MySQL备份恢复和主从复制(十三)
文章目录
-
- 7. Percona Xtrabackup
-
- 7.1 XBK安装
-
- 7.1.1 安装依赖包
- 7.1.1 下载软件并安装
- 7.2 XBK介绍
- 7.3 XBK全量备份
-
- 7.3.1 XBK全备前提
- 7.3.2 XBK全量备份恢复
- 7.3.3 XBK全备文件介绍
- 7.3.4 XBK全备恢复演练
- 7.4 XBK增量备份恢复
-
- 7.4.1 XBK增量备份恢复说明
- 7.4.2 XBK增量备份实践
-
- 7.4.2.1 基础环境模拟
- 7.4.2.2 模拟周日全备
- 7.4.2.3 模拟周一数据变化
- 7.4.2.4 模拟周一晚上增量备份inc1
- 7.4.2.5 模拟周二数据变化
- 7.4.2.6 模拟周二晚上增量备份inc2
- 7.4.2.7 模拟周三的数据变化
- 7.4.2.8 搞破坏
- 7.4.2.9 确认备份完整性
- 7.4.3 xbk full + inc + binlog备份恢复手段
-
- 7.4.3.1 恢复思路
- 7.4.3.2 恢复过程
- 7.4.3.2 小彩蛋和小练习
- 1. 主从复制介绍(Replication)
- 2. 主从复制前提(搭建主从的过程)
- 3. 主从复制搭建
-
- 3.1 实例准备
- 3.2 检查server_id
- 3.3 主库binlog
- 3.4 主库建立复制用户
- 3.5 主库备份恢复到从库
- 3.6 告知从库复制信息
- 3.7 在从库中开启专用复制线程
- 3.8 验证主从状态
- 3.9 验证主从环境
- 4. 主从复制原理
-
- 4.1 主从中涉及到的资源
-
- 4.1.1 文件
- 4.1.2 线程
- 4.2 主从复制原理
- 5. 主从监控
-
- 5.1 主库方面
- 5.2 从库方面
7. Percona Xtrabackup
MySQL物理备份工具-xtrabackup(XBK、Xbackup)
7.1 XBK安装
7.1.1 安装依赖包
[root@db01 ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@db01 ~]# yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL libev
7.1.1 下载软件并安装
[root@db01 ~]# wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.12/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.12-1.el7.x86_64.rpm
[root@db01 ~]# yum -y install percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm
# 可以下载依赖,用哪个都可以
[root@db01 ~]# yum -y install percona-xtrabackup-*.rpm
小提示:
(1)从2.4版本以后,都是8.0版本。8.0版本只适用8.0的数据库。
(2)XBK软件下载
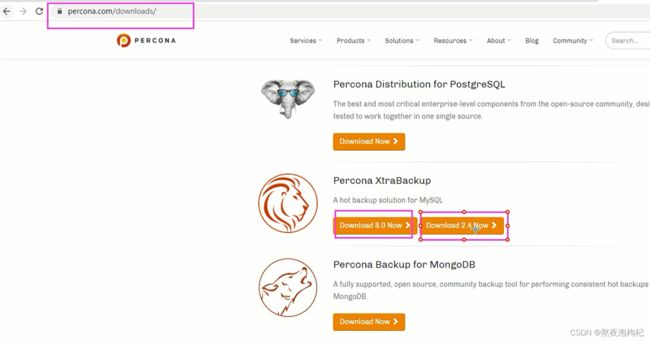

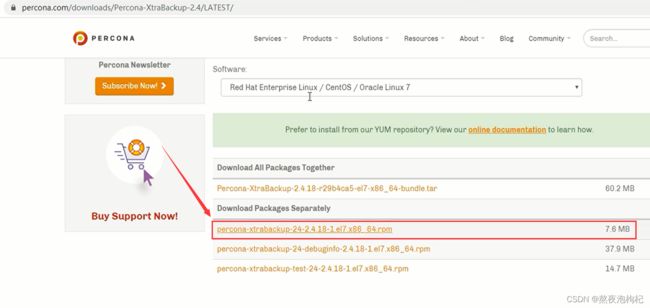
7.2 XBK介绍
物理备份工具,拷贝数据文件
InnoDB表:
热备份:业务正常发生的时候,影响较小的备份方式。不锁表,拷贝数据页,最终以数据文件的方式保存下来,把一部分redo和undo一并备走
(1) checkpoint,将已提交的数据页刷新到磁盘。记录一个LSN。
(2) 拷贝InnoDB表相关的文件(ibdata1,frm,ibd..)
