需要我们自行编译安装; 在编译之前请确保安装了最新版本的 Go 语言及其编译环境.
# 这里我用的go编译环境是1.21
# install的时候可能会无法访问,需要先设置代理服务
go env -w GOPROXY=https://goproxy.io,direct
# 设置不走 proxy 的私有仓库,多个用逗号相隔
go env -w GOPRIVATE=*.corp.example.com
# 编译 DERP Server
go install tailscale.com/cmd/derper@main
# 复制到系统可执行目录
mv ${GOPATH}/bin/derper /usr/local/bin
# 创建用户和运行目录
useradd \
--create-home \
--home-dir /var/lib/derper/ \
--system \
--user-group \
--shell /usr/sbin/nologin \
derper
接下来创建一个 SystemD 配置,保证开机自启,这里有几个点。默认情况下 Derper Server 会监听在 :443 上, 同时会触发自动 ACME 申请证书. 关于证书逻辑如下:
- 如果不指定
-a参数, 则默认监听:443 - 如果监听
:443并且未指定--certmode=manual则会强制使用--hostname指定的域名进行 ACME 申请证书 - 如果指定了
--certmode=manual则会使用--certmode指定目录下的证书开启 HTTPS - 如果指定了
-a为非:443端口, 且没有指定--certmode=manual则只监听 HTTP
如果期望使用 ACME 自动申请只需要不增加 -a 选项即可(占用 443 端口), 如果期望通过负载均衡器负载, 则需要将 -a 选项指定到非 443 端口, 然后配置 Nginx、Caddy 等 LB 软件即可. 最后一点 stun 监听的是 UDP 端口, 请确保防火墙打开此端口.
# /lib/systemd/system/derper.service
[Unit]
Description=tailscale derper server
After=syslog.target
After=network.target
[Service]
Type=simple
User=derper
Group=derper
ExecStart=/usr/local/bin/derper -c=/var/lib/derper/private.key -a=:12345 -stun-port=3456 -verify-clients
Restart=always
RestartSec=5
# Optional security enhancements
NoNewPrivileges=yes
PrivateTmp=yes
ProtectSystem=strict
ProtectHome=yes
ReadWritePaths=/var/lib/derper /var/run/derper
AmbientCapabilities=CAP_NET_BIND_SERVICE
RuntimeDirectory=derper
[Install]
WantedBy=multi-user.target
然后启动derp服务
# 重新加载
systemctl daemon-reload
# 开启
systemctl enable derper --now
# 重启的话,stop
systemctl restart derper.service
5.3 配置 Headscale
在创建完 Derper 中继服务器后, 我们还需要配置 Headscale 来告诉所有客户端在必要时可以使用此中继节点进行通信; 为了达到这个目的, 我们需要在 Headscale 服务器上创建以下配置,vim /etc/headscale/derper.yaml,配置说明:
regions是 YAML 中的对象,下面的每一个对象表示一个可用区,每个可用区里面可设置多个 DERP 节点,即nodes。- 每个可用区的
regionid不能重复。 - 每个
node的name不能重复。 regionname一般用来描述可用区,regioncode一般设置成可用区的缩写。ipv4字段不是必须的,如果你的域名可以通过公网解析到你的 DERP 服务器地址,这里可以不填。如果你使用了一个二级域名,而这个域名你并没有在公共 DNS server 中添加相关的解析记录,那么这里就需要指定 IP(前提是你的证书包含了这个二级域名,这个很好支持,搞个泛域名证书就行了)。stunonly: false表示除了使用 STUN 服务,还可以使用 DERP 服务。
# /etc/headscale/derper.yaml
regions:
901:
regionid: 901
regioncode: private-derper
regionname: "My Private Derper Server"
nodes:
- name: private-derper
regionid: 901
# 自行更改为自己的域名,也可以直接用ip
hostname: derper.xxxxx.com
# Derper 节点的 IP
ipv4: 121.199.167.xxx
# Derper 设置的 STUN 端口
stunport: 3456
#derpport: 12345
#stunonly: false
在创建好基本的 Derper Server 节点信息配置后, 我们需要调整主配置来让 Headscale 加载
derp:
server:
# 这里关闭 Headscale 默认的 Derper Server
enabled: false
# urls 留空, 保证不加载官方的默认 Derper,也可以加其他的,或者json可以在线修改
urls:
# - https://lamppic.oss-cn-hangzhou.aliyuncs.com/test/perf.json
# - https://controlplane.tailscale.com/derpmap/default
# 这里填写 Derper 节点信息配置的绝对路径
paths:
- /etc/headscale/derper.yaml
# If enabled, a worker will be set up to periodically
# refresh the given sources and update the derpmap
# will be set up.
auto_update_enabled: true
# How often should we check for DERP updates?
update_frequency: 24h
5.4 客户端网络调试
# 查看derp也没有成功,注意防火墙开放
http://121.199.167.xxx:12345/
# Ping 命令
# tailscale ping 命令可以用于测试 IP 连通性, 同时可以看到时如何连接目标节点的. 默认情况下 Ping 命令首先会使用 Derper 中继节点通信, 然后尝试 P2P 连接; 一旦 P2P 连接成功则自动停止 Ping
# 由于其先走 Derper 的特性也可以用来测试 Derper 连通性
tailscale ping 10.1.0.1
# Status 命令
# 通过 tailscale status 命令可以查看当前节点与其他对等节点的连接方式, 通过此命令可以查看到当前节点可连接的节点以及是否走了 Derper 中继
tailscale status
# NetCheck 命令
# 有些情况下我们可以确认是当前主机的网络问题导致没法走 P2P 连接, 但是我们又想了解一下当前的网络环境; 此时可以使用 tailscale netcheck 命令来检测当前的网络环境, 此命令将会打印出详细的网络环境报告
tailscale netcheck
5.5 Docker Compose 安装(可选)
该镜像默认开启了客户端验证, 所以请确保 /var/run/tailscale 内存在已加入 Headscale 成功的 tailscaled 实例的 sock 文件
version: '3.9'
services:
derper:
image: mritd/derper
container_name: derper
restart: always
ports:
- "8080:8080/tcp"
- "3456:3456/udp"
environment:
TZ: Asia/Shanghai
volumes:
- /etc/timezone:/etc/timezone
- /var/run/tailscale:/var/run/tailscale
- data:/var/lib/derper
volumes:
data:
参考文章:
https://www.jianshu.com/p/3a19483f2879
https://www.cnblogs.com/jonnyan/p/14175136.html
https://imnks.com/5534.html
https://tailscale.com/kb/
https://mritd.com/2022/10/19/use-headscale-to-build-a-p2p-network
https://icloudnative.io/posts/how-to-set-up-or-migrate-headscale
https://icloudnative.io/posts/custom-derp-servers/