半监督分割:从数据增强到学习范式
转载:半监督分割:从数据增强到学习范式 (deserts.io)
图像分割应用的最大阻碍是缺乏高质量标注的训练数据。深度分割模型的泛化能力依赖大规模和高质量的像素级标注数据。 事实上,图像分割标注是一个昂贵且耗时的过程。对于新的任务或是需要快速应用的场景,数据稀缺问题更为严重。因此,数据标注的高成本降低了模型在新任务和扩展性,从而阻碍了深度分割模型在现实中的应用。
为了缓解数据标注压力,当前已有大量的工作来进行半监督和弱监督的图像分割。例如,利用少量精确标注的数据、稀疏的标注、带噪声的标注、分类标注或者以上几种组合实现半监督图像分割模型。 然而,半监督图像分割具有其天然的难度和挑战性,需要特定的模型设计以及学习策略。
目录
任务
半监督分割相关方法
数据增强
自监督学习
迁移学习
课程学习
小样本学习
自训练
协同训练
一致性正则
对抗训练
总结
任务
任务: 训练集中只有一个子集有完全的标注。
半监督学习的几个假设:
- 平滑性假设:相近的图片应该具备相同的标注;
- 低密度分离假设(聚类假设):决策边界应该位于数据分布密度相对较低的区域(见下图);
- 流形假设:输入空间由多个低维流形组成,所有数据点均位于其上;位于同一流形上的数据点具有相同标签。
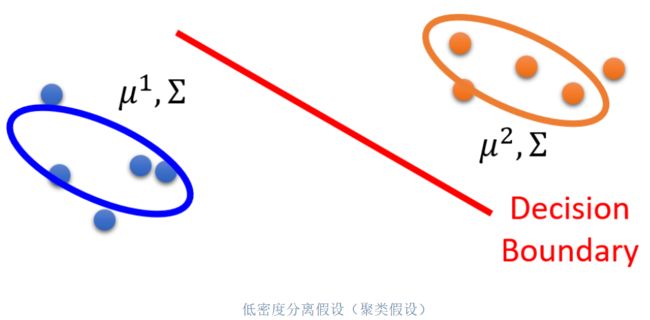
挑战:半监督学习场景的主要挑战在于如何高效、彻底地利用大量未标记的数据。
- 从少量数据中学习并防止过拟合
- 充分利用无标记数据
- 利用先验知识获得泛化性能更好的模型
半监督分割相关方法
半监督分割的最常见方法包括:
- 通用策略:数据增强、迁移学习、先验知识学习、课程学习和小样本学习;
- 利用未标记数据:自训练、一致性正则、协同训练、自监督学习和对抗学习。
数据增强
数据增强能够降低过拟合到少量标注数据的风险。
经典的数据增强方法: 数据几何变换,例如随机仿射变换、随机裁剪、随机擦除、颜色强度变换等;
合成更多样化和更真实的标记数据的方法: 混合图像、特征空间增强和生成对抗网络 。
 几种经典的数据增强方式(来自SimCLR)
几种经典的数据增强方式(来自SimCLR)
Mixing and Cutting: Mixup线性插值一对随机的训练图像和相应的标签。Cutout在训练数据上采用区域 dropout 策略的思想,即遮挡图像的一部分。CutMix是 Mixup 和 Cutout 结合,通过用不同图像的一部分替换图像的一部分[1]。
 CutMix示意。第一行:输入一对原图;第二行:MixUp,CutOut,CutMix
CutMix示意。第一行:输入一对原图;第二行:MixUp,CutOut,CutMix
Auto Augment: 基于强化学习的搜索算法为目标数据集寻找最有效的数据增强策略[2],来最小化验证集上的误差。这里选择16种图像变换来限制策略搜索空间。一个策略由5个子策略组成,每个子策略依次应用两个图像变换。每个变换包含两个参数:使用的概率和强度(例如,在70%概率下旋转30度)。为了使用离散搜索算法,作者将强度范围离散为10个值(均匀间距),同时将概率离散化为11个值(均匀间距)。模型使用控制器决定哪种数据增强策略,并通过在验证集上运行一个子模型实验来测试该策略的泛化能力。控制器以验证的准确性作为奖励信号进行更新,使用近似策略优化算法更新控制器参数。最后总体上最好的5个策略(每个包含5个子策略)被选择作为该数据集上的最佳策略。