(3) 备份期间产生新的数据变化的redo也会备份走。
非InnoDB表:
温备份:锁表备份,比如 myisam锁表cp数据文件
(1) FTWRL(golbal read lock),触发全局锁
(2) 拷贝非InnoDB表的数据
(3) 解锁
再次统计LSN,写入到专用文件。
记录二进制日志位置记录下来。
所有备份文件统一存放再一个目录下。
面试题:
xbk 在innodb表备份恢复的流程:
0、xbk备份执行的瞬间,立即触发ckpt,已提交的数据脏页,从内存刷写到磁盘,并记录此时的LSN号
1、备份时,拷贝磁盘数据页,并且记录备份过程中产生的redo和undo一起拷贝走,也就是checkpoint LSN之后的日志
2、在恢复之前,模拟Innodb“自动故障恢复”的过程,将redo(前滚)与undo(回滚)进行应用
3、恢复过程是cp 备份到原来数据目录下
xbk备份逻辑:
1. checkpoint,记录LSN号码
2. information_schema.xxx 读取里面数据库信息
3. 拷贝innodb文件,过程中发生的新变化redo也会保存,保存至备份路径
4. binlog只读,FTWRL(global read lock)
5. 拷贝non_innodb,拷贝完成解锁
6. 生成备份相关的信息文件,bilog,LSN
7. 刷新last LSN
8. 完成备份
7.3 XBK全量备份
7.3.1 XBK全备前提
(1) 数据库启动
(2) 能连上数据库(在配置文件进行配置或者手动指定socket位置)
# 客户端的参数不用重启MySQL
[client]
socket=/tmp/mysql.sock
(3) 默认会读取mysql文件中[mysqld] ---> datadir=xxxx
目的XBK需要拷贝数据
(4) 服务器端工具
XBK不能远程备份,只能再数据库所在的环境进行备份
7.3.2 XBK全量备份恢复
# xbk目录会自动创建
[root@db01 backup]# innobackupex --user=root --password=123 /data/xbk
# 自主定制备份路径名(备份完成时自动创建以时分秒创建文件夹,这样不太友好,加上--no-timestamp参数,自定义目录名称)
[root@db01 xbk]# innobackupex --user=root --password=123 --no-timestamp /data/xbk/full_`date +%F`
7.3.3 XBK全备文件介绍
# (1) xtrabackup_binlog_info文件记录备份后binlog位置点信息,binlog的截取起点。记录的是备份时刻,binlog的文件名字和当时的结束的position,可以用来作为截取binlog时的起点。
[root@db01 full]# cat xtrabackup_binlog_info
mysql-bin.000003 536749
79de40d3-5ff3-11e9-804a-000c2928f5dd:1-7
# (2) xtrabackup_checkpoints文件备份过程中LSN记录,方便做增量备份
[root@db01 full]# cat xtrabackup_checkpoints
backup_type = full-backuped
from_lsn = 0 上次所到达的LSN号(对于全备就是从0开始,对于增量有别的显示方法)
to_lsn = 160683027 备份开始时间(ckpt)点数据页的LSN
last_lsn = 160683036 备份结束后,redo日志最终的LSN
compact = 0
recover_binlog_info = 0
(1)备份时刻,立即将已经commit过的,内存中的数据页刷新到磁盘(CKPT).开始备份数据,数据文件的LSN会停留在to_lsn位置。
(2)备份时刻有可能会有其他的数据写入,已备走的数据文件就不会再发生变化了。
(3)在备份过程中,备份软件会一直监控着redo的undo,如果一旦有变化会将日志也一并备走,并记录LSN到last_lsn。
从to_lsn ----》last_lsn 就是,备份过程中产生的数据变化.
