Go 学习之爬虫(抓取动态页面)
文章目录
- 1 | 参考
- 2 | 构建
-
- 2.1 | 首先获得想要的 html 元素
- 2.2 | 获取动态 html 页面
- 2.3 | 解析 html 数据
- 2.4 | main 函数
- 2.5 | 完整代码
1 | 参考
-
Golang+chromedp+goquery 简单爬取动态数据
-
golang goquery selector(选择器) 示例大全 飞雪无情
-
excelize —— go 的 excel 库文档说明
-
go读写excel文件
-
HTML DOM querySelector() 方法
-
goquery 库 github
-
web页面中快速找到html对应元素两种
2 | 构建
- 目标抓取网站的每日一句:http://news.iciba.com/
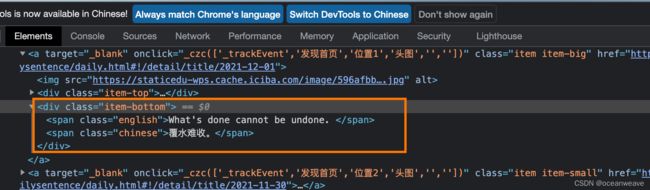
2.1 | 首先获得想要的 html 元素
- F12 —> 左下角箭头处(下面选择Elements标签页) —> 选中网页中元素点击(就会自动跳转)—> 选中位置右键 copy selector
2.2 | 获取动态 html 页面
- 静态页面,一次性获得
- 动态元素,页面有些会后加载,无法一次性获得,因此本次分析这种形式
// 获取网站上爬取的数据
// htmlContent 是上面的 html 页面信息,selector 是我们第一步获取的 selector
func GetHttpHtmlContent(url string, selector string, sel interface{}) (string, error) {
options := []chromedp.ExecAllocatorOption{
chromedp.Flag("headless", true), // debug使用
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36`),
}
//初始化参数,先传一个空的数据
options = append(chromedp.DefaultExecAllocatorOptions[:], options...)
c, _ := chromedp.NewExecAllocator(context.Background(), options...)
// create context
chromeCtx, cancel := chromedp.NewContext(c, chromedp.WithLogf(log.Printf))
// 执行一个空task, 用提前创建Chrome实例
_ = chromedp.Run(chromeCtx, make([]chromedp.Action, 0, 1)...)
//创建一个上下文,超时时间为40s 此时间可做更改 调整等待页面加载时间
timeoutCtx, cancel := context.WithTimeout(chromeCtx, 40*time.Second)
defer cancel()
var htmlContent string
err := chromedp.Run(timeoutCtx,
chromedp.Navigate(url),
chromedp.WaitVisible(selector),
chromedp.OuterHTML(sel, &htmlContent, chromedp.ByJSPath),
)
if err != nil {
//log.Fatal("Run err : %v\n", err)
return "", err
}
//log.Println(htmlContent)
return htmlContent, nil
}
2.3 | 解析 html 数据
- 采用了 goquery 这个库, go get github.com/PuerkitoBio/goquery
// 得到具体的数据
// 就是对上面的 html 进行解析,提取我们想要的数据
// 这个 seletor 是在解析后的页面上,定位要哪部分数据
// 要中文 selector 就可以传入 “.chinese” 对应 上面class chinese 部分
// 中英都要,就传入“.item-bottom"
func GetSpecialData(htmlContent string, selector string) (string, error) {
dom, err := goquery.NewDocumentFromReader(strings.NewReader(htmlContent))
if err != nil {
log.Fatal(err)
return "", err
}
var str string
dom.Find(selector).Each(func(i int, selection *goquery.Selection) {
str = selection.Text()
})
return str, nil
}
2.4 | main 函数
func main() {
selector := "body > div > div.banner > div.swiper-container-place > div > div.swiper-slide.swiper-slide-0.swiper-slide-visible.swiper-slide-active > a.item.item-big > div.item-bottom"
// html 知识 可参考上面链接
param := `document.querySelector("body")`
html, _ := GetHttpHtmlContent(url, selector, param)
// 中英都要,就传入“.item-bottom"
res, _ := GetSpecialData(html, ".item-bottom")
fmt.Println(res)
return
}
2.5 | 完整代码
package main
// 库不全的话 自己补充 go get
import (
"context"
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/chromedp/chromedp"
"log"
)
// 获取网站上爬取的数据
// htmlContent 是上面的 html 页面信息,selector 是我们第一步获取的 selector
func GetHttpHtmlContent(url string, selector string, sel interface{}) (string, error) {
options := []chromedp.ExecAllocatorOption{
chromedp.Flag("headless", true), // debug使用
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36`),
}
//初始化参数,先传一个空的数据
options = append(chromedp.DefaultExecAllocatorOptions[:], options...)
c, _ := chromedp.NewExecAllocator(context.Background(), options...)
// create context
chromeCtx, cancel := chromedp.NewContext(c, chromedp.WithLogf(log.Printf))
// 执行一个空task, 用提前创建Chrome实例
_ = chromedp.Run(chromeCtx, make([]chromedp.Action, 0, 1)...)
//创建一个上下文,超时时间为40s 此时间可做更改 调整等待页面加载时间
timeoutCtx, cancel := context.WithTimeout(chromeCtx, 40*time.Second)
defer cancel()
var htmlContent string
err := chromedp.Run(timeoutCtx,
chromedp.Navigate(url),
chromedp.WaitVisible(selector),
chromedp.OuterHTML(sel, &htmlContent, chromedp.ByJSPath),
)
if err != nil {
//log.Fatal("Run err : %v\n", err)
return "", err
}
//log.Println(htmlContent)
return htmlContent, nil
}
// 得到具体的数据
// 就是对上面的 html 进行解析,提取我们想要的数据
// 这个 seletor 是在解析后的页面上,定位要哪部分数据
// 要中文 selector 就可以传入 “.chinese” 对应 上面class chinese 部分
// 中英都要,就传入“.item-bottom"
func GetSpecialData(htmlContent string, selector string) (string, error) {
dom, err := goquery.NewDocumentFromReader(strings.NewReader(htmlContent))
if err != nil {
log.Fatal(err)
return "", err
}
var str string
dom.Find(selector).Each(func(i int, selection *goquery.Selection) {
str = selection.Text()
})
return str, nil
}
func main() {
selector := "body > div > div.banner > div.swiper-container-place > div > div.swiper-slide.swiper-slide-0.swiper-slide-visible.swiper-slide-active > a.item.item-big > div.item-bottom"
// html 知识 可参考上面链接
param := `document.querySelector("body")`
html, _ := GetHttpHtmlContent(url, selector, param)
// 中英都要,就传入“.item-bottom"
res, _ := GetSpecialData(html, ".item-bottom")
fmt.Println(res)
return
}