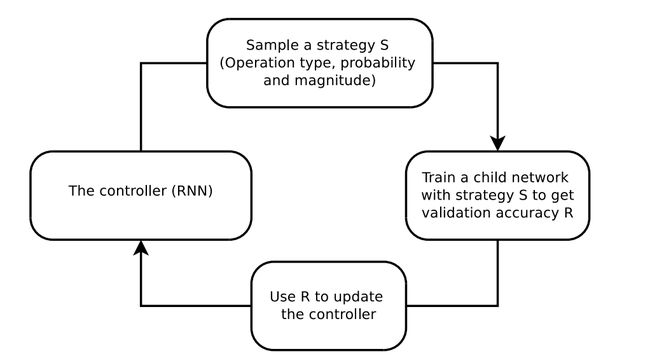 AutoAugment使用强化学习来搜索更好的数据增强策略。控制器RNN从搜索空间中预测一个增广策略S。一个具有固定结构的子网络根据S训练到收敛,得到精度R。再利用Policy gradient方法,将精度R作为奖励信号来更新控制器参数。
AutoAugment使用强化学习来搜索更好的数据增强策略。控制器RNN从搜索空间中预测一个增广策略S。一个具有固定结构的子网络根据S训练到收敛,得到精度R。再利用Policy gradient方法,将精度R作为奖励信号来更新控制器参数。
 AutoAugment在ImageNet上学到的一个最佳增强策略,对于该数据集更倾向于使用颜色变换而不是空间变换。(横向)同一个策略中包含五个子策略,对于一个batch中的每一张图,都随机地从五个子策略中选取一个。(纵向)为了强调子策略应用的随机性,即使应用同一个子策略,同一图像在不同的batch中得到的结果是不同的。
AutoAugment在ImageNet上学到的一个最佳增强策略,对于该数据集更倾向于使用颜色变换而不是空间变换。(横向)同一个策略中包含五个子策略,对于一个batch中的每一张图,都随机地从五个子策略中选取一个。(纵向)为了强调子策略应用的随机性,即使应用同一个子策略,同一图像在不同的batch中得到的结果是不同的。
Adversarial data augmentation: 利用对抗样本(adversarial example[3,5],见下图)来训练鲁棒的模型。如何设计和构造更逼真的对抗扰动是核心问题。
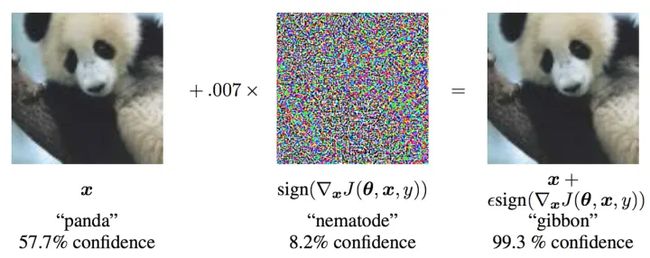 对抗扰动示意图[3]. x:原始输入图像,y:标签(panda),θ:模型参数,J(θ,x,y):目标函数。攻击将梯度回传到输入数据,计算出J对x的梯度。然后,在梯度的方向上对输入数据添加小的扰动(ϵ=0.007)使损失最大化。由此产生的扰动图像x’,被网络错误地归类为 "gibbon",而它显然是一只 "熊猫"。
对抗扰动示意图[3]. x:原始输入图像,y:标签(panda),θ:模型参数,J(θ,x,y):目标函数。攻击将梯度回传到输入数据,计算出J对x的梯度。然后,在梯度的方向上对输入数据添加小的扰动(ϵ=0.007)使损失最大化。由此产生的扰动图像x’,被网络错误地归类为 "gibbon",而它显然是一只 "熊猫"。
基于梯度的对抗样本生成方法直观且强大。它旨在通过利用神经网络的学习方式,即梯度来攻击神经网络。攻击使用损失函数对输入数据的梯度,调整输入数据以最大化损失。Fast Gradient Sign Method (FGSM)[3]形式化表述为:
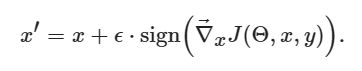
# FGSM attack code from https://pytorch.org/tutorials/beginner/fgsm_tutorial.html
def fgsm_attack(image, epsilon, data_grad):
# Collect the element-wise sign of the data gradient
sign_data_grad = data_grad.sign()