小提示:
# (1) 记录binlog的一个信息,记录xbk备份时,binlog记录起点,便于XBK结合binlog恢复数据的(跟mysqldump类似)
xtrabackup_binlog_info
# (2) 记录当前lsn的一个情况
xtrabackup_checkpoints
# (3) 关注度不大,全局的信息
xtrabackup_info
# (4) 备份过程中的redo信息,整个文件用vim是打不开的,是data类型的
查看文件类型:file xtrabackup_logfile
xtrabackup_logfile
7.3.4 XBK全备恢复演练
开始全备份:
[root@db01 xbk]# innobackupex --user=root --password=123 --no-timestamp /data/xbk/full_`date +%F`
模拟数据库损坏:
# 1. 破坏数据库(仅在测试环境测试)
[root@db01 ~]# systemctl stop mysqld
[root@db01 ~]# rm -rf /data/3306/*
开始恢复:
# 恢复前提:(1) 被恢复的目录是空 (2) 被恢复的数据库的实例是关闭
# 1. 备份处理: Prepared
# redo前滚, undo回滚, 模仿CSR过程。将redo进行重做,已提交的写到数据文件,未提交的使用undo回滚掉,模拟了CSR的过程。
[root@db01 ~]# innobackupex --apply-log /data/xbk/full_2023-03-04
# 2. 数据恢复:
## 为了不对原有数据产生破坏,可以选择一个空目录,然后再改mysql配置文件的数据指向
[root@db01 full_2023-03-04]# cp -a /data/xbk/full_2023-03-04/* /data/3306/
[root@db01 full_2023-03-04]# chown -R mysql.mysql /data/*
[root@db01 full_2023-03-04]# systemctl start mysqld
小提示:
# (1) 备份处理Prepared原因:
10点备份的到10:05分备份完,备份期间会拷贝redo也会备份走,备份期间会发生一些新的事务,需要将备份的redo做一些前滚或回滚的操作,启动数据库之前,
对比一下SLN,该前滚的redo前滚掉,该回滚undo回滚掉,是数据成为一致的状态数据库才能正常打开(类似于csr的一个过程))
7.4 XBK增量备份恢复
7.4.1 XBK增量备份恢复说明

# 备份恢复说明
备份时:增量必须依赖于全备。每次增量都是参照上次备份的LSN号码(xtrabackup_checkpoints), 在此基础上变化的数据页,备份走。
恢复时:将所有需要增量备份,按顺序合并到全备中。并且需要将每个备份进行prepare。
(1)增量备份的方式,是基于上一次备份进行增量。
(2)增量备份无法单独恢复。必须基于全备进行恢复。
(3)所有增量必须要按顺序合并到全备中。
7.4.2 XBK增量备份实践
7.4.2.1 基础环境模拟
mysql> create database xbk charset utf8mb4;
mysql> use xbk;
mysql> create table t1(id int);
mysql> insert into t1 values(1),(2),(3);
mysql> commit;
mysql> select * from t1;
7.4.2.2 模拟周日全备
[root@db01 ~]# rm -rf /data/backup/*
[root@db01 ~]# innobackupex --user=root --password=123456 --no-timestamp /data/backup/full
7.4.2.3 模拟周一数据变化
use xbk;
create table t2(id int);
insert into t2 values(1),(2),(3);
commit;
select * from t2;
7.4.2.4 模拟周一晚上增量备份inc1
[root@db01 ~]# innobackupex --user=root --password=123456 --no-timestamp --incremental --incremental-basedir=/data/backup/full /data/backup/inc1
说明:
--incremental 开启增量备份的开关
--incremental-basedir= 每一次的增量备份都是基于上一天的,第一次增量的上一天就是全备
7.4.2.5 模拟周二数据变化
use xbk;
create table t3(id int);
insert into t3 values(1),(2),(3);
commit;
