数据预处理、数据工程 + 代码
导言
数据预处理关注的问题:
- 缺失值,异常值,重复值,空值(空字符串/空格)
- 数据分布问题:正态化变化
- 数据量均衡问题:重采样(上下采样)
- 数据大小问题:数据降温,特征选择
- 模型训练需要数据:特征缩放,特征转换
数据分布不均衡
调整原始分布趋于正态分布
1. 原因
单变量正态性虽然不能保证多变量的正态性,但是它是有帮助的。并且一般解决了正态性问题的话,就可以解决异方差或者线性度的问题。而且很多模型假设数据服从正态分布后,它的样本均值和方差就相互独立,这样就能更好的进行统计推断和假设验证。
2. 如何调整
数据右偏的话可以对所有数据取对数、取平方根等,它的原理是因为这样的变换的导数是逐渐减小的,也就是说它的增速逐渐减缓,所以就可以把大的数据向左移,使数据接近正态分布。 如果左偏的话可以取相反数转化为右偏的情况。
通常来说,可以尝试一下几种方法:
- 如果数据高度偏态,则使用对数变换
对数变换 即将原始数据X的对数值作为新的分布数据:x = np.log(x)
当原始数据中有小值及零时,x = np.log1p(x)
- 如果数据轻度偏态,则使用平方根变换
平方根变换 即将原始数据X的平方根作为新的分布数据 x = np.sqrt(x)
- 如果数据的两端波动较大,则使用倒数变换
倒数变换 x= 1/x 即将原始数据X的倒数作为新的分析数据
数据预处理—4.为什么要趋近于正态分布?详解_哎呦-_-不错的博客-CSDN博客_为什么数据要符合正态分布
2.1 Box-Cox变换
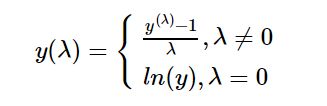
上面公式中y(λ)表示变换后的值,根据λ的值不同,属于不同的变换,当λ值取以下特定的几个值时就变成了特殊的数据变换:
- 当λ=0时,Box-Cox变换就变成了对数变换,y(λ) = ln(y);
- 当λ=0.5时,Box-Cox变换就变成了平方根变换,y(λ) = y^1/2
- 当λ=1时,Box-Cox变换变换就是它本身,y(λ) = y
- 当λ=2时,Box-Cox变换就变成了平方变化,y(λ) = y^2
- 当λ=-1时,Box-Cox变换就变成了倒数变化,y(λ) = 1/y。
λ值取多少,我们可以利用Python中现成的函数,让函数自动去探索,然后返回给我们最优的值是多少就可以。这个函数就是boxcox_normmax,这个函数用来计算给定的非正态数据对应的最优λ值。另外一个函数boxcox_normplot来查看到底哪种方法计算出来的λ值更可靠
当我们得到最优的λ值以后,就可以根据λ值进行数据转换了,这个时候可以用另外的一个函数boxcox,这个函数是根据指定的λ值对原始数据进行转换。
3. 对抗性验证 Adversarial Validation
检测训练集和测试集数据是否来自同一数据(数据分布情况是否相同)
将训练集和测试集分别打上不同的标签然后进行训练,假设使用AUC作为分类精度评价函数:
- 如果分类模型无法分辨样本(AUC接近0.5),则说明训练集和测试集数据分布比较一致;
- 如果分类模型可以很好分辨样本(AUC接近1),则说明训练集和测试集数据分布不太一致;
如果不一致,
- 假设Adversarial Validation的AUC非常高,可以尝试使用Adversarial Validation选择出与测试集比较相似的样本,构建成为验证集。
- 假设数据集可以扩增,则可以使用外部数据来扩增训练数据,以保证训练数据与测试数据的一致性。
数据量不均衡问题
修正方法
0. 合适的评估方法
1. 対训练数据集重新采样
- 欠采样
- 过采样:重复,自助抽样或者SMOTE
SMOTE:该基于距离度量选择小类别下两个或者更多的相似样本,然后选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声,每次处理一个属性。这样就构造了更多的新生数据。(优点是相当于合理地对小样本的分类平面进行的一定程度的外扩;也相当于对小类错分进行加权惩罚
2. 集成不同的重新采样的数据集
最简单的泛化模型的方法就是使用更多的数据。问题在于像逻辑回归和随机森林的分类器趋向于在泛化的时候忽略掉少数类。一个简单的最佳实践是使用所有的少数类和n个不同的多数类组成n个不同的数据集,构建模型。
3. 对多数类进行聚类 (欠采样)
设小类中有N个样本。将大类聚类成N个簇,然后使用每个簇的中心组成大类中的N个样本,加上小类中所有的样本进行训练。(优点是保留了大类在特征空间的分布特性,又降低了大类数据的数目)
4. 对小类错分进行加权惩罚
对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集)。 一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