# Create the perturbed image by adjusting each pixel of the input image
perturbed_image = image + epsilon*sign_data_grad
# Adding clipping to maintain [0,1] range
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# Return the perturbed image
return perturbed_image
# input image
data.requires_grad = True
# Forward pass the data through the model
output = model(data)
# Calculate the loss
loss = F.nll_loss(output, target)
# Zero all existing gradients
model.zero_grad()
# Calculate gradients of model in backward pass
loss.backward()
# Collect datagrad
data_grad = data.grad.data
# Call FGSM Attack
perturbed_data = fgsm_attack(data, epsilon, data_grad)Generative adversarial networks: 直接合成新的带标签的数据来做数据增强。例如跨模态数据合成等。
参考文献:
[1] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. (ICCV 19)
[2] AutoAugment: Learning Augmentation Policies from Data. (CVPR 19)
[3] Explaining and Harnessing Adversarial Examples. (ICLR 15)
[4] AutoAugment - Learning Augmentation Policies from Data. (CVPR 19)
[5] DeepFool: a simple and accurate method to fool deep neural networks. (CVPR 16)
自监督学习
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。对比学习是一种比较流行的自监督辅助任务。
少量论文研究了如何构建像素级的自监督辅助任务,如[1]中根据像素空间距离构建像素级的正负样本对来进行像素级的自监督学习。
参考文献:
[1] Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning. (CVPR 21)
[2] Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation. (MICCAI 21)
迁移学习