select * from t3;
7.4.2.6 模拟周二晚上增量备份inc2
[root@db01 ~]# innobackupex --user=root --password=123456 --no-timestamp --incremental --incremental-basedir=/data/backup/inc1 /data/backup/inc2
说明:
--incremental 开启增量备份的开关
--incremental-basedir= 每一次的增量备份都是基于上一天的,第一次增量的上一天就是全备
7.4.2.7 模拟周三的数据变化
use xbk;
create table t4(id int);
insert into t4 values(1),(2),(3);
commit;
select * from t4;
create table t5(id int);
insert into t5 values(1),(2),(3);
commit;
7.4.2.8 搞破坏
[root@db01 ~]# systemctl stop mysqld (pkill mysqld)
[root@db01 ~]# rm -rf /data/3306/*
7.4.2.9 确认备份完整性
[root@db01 backup]# cat full/xtrabackup_checkpoints
backup_type = full-backuped
# 基于上一次lsn的一个情况
from_lsn = 0
# 在每次开始备份的时候,先去记录一下lsn号码
to_lsn = 246768024
# 备份结束后记录的一个lsn号码
last_lsn = 246768033
compact = 0
recover_binlog_info = 0
[root@db01 backup]# cat inc1/xtrabackup_checkpoints
backup_type = incremental
from_lsn = 246768024
to_lsn = 246774617
last_lsn = 246774626
compact = 0
recover_binlog_info = 0
[root@db01 backup]# cat inc2/xtrabackup_checkpoints
backup_type = incremental
from_lsn = 246774617
to_lsn = 246780488
last_lsn = 246780497
compact = 0
recover_binlog_info = 0
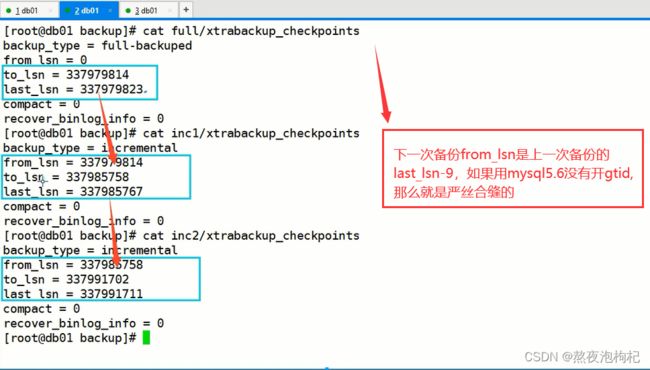
小提示:
(1)这两个差了九个号码,开了gtid之后,确实有九个的变化,严格意义上讲,如果备份期间没有数据写入,那么开始和结束的sln号码是一致的,但是差了九个,这九个是内部使用的。如果说to_lsn和last_lsn差了九个号码的话,就可以理解为整个备份期间一点变化没有。
(2)to_lsn和last_lsn也是相差九个,说明备份期间并没有新的修改,如果有修改了,会记录变化的redo,这九个号码就是内部使用的,关于gtid的一个使用,如果用mysql5.6没有开gtid,那么就是严丝合缝的
7.4.3 xbk full + inc + binlog备份恢复手段
7.4.3.1 恢复思路
1. 合并,prepare所有inc备份到全备
2. 恢复数据,启动数据库
3. 截取binlog日志
4. 恢复日志
恢复到周三误drop之前的数据状态(这里采用的是停数据库之后,模拟删除数据目录)
恢复思路:
1. 挂出维护页,停止当天的自动备份脚本
2. 检查备份:周日full+周一inc1+周二inc2,周三的完整二进制日志
3. 进行备份整理(细节),截取关键的二进制日志(从备份——误删除之前)
4. 测试库进行备份恢复及日志恢复
5. 应用进行测试无误,开启业务
7.4.3.2 恢复过程
# 1. 合并,prepare所有inc备份到全备
# 基础全备整理
innobackupex --apply-log --redo-only /data/backup/full
--redo-only This option should be used when preparing the base full
backup and when merging all incrementals except the last
one. This forces xtrabackup to skip the "rollback" phase
and do a "redo" only. This is necessary if the backup
will have incremental changes applied to it later. See
the xtrabackup documentation for details.