对小样本进行过采样(例如含L倍的重复数据),其实在计算小样本错分cost functions时会累加L倍的惩罚分数。
Python代码
SMOTE
Synthetic Minority Oversampling Technique
SMOTE是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General)。
SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中
数据降维
1. SGD分解
奇异值分解矩阵
2. PCA主成分分析
数据方差最大方向
3. 因子分析
4. 流形学习
通过映射变换将每个数据点映射到相应的概率分布上。具体的是,在高维空间中使用高斯分布将距离转换为概率分布,在低维空间中,使用长尾分布来将距离转换为概率分布,从而是的高维度空间中的中低等距离在映射后能够有个较大的距离,使得降维时能够避免过多关注局部特征,而忽视全局特征。
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris,load_digits
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
%config InlineBackend.figure_format = "svg"
digits = load_digits()
X_tsne = TSNE(n_components=2, random_state=33).fit_transform(digits.data)
X_pca = PCA(n_components=2).fit_transform(digits.data)
font = {"color": "darkred",
"size": 13,
"family" : "serif"}
plt.style.use("dark_background")
plt.figure(figsize=(8.5, 4))
plt.subplot(1, 2, 1)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10))
plt.title("t-SNE", fontdict=font)
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value', fontdict=font)
plt.clim(-0.5, 9.5)
plt.subplot(1, 2, 2)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10))
plt.title("PCA", fontdict=font)
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value', fontdict=font)
plt.clim(-0.5, 9.5)
plt.tight_layout()
特征选择
1. 过滤法:使用发散性或相关性指标对各个特征进行评分,选择分数大于阈值的特征或者选择前K个分数最大的特征。
方差选择法(发散性),卡方检验法(相关性),皮尔森相关系数法法(相关性),互信息系数法(相关性)
2. 封装法Wrapper:根据⽬标函数(通常是预测效果评分),每次选择若⼲特征,或者排除若⼲特征,即重复执行的嵌入法
RFE递归特征消除法
3. 嵌入法Embedded:先使⽤某些机器学习的算法和模型进⾏训练,得到各个特征的权值系数,根据系数从⼤到⼩选择特征
特征缩放
1. 作用
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度。
2. 类型
- 缩放到均值为0,方差为1(Standardization——StandardScaler())
- 缩放到0和1之间(Standardization——MinMaxScaler())
- 缩放到-1和1之间(Standardization——MaxAbsScaler())
- 缩放到0和1之间,保留原始数据的分布(Normalization——Normalizer())
- 缩放离群值的数据,若数据中存在很大的异常值,可能会影响特征的平均值和方差,影响标准化结果。在此种情况下,使用中位数和四分位数间距进行缩放会更有效:RobustScaler()
- 稀疏数据的缩放,用特征的值除以该特征的最大值:MaxAbsScaler()
- 二值化,Binarizer()
- 独热编码,OneHotEncoder()
3. 公式
3.1 StandardScale 标准缩放(Z 分数标准化)