在许多深度学习研究中,迁移学习也狭义地指“预训练再微调”策略,如backbone训练和数据集迁移。例如,SimCLRv2自监督学习通用表征,通过fine-tune和知识蒸馏实现半监督分类。
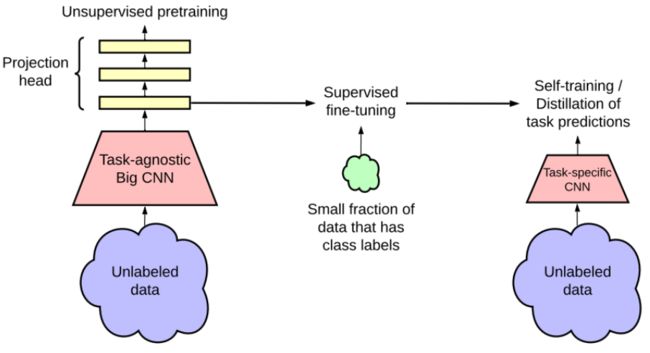 SimCLRv2迁移学习的半监督框架:(左)自监督预训练 (中)在小数据集上fine-tune (右)在无标记数据集上做知识蒸馏/自训练
SimCLRv2迁移学习的半监督框架:(左)自监督预训练 (中)在小数据集上fine-tune (右)在无标记数据集上做知识蒸馏/自训练
课程学习
课程学习首先从任务的更简单的方面或更简单的子任务开始,然后逐渐增加难度级别。
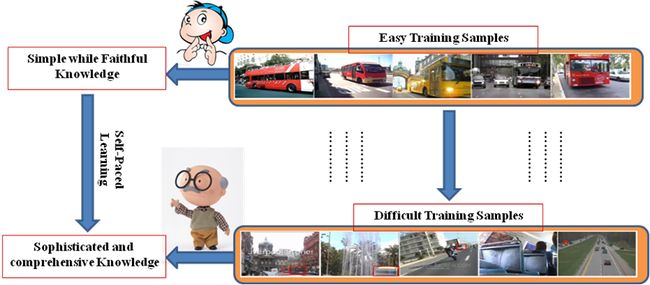 自步学习(self-paced learning)示意图,根据模型的反馈(如loss)动态地决定学习的顺序。
自步学习(self-paced learning)示意图,根据模型的反馈(如loss)动态地决定学习的顺序。
- 数据(data)课程学习:重加权(reweighting)目标训练分布的数据,即对训练数据进行非均匀采样。核心在于如何确定样本的重要性,并基于重要性决定样本呈现的顺序。因此它能够很好的和先验知识结合。实验表明这种方式能避免糟糕的局部最优并取得良好的泛化能力[1]。例如,根据病例的严重程度决定训练顺序,或是multiple experts的不确定性作为困难程度。
自步(self-paced) 学习是一种特殊的数据课程学习:它根据模型的反馈(如loss),动态地决定数据学习顺序[2]。 - 任务(task)课程学习:首先解决简单但相关的任务,为以后解决更复杂的任务提供辅助信息。类似于分割的多阶段训练。例如,对于左心室的分割,先学习目标区域的大小,再学习分割任务[3]。
参考文献:
[1] Deep active self-paced learning for accurate pulmonary nodule segmentation. (MICCAI 18)
[2] Selfpaced curriculum learning. (AAAI 15)
[3] Curriculum semi-supervised segmentation. (MICCAI 19)
小样本学习
小样本分割(Few-shot Segmentation,FSS)的目的是在基础(base)语义类别上学习一个模型,但在未见过(unseen)的类别上,只用k个带标注的样本实现语义分割,而无需重新训练模型。新类别的k个带标注的样本通常被称为支持集(support set)。FSS根据support set预测每个查询图像(query set)的分割。
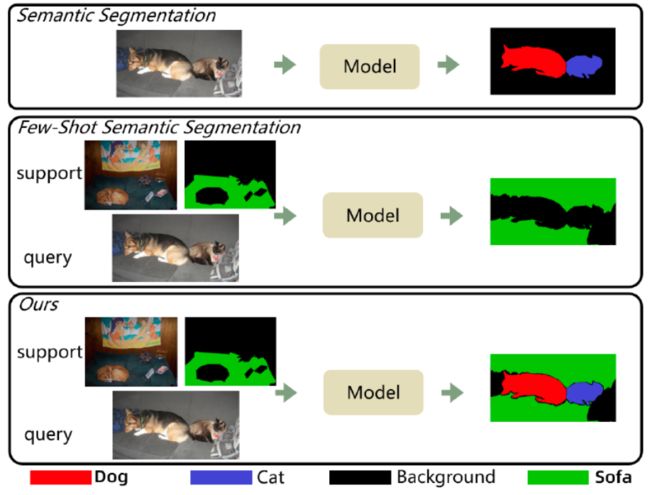 1)语义分割 (2) 小样本Few-shot分割 (3) Generalized Few-shot分割。给定大量基础类(base classes)的训练图像(如图中狗和猫),上图展示了语义分割、few-shot分割和Generalized Few-shot分割在 测试时的区别。语义分割是对已学过的基础类的图像区域进行分割。Few-shot语义分割的目的是对少数测试的support set所提供的新类(例如图中的沙发)进行分割。Generalized Few-shot目标是同时对基础类和新类的进行分割。