# 合并,prepare inc1 合并到 full
innobackupex --apply-log --redo-only --incremental-dir=/data/backup/inc1 /data/backup/full
# 合并,prepare inc2 合并到full
innobackupex --apply-log --incremental-dir=/data/backup/inc2 /data/backup/full
# 整体再次prepare整个备份
innobackupex --apply-log /data/backup/full
# 2. 修复数据库
[root@db01 ~]# chown -R mysql.mysql /data/backup/full
[root@db01 ~]# vim /etc/my.cnf
# 修改以下内容
datadir=/data/backup/full
# 重启数据库
[root@db01 ~]# systemctl start mysqld
# 3. 截取日志并恢复(数据库启动状态才能进行二进制日志恢复)
# 起点(这里的gtid为什么两段:使用后面一段,因为做过一次全备恢复,恢复之前的gtid是前一段的值,恢复之后的gtid的是后一段的值)
[root@db01 ~]# cat /data/backup/inc2/xtrabackup_binlog_info
mysql-bin.000020 1629 xxx:1-19,xxx:1-7
# 终点: 最后一个binlog文件(文件末尾,因为整个文件到头了,不用写--stop-position)
[root@db01 ~]# mysqlbinlog --skip-gtids --start-position=1629 /data/binlog/mysql-bin.000020>/tmp/bin.sql
[root@db01 ~]# mysql -uroot -p123456
mysql> set sql_log_bin=0;
mysql> source /tmp/bin.sql;
mysql> set sql_log_bin=1;
小细节:
1. 每次xbk恢复后,可以reset master清除无用的gtid信息
2. 每次故障恢复完后,立即做全备
3. 如果出现增量合并不了怎么办
FULL+binlog方式恢复
小提示:
(1)基础全备整理:–apply-log 全备的redo和undo都应用一下,xbk备份要合并的话last_lsn和下一个增量的last_lsn差九个号码才能合并,实验数据库再备份,期间没有发生任何变化,如果是生产环境的话,备份期间会出现新的备份录入或新的数据变化,如果再全备过程中进行undo和redo的回滚,有可能会导致last_lsn号码发生变化,所以需要再加上–redo-only参数,只应用redo,redo的最新的lsn号码就是last_lsn,可以防止与增量的last_lsn对接不上了。只前滚不回滚,最后一次增量不用加 --redo-only这个参数(–redo-only参数详细说明)
(2)合并,prepare inc1 合并到 full,合并完成后进行检查,此时的full和inc1的last_lsn号一致

(3)合并,prepare inc1 合并到 full,合并完成后进行检查,此时的full和inc2的last_lsn号一致

7.4.3.2 小彩蛋和小练习
小彩蛋:


直接用3307的多实例,直接拉起来,把表结构拿出来,拿出来建一下

小练习:
练习1
Xtrabackup企业级增量恢复实战
背景:
某大型网站,mysql数据库,数据量500G,每日更新量20M-30M
备份策略:
xtrabackup,每周日0:00进行全备,周一到周六00:00进行增量备份。
故障场景:
周三下午2点出现数据库意外删除表操作。
如何恢复?
练习2
练习:mysqldump备份恢复例子
1、创建一个数据库 test666
2、在test666下创建一张表t1
3、插入5行任意数据
4、全备
5、插入两行数据,任意修改3行数据,删除1行数据
6、删除所有数据
7、再t1中又插入5行新数据,修改3行数据
需求,跳过第六步恢复表数据
练习3
分别写备份脚本和策略
练习4:备份集中单独恢复表
思考:在之前的项目案例中,如果误删除的表只有10M,而备份有500G,该如何快速恢复误删除表?
