Pytorch动手实现Transformer机器翻译

Pytorch动手实现Transformer机器翻译
- 前言
- 一、环境配置
-
- 1. torchtext
-
- Method1:
- Method2:
- 2. Spacy
-
- 以en包下载为例:
- 手动安装语言包到spacy
- 3. NLTK
-
- Method1:
- Method2:
- 二、项目源码
-
- 1. 纠错
- 2. github源码项目
- 三、运行结果
-
- 1. 模型训练(train)
- 2. 翻译推理(inference)
- 总结
- 参考网站
前言
书接上回,光从实现Transformer模型from scratch似乎有点僵硬,毕竟模型不跑起来或者不能应用起来就是一堆“死代码”,为了让读者从上一篇文章中Pytorch从零开始实现Transformer (from scratch)学习后能体验一下Transformer的强大之处,于是有了这篇博客。因为Transformer早先就是谷歌团队为了解决机器翻译等NLP问题而提出的,Transformer天然适用于NLP领域,因此使用Transformer进行机器翻译的应用是最直接的(其实就是本人也一直想玩一下NLP的项目)。
由于时间关系首先公布一下环境配置及运行结果。
一、环境配置
源项目为 github.com/SamLynnEvans/Transformer,但其中代码可能因为年代久远,运行会有各种问题,不久后我会公布我的项目源码。
接下来是两个比较特别的库,光是pip install后并没有完事,还需要额外安装里面对应的工具包。
1. torchtext
torchtext的安装是最为值得注意的一环!
Method1:
直接使用pip install torchtext安装
pip install torchtext
如果你的pytorch版本较低,此命令会自动更新pytorch并安装cpu版本,这时会卸载旧的pytorch,安装的新版本pytorch可能会不兼容。慎用!
Method2:
使用conda install -c pytorch torchtext安装
conda install -c pytorch torchtext
推荐尝试一下Method2,而本人的方法是直接在Anaconda虚拟环境中直接用Method1,因为是实验室电脑所以不想污染base基础环境就自建一个虚拟环境方便操作。
2. Spacy
spacy号称工业级Python自然语言处理(NLP)软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
Spacy的安装没有什么要注意的,就直接pip install安装就好。
pip install spacy
而本文需要用到英语(en)和法语(fr)两个工具包,所以需要在Spacy额外下载。一种比较快的方法是直接从官网安装英语和法语的工具包,然后再手动pip install 到spacy里面,这种方法的优点就是速度更快,更容易控制。
给出下载en和fr语言包的网站:
https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-3.5.0
https://github.com/explosion/spacy-models/releases/tag/fr_core_news_sm-3.5.0
Tip:github网站可能需要科学上网才能更加流畅地加载出来。(本项目源码发布的时候会带有这些文件,读者如果需要复现请不用担心资源不足)
以en包下载为例:
进入网址https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-3.5.0
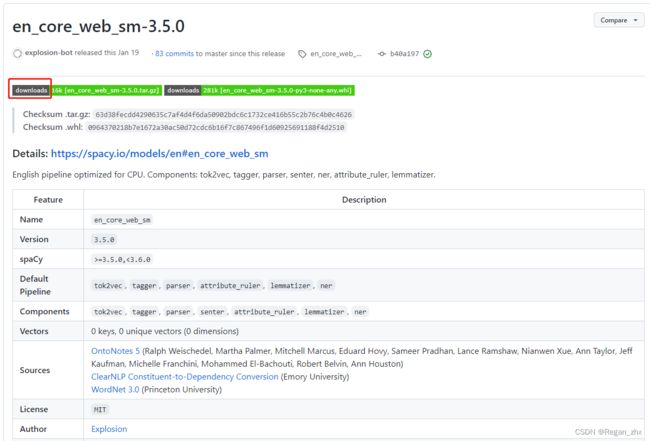
然后点击上图红框的download即可下载。
手动安装语言包到spacy
方法也很简单,到下载的语言包目录下进入Terminal终端小黑窗(windows下是cmd),输入pip install *******.tar.gz 安装即可。语言包会自动下载到spacy库中。
3. NLTK
如果读者的环境中没有nltk,请先:
pip install nltk
源代码这部分使用了nltk中的wordnet包,如果没有这个包也是需要下载的。
Method1:
可视化安装,随便进入一个python的控制台界面,输入
import nltk
nltk.download()
不出意外会出现如下弹出如下窗口:
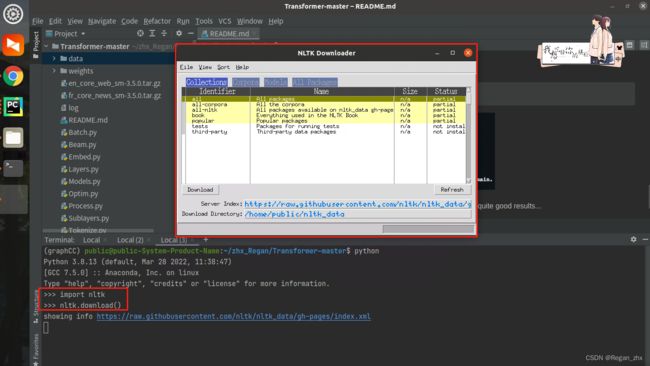
然后如下图点击Corpora然后下拉滚动条找到wordnet并点击“download”。如果网络好的话会看到右下角蓝框处的红色进度条不断增长。