3.2 MinMaxScaler(按数值范围缩放)
假设我们要缩放的特征数值范围为 (a, b)。

3.3 Normalizer
Normalizer使用L1或者L2范数来缩放数据,默认值为L2。Normalizer计算方法是:除以L1或者L2范数。(axis=1对行计算)
 (L2范数)
(L2范数)
3.4 RobustScaler(抗异常值缩放)
使用对异常值稳健的统计(分位数)来缩放特征。假设我们要将缩放的特征分位数范围为 (a, b)。
 或者
或者 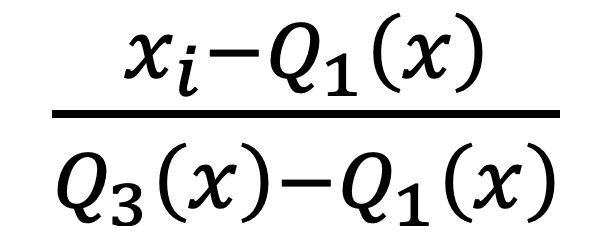
3.5 MaxAbsScaler
X_scaled = X/X.max(X.abs(X), axis=0)
X.abs(X)取特征列的绝对值,X.max(axis=0)为当前特征列的最大值。实际就是除以绝对值的最大值
4. 代码
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MaxAbsScaler
from sklearn.preprocessing import Binarizer
StandardScaler().fit_transform(x)
Binarizer(threshold= 0.9).transform(x)特征转换
- One-hot独热编码
- LabelEncoder 标签编码
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
#独热编码
enc = OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
enc.transform([[0, 1, 3]]).toarray() # 进行编码
#标签编码
le = LabelEncoder()
le.fit([1,5,67,100])
le.transform([1,1,100,67,5])缺失值处理
tricks:
- 30%以上值缺失则抛弃该列
- 数据偏移考虑用中位数替换缺失值
- 填充缺失值,并用额外的列指明数据发生缺失
1. 填充(imputation)
- 热卡填充(hot deck imputation)即就近补齐
这种⽅法简单的通过⼀些现有的相似数据来补充缺失数据。最常见的是使用相关系数矩阵来确定哪个变量(如变量Y)与缺失值所在变量(如变量X)最相关。然后把所有个案按Y的取值大小进行排序。那么变量X的缺失值就可以用排在缺失值前的那个个案的数据来代替了。
- 均值、众数、中位数补齐
⽤现有数据的均值或众数来填充缺失数据。
- 回归补齐(regression imputation)
先依据已知数据建⽴⼀个回归模型,再通过回归模型预测缺失数据。
异常值处理
1. 判断异常值
1.1 3σ原则
1.2 箱形图
超过上下界的值称为异常值
上界 =上四分位数 + k(上四分位数 - 下四分位数)
下界 =下四分位数 - k(上四分位数 - 下四分位数)

当k=1.5时表示中度异常;当k=3时表示高度异常。箱形图中默认k=1.5。
空字符串/空格字符
Python中的空值有None、NaN、""、“ ”四种类型
None 是字符串类型的空值,只有None是NoneType型的。NaN 是数值型的空值。“” 是一个空字符串。“ “是一个还有一个或多个空格的字符串。
1. dataframe
- 检查是否空格: data.price.str.isspace()
- 去除字符前后空格:data.name.str.strip()
- 找出空格或空字符并替换:df.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)
2. read_csv / read_excel
read_csv('data.csv', na_values='', engine='xlrd')
- 如果我们想要补充一些自定义的等同于缺失的值,就可以给na_values参数传值。它接受的数据类型有标量(数字),字符串,列表类的,字典。
- engine:解析引擎;可以接受的参数有"xlrd"、"openpyxl"、"odf"、"pyxlsb",用于使用第三方的库去解析excel文件。默认"xlrd"
- “xlrd”支持旧式 Excel 文件 (.xls)
- “openpyxl”支持更新的 Excel 文件格式
- “odf”支持 OpenDocument 文件格式(.odf、.ods、.odt)
- “pyxlsb”支持二进制 Excel 文件
References
解决样本不平衡问题的奇技淫巧 汇总_songhk0209的博客-CSDN博客
标准化和归一化有什么区别?
专栏 | 基于 Jupyter 的特征工程手册:数据预处理(一) - 知乎