提示:
drop table city;
create table city like city_bak;
alter table city discard tablespace;
cp /backup/full/world/city.ibd /application/mysql/data/world/
chown -R mysql.mysql /application/mysql/data/world/city.ibd
alter table city import tablespace;
练习5: 从mysqldump 全备中获取库和表的备份
1、获得表结构
# sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `city`/!d;q' full.sql>createtable.sql
2、获得INSERT INTO 语句,用于数据的恢复
# grep -i 'INSERT INTO `city`' full.sqll >data.sql &
3.获取单库的备份
# sed -n '/^-- Current Database: `world`/,/^-- Current Database: `/p' all.sql >world.sql
练习6:
自行学习mydumper
自行研究into outfile / load data in file
1. 主从复制介绍(Replication)
主从复制基于二进制日志复制的,主库的修改操作会记录二进制日志,从库会请求新的二进制日志并回放,最终达到主从数据同步。
两台或以上数据库实例,通过二进制日志,实现数据的"同步"关系。(这个同步不是在工作中100%同步的,因为本身就是异步的工作模式)
主从复制核心功能:辅助备份,处理物理损坏
扩展新型的架构:高可用,高性能,分布式架构等
2. 主从复制前提(搭建主从的过程)
(1)需要两台以上数据库实例,时间同步,网络通畅,server_id不同,区分不同角色(主库,从库)。
(2)主库开启binlog,建立专用复制用户。
(3)从库需要提前"补课"(再主库进行全备,恢复到从库)
(4)从库:主库的链接信息(用户名、密码、IP地址、端口号等信息告诉从库),确认复制起点。
(5)从库:开启专用的复制线程。
3. 主从复制搭建
3.1 实例准备
[root@db01 ~]# systemctl start mysqld3307
[root@db01 ~]# systemctl start mysqld3308
[root@db01 ~]# systemctl start mysqld3309
[root@db01 ~]# netstat -tlunp
3.2 检查server_id
[root@db01 ~]# mysql -S /tmp/mysql3307.sock -e "select @@server_id"
+-------------+
| @@server_id |
+-------------+
| 7 |
+-------------+
[root@db01 ~]# mysql -S /tmp/mysql3308.sock -e "select @@server_id"
+-------------+
| @@server_id |
+-------------+
| 8 |
+-------------+
[root@db01 ~]# mysql -S /tmp/mysql3309.sock -e "select @@server_id"
+-------------+
| @@server_id |
+-------------+
| 9 |
+-------------+
3.3 主库binlog
[root@db01 ~]# mysql -S /tmp/mysql3307.sock -e "select @@log_bin"
+-----------+
| @@log_bin |
+-----------+
| 1 |
+-----------+
3.4 主库建立复制用户
[root@db01 ~]# mysql -S /tmp/mysql3307.sock -e "grant replication slave on *.* to repl@'10.0.0.%' identified by '123'"
[root@db01 ~]# mysql -S /tmp/mysql3307.sock -e "select user,host from mysql.user"
+---------------+-----------+
| user | host |
+---------------+-----------+
| repl | 10.0.0.% |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+-----------+
3.5 主库备份恢复到从库
[root@db01 ~]# mysqldump -S /tmp/mysql3307.sock -A --master-data=2 --single-transaction > /tmp/all.sql
[root@db01 ~]# mysql -S /tmp/mysql3308.sock < /tmp/all.sql
[root@db01 ~]# mysql -S /tmp/mysql3309.sock < /tmp/all.sql
3.6 告知从库复制信息
mysql> help change master to
CHANGE MASTER TO
MASTER_HOST='10.0.0.61',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=444,
MASTER_CONNECT_RETRY=10;
[root@db01 ~]# grep "\-- CHANGE MASTER TO" /tmp/all.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=444
[root@db01 ~]# mysql -S /tmp/mysql3308.sock
mysql> CHANGE MASTER TO
MASTER_HOST='10.0.0.61',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=444,
MASTER_CONNECT_RETRY=10;
[root@db01 ~]# mysql -S /tmp/mysql3309.sock
mysql> CHANGE MASTER TO
MASTER_HOST='10.0.0.61',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=444,
MASTER_CONNECT_RETRY=10;
3.7 在从库中开启专用复制线程
[root@db01 ~]# mysql -S /tmp/mysql3308.sock
mysql> start slave;
[root@db01 ~]# mysql -S /tmp/mysql3309.sock
mysql> start slave;
3.8 验证主从状态
[root@db01 ~]# mysql -S /tmp/mysql3308.sock -e "show slave status\G"| grep Running:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[root@db01 ~]# mysql -S /tmp/mysql3309.sock -e "show slave status\G"| grep Running:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