不过这个方法一般比较慢,由于网速不太能安装好。
Method2:
直接去官网找到zip包直接下载,从根源解决问题。
进入网址http://www.nltk.org/nltk_data/
“Ctrl+F”搜索“id: wordnet”(请注意冒号后有个空格),会出现好几个搜索结果,选择如下图所示这个wordnet进行下载:

如果下载时候文件显示10.3MB那就证明下载正确了!
然后将下载好的wordnet.zip放到读者电脑所在nltk_data/corpora目录下即可。如果不知道nltk_data在哪里,可以在python里输入如下命令就会出现所有nltk_data路径了。
import nltk
nltk.download("wordnet")

二、项目源码
1. 纠错
在Pytorch从零开始实现Transformer (from scratch)一文中的问题答案就是:Multi-Head Attention部分的代码是有些欠妥的。而本项目的源码如下,大家可以和原本的代码进行对比。
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
"""
============================================
问题所在之处
"""
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
"""
============================================
"""
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# perform linear operation and split into N heads
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# transpose to get dimensions bs * N * sl * d_model
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2)
# calculate attention using function we will define next
scores = attention(q, k, v, self.d_k, mask, self.dropout)
# concatenate heads and put through final linear layer
concat = scores.transpose(1,2).contiguous()\
.view(bs, -1, self.d_model)
output = self.out(concat)
return output
2. github源码项目
可运行的项目已于 2023.4.8.1:00 发布到github,源码链接为https://github.com/Regan-Zhang/Transformer-Translation
已训练好的模型权重由于有300M之大,就不上传到github了,如果读者有需要请私聊。本人在3060显卡上训练了110epochs。训练过程的log部分记录如下:
(graphCC) public@public-System-Product-Name:~/zhx_Regan/Transformer-master$ python train.py -src_data data/english.txt -trg_data data/french.txt -src_lang en_core_web_sm -trg_lang fr_core_news_sm -epochs 10
loading spacy tokenizers...
creating dataset and iterator...
The `device` argument should be set by using `torch.device` or passing a string as an argument. This behavior will be deprecated soon and currently defaults to cpu.
model weights will be saved every 1 minutes and at end of epoch to directory weights/
training model...
2m: epoch 1 [####################] 100% loss = 3.40303
epoch 1 complete, loss = 3.403
4m: epoch 2 [####################] 100% loss = 2.38484
epoch 2 complete, loss = 2.384
6m: epoch 3 [####################] 100% loss = 1.86363
epoch 3 complete, loss = 1.863
9m: epoch 4 [####################] 100% loss = 1.56969
epoch 4 complete, loss = 1.569
11m: epoch 5 [####################] 100% loss = 1.44242
epoch