1)语义分割 (2) 小样本Few-shot分割 (3) Generalized Few-shot分割。给定大量基础类(base classes)的训练图像(如图中狗和猫),上图展示了语义分割、few-shot分割和Generalized Few-shot分割在 测试时的区别。语义分割是对已学过的基础类的图像区域进行分割。Few-shot语义分割的目的是对少数测试的support set所提供的新类(例如图中的沙发)进行分割。Generalized Few-shot目标是同时对基础类和新类的进行分割。
现有的小样本分割方法分类:
- 基于分类的原型网络(Prototypical Networks)[1],使用后处理来获得分割结果[2](与弱监督语义分割类似);
- 直接利用propotypes做像素级的度量而不用后处理[3],也就是把分割作为逐像素的分类。
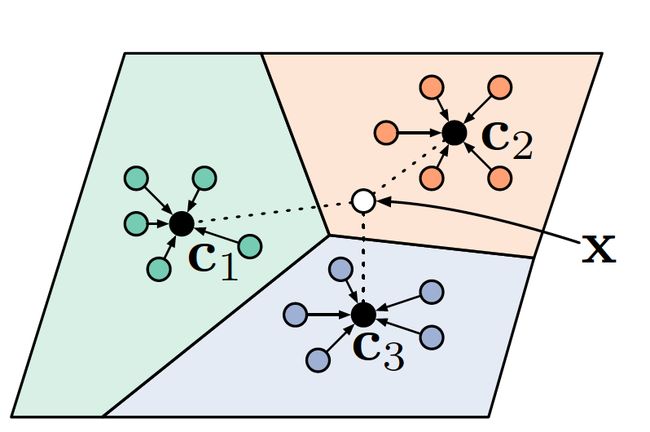 原型(prototypes)是指每个类别的support set样本的embedding的均值
原型(prototypes)是指每个类别的support set样本的embedding的均值
原型网络: 是一种基于度量学习的元学习方法,它将样本投影到一个度量空间,且在这个空间中同类样本距离较近,异类样本的距离较远。(上图)原型(prototypes)是指每个类别的support set样本的embedding的均值,query样本通过计算与prototypes的距离进行分类。
如何将图像映射到一个良好的度量空间?这里使用一个神经网络f作为映射(Embedding)函数,下面的训练流程就是在学习该网络的参数ΦΦ.
训练思想:这个训练策略是在训练时构造测试时的few-shot场景(episode),也就是模型试图学会解决一类问题,而不是解决问题。


如何理解few-shot learning中的n-way k-shot? - 知乎
参考文献:
[1] Prototypical Networks for Few-shot Learning. (NeurIPS 17)
[2] CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning. (CVPR 19)
[3] PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment. (ICCV 19)
自训练
自训练是指模型最初只在小规模的标记数据上进行训练,然后同时用带标记数据和伪标记数据进行训练。
自训练的挑战主要是: 1)提高伪标签质量和2)减少噪声伪标签的负面影响。
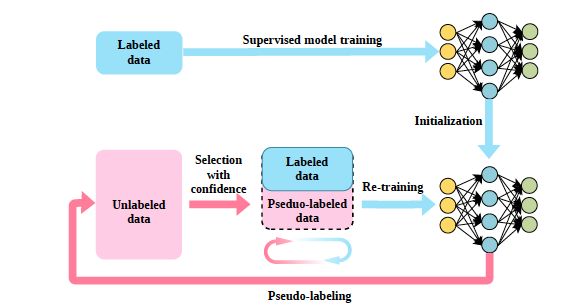 自训练流程
自训练流程
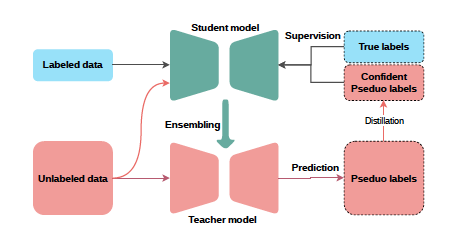 Teacher-student自训练示意图
Teacher-student自训练示意图
为了降低噪声伪标签的负面影响,使用多种不确定性或置信度估计方法,整体上不确定性估计可以分为:
- 数据不确定性(aleatoric uncertainty)
- 模型不确定性(epistemic uncertainty)
在深度网络中生成伪标签和量化不确定性的流行方法包括贝叶斯神经网络、Monte Carlo Dropout、Monte Carlo BatchNorm,以及深度集成(Deep ensemble)。贝叶斯神经网络通过学习参数的后验分布来捕捉模型的不确定性,通常难以实现且训练计算速度缓慢 。
非贝叶斯策略,包括 Monte Carlo Dropout 和深度集成更有吸引力:
- Monte Carlo Dropout:随机Dropout的情况下,利用深度网络的多个前向的结果来估计不确定性。
- Deep Ensemble:分别训练不同训练子集 或不同初始化的多个网络,然后将预测结合起来进行不确定性估计。
医疗影像分割中,[1,2,3]使用Monte Carlo Dropout作为Uncertainty来指导未标注/弱标注数据的自训练。[4] 使用多模型Ensemble估计置信度,使用不同的初始化和训练顺序。
参考文献:
[1] A Macro-Micro Weakly-supervised Framework for AS-OCT Tissue Segmentation. (MICCAI 20)
[2] Uncertainty guided semi-supervised segmentation of retinal layers in OCT images. (MICCAI 19)
[3] Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation. (MICCAI 19)
[4] Confidence Calibration and Predictive Uncertainty Estimation for Deep Medical Image Segmentation. (TMI 20)
协同训练
协同训练 Co-training[1]可以视作自训练/伪标签训练的一个扩展:将单网络自训练扩展至多个模型。在半监督分割中,通常使用不同训练子集 或不同初始化的多个网络,彼此互相提供伪标签(或是估计不确定性)来实现协同训练。
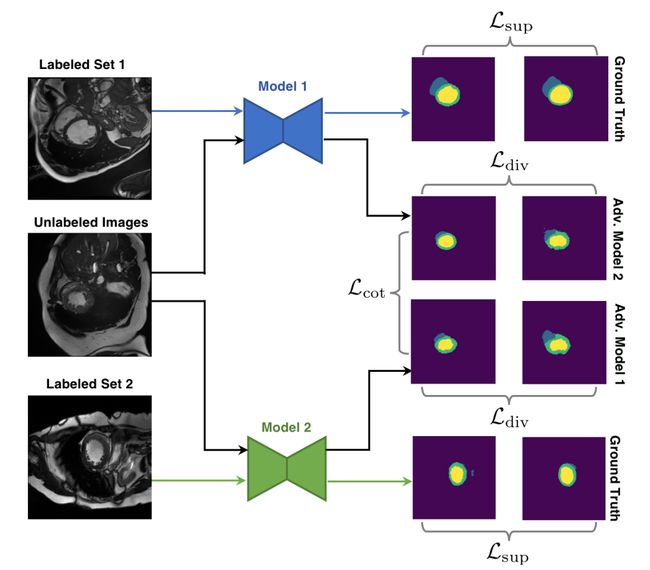 Co-Training Segmentation框架:两个模型用两个标注集的子集训练保证差异性;未标记数据作为公共数据;三个loss分别约束标注样本的预测与groud-truth的一致,约束未标注样本在两个网络间的一致,以及约束两个网络预测的对抗样本一致。[2]
Co-Training Segmentation框架:两个模型用两个标注集的子集训练保证差异性;未标记数据作为公共数据;三个loss分别约束标注样本的预测与groud-truth的一致,约束未标注样本在两个网络间的一致,以及约束两个网络预测的对抗样本一致。[2]
参考文献:
[1] Deep Co-Training for Semi-Supervised Image Recognition. (ECCV 18)
[2] Deep Co-Training for Semi-Supervised Image Segmentation. (PR 20)
一致性正则
一致性正则基于模型应该对类似的输入产生一致的预测的假设:模型对同一个样本不同扰动或变换的版本,应输出相同的预测。也就是最小化不同版本的预测之间的差异,以获得一个具有更好泛化能力的模型。一致性正则是半监督,弱监督以及噪声标签学习中使用最广泛的正则方法。

分割任务中常见的扰动/变换:
- 输入图像颜色变换[1]
- 图像几何变换(对于几何/空间变换,分割强调等变性,而分类要求不变性)
- 中间特征扰动(如Dropout)[2]
- 网络参数扰动(两个网络不同的初始化),类似于co-training
输出一致性损失形式:
- 最小化预测概率/中间特征的距离(MSE,JS,KL divergence)[2]
- 生成伪标签监督(Cross Entropy)[1,3]
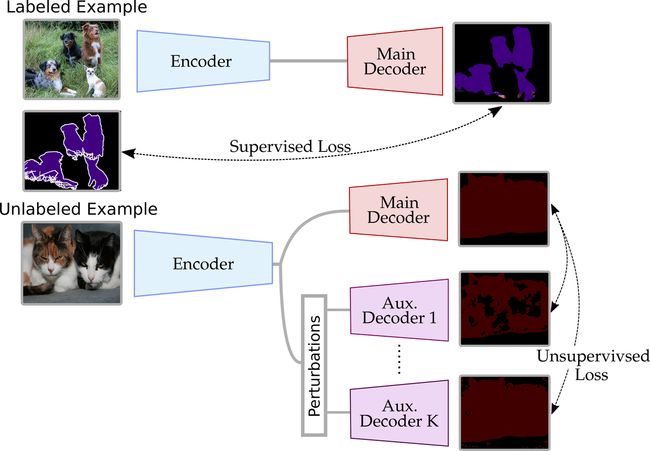 标题CCT: Cross-Consistency Training[2] 基于中间特征扰动的一致性正则。对未标注标的样本的中间特征加扰动,约束不同输出间的一致性。其中,扰动包括随机噪声,随机Dropout,cutout等。
标题CCT: Cross-Consistency Training[2] 基于中间特征扰动的一致性正则。对未标注标的样本的中间特征加扰动,约束不同输出间的一致性。其中,扰动包括随机噪声,随机Dropout,cutout等。
参考文献:
[1] PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. (ICLR 21)
[2] Semi-Supervised Semantic Segmentation with Cross-Consistency Training. (CVPR 20)
对抗训练
生成对抗网络(GAN)训练两个子网络,一个作为鉴别器,旨在识别样本是来自真实数据还是由生成器生成,另一个作为生成器,旨在生成鉴别器无法区分的样本。GAN已经被广泛用于半监督分割[1,2]和域适应分割中。例如,一种直接的想法是:鉴别器输出的置信度可以被当作质量评估,用于选择最好的预测结果用于后续的self-training[1]。
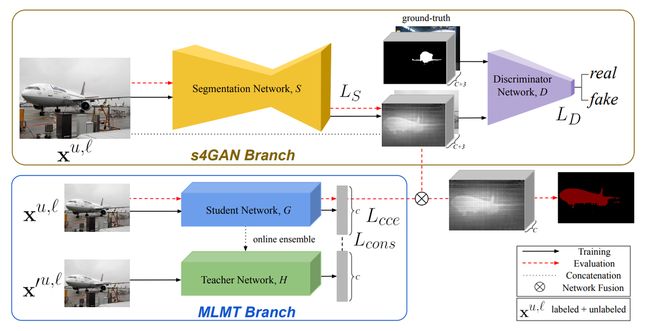 s4GAN[2] 的核心是一个标准的分割网络,用于生成输入图像的每个像素的类标签。同时将将传统的监督训练与对抗训练相结合,利用未标记的数据来提高预测质量。其中,分割网络作为生成器,并与一个判别器一起训练,判别器负责将ground truth与预测的分割图进行区分。此外,文中将判别器的输出作为质量度量来确定预测的质量,从而进一步用于自训练。
s4GAN[2] 的核心是一个标准的分割网络,用于生成输入图像的每个像素的类标签。同时将将传统的监督训练与对抗训练相结合,利用未标记的数据来提高预测质量。其中,分割网络作为生成器,并与一个判别器一起训练,判别器负责将ground truth与预测的分割图进行区分。此外,文中将判别器的输出作为质量度量来确定预测的质量,从而进一步用于自训练。
参考文献:
[1]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency. (TPAMI 21)
[2]Semi Supervised Semantic Segmentation Using Generative Adversarial Network. (ICCV 17)
总结
上文总结了深度半监督语义分割的任务设定、主要挑战和主流的技术手段。总结起来,数据增强、迁移学习和课程学习等方法能够缓解过拟合到少量带标注样本的问题,自监督学习、自训练、一致性正则、协同训练和对抗训练则提供了利用无监督样本的方法。