小提示:
如果根据上面步骤的搭建不成功,可以执行以下命令,从3.1-3.8步骤重新操作。(如果搭建成功,不要执行)
[root@db01 ~]# mysql -S /tmp/mysql3308.sock -e "stop slave;reset slave all;"
[root@db01 ~]# mysql -S /tmp/mysql3309.sock -e "stop slave;reset slave all;"
3.9 验证主从环境

4. 主从复制原理
4.1 主从中涉及到的资源
4.1.1 文件
(1) 主库:binlog文件
(2) 从库:
# relay-log文件
作用: 存储接收的binlog
位置: 默认从库的数据目录下
手动定义方法: relay_log_basename=/data/3308/data/db01-relay-bin
# master.info文件
作用: 连接主库的信息,已经接收binlog位置点信息
位置: 默认存储在从库的数据路径下
手工定义: master_info_repository = FILE/TABLE
mysql> show variables like '%master%';
master_info_repository = FILE/TABLE 默认是保存在文件中的,如果修改存在表中可以提高效率
# relay-log.info
作用: 记录从库回放到的relay-log的位置点。(relay-log.info防止从库宕机找不到回放的起点)
位置: 默认在从库的数据路径下
relay-log.info
手工定义: relay_log_info_repository=FILE/TABLE
4.1.2 线程
(1) 主库
Binlog_dump_Thread
作用: 用来接收从库请求,并且投递binlog给从库。
mysql> show processlist;
+----+------+-----------------+------+-------------+------+---------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------------+------+-------------+------+---------------------------------------------------------------+------------------+
| 8 | repl | 10.0.0.61:55040 | NULL | Binlog Dump | 9371 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 9 | repl | 10.0.0.61:55144 | NULL | Binlog Dump | 9238 | Master has sent all binlog to slave; waiting for more updates | NULL
+----+------+-----------------+------+-------------+------+---------------------------------------------------------------+------------------+
(2) 从库
IO线程: 请求binlog日志,接收binlog日志
SQL线程: 回放relay日志
# 就是这个两个线程,如果是yes表明正在工作
[root@db01 ~]# mysql -S /tmp/mysql3308.sock -e "show slave status\G"| grep Running:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
4.2 主从复制原理
主从复制原理图:

小提示:搭建主从的时候,最后执行start slave命令,然后就启动了两个线程,sql和io线程,然后才能去连接主库,这个原理图中没有体现
文字说明:
(1) slave: change master to IP,port,user,password,binlog位置信息写入到M.info中,执行start slave(启动sql和io线程)
(2) slave: 连接主库
(3) master: 分配dump线程,专门和slave的io线程通信(show processlist;可以进行查看)
(4) slave: IO线程请求新日志
(5) master: dump线程接收请求,截取日志,返回给slave的IO线程
(6) slave: IO线程接收到binlog,日志放在TCP/IP,此时网络层层面返回ACK给主库,主库工作完成
(7) slave: IO将binlog最终写入到relaylog中,并更新M.info。IO线程结束。
(8) slave: SQL线程读R.info,获取上次执行到的位置点
(9) slave: SQL线程向后执行新的relay-log,再次更新R.info
小细节:
(1) slave: relay-log参数 relay_log_purge=ON,定期删除应用过的relay-log
(2) master: DUMP线程实时监控主库的binlog变化,如果有新变化,发信号给从库。
5. 主从监控
5.1 主库方面
# 登录到主库执行
mysql> show processlist;
mysql> show slave hosts;
5.2 从库方面
# 登录到从库执行
mysql> show slave status \G
# 主库相关信息,来自于M.info:
Master_Host: 10.0.0.61
Master_User: repl
Master_Port: 3307
Connect_Retry: 10
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 603
# 从库的relay-log的执行情况,来自于R.info,一般用做判断主从延时
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 479
Relay_Master_Log_File: mysql-bin.000002
Exec_Master_Log_Pos: 603
Seconds_Behind_Master: 0
# 从库线程状态,具体报错信息
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
# 过滤相关信息 (有这么以一种需求,主库里面有十个库,但是只想复制其中五个,或者指向复制其中两个这个时候就不能全盘复制了,现在实验搭建的主从,有多少复制多少。如果有这样的需求,可以修改下面的参数来实现)
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
# 延时从库的配置信息 (延时从库和主从延时是两码事,主从延时是我们不想看到的,而延时从库是我们认为控制的
)
SQL_Delay: 0
SQL_Remaining_Delay: NULL
# GTID相关复制信息 (GTID主要是为了主从复制来设计的,5.7版本mysql的主从复制大多都是GTID模式,而不是普通的position号模式
)
Retrieved_Gtid_Set:
Executed_Gtid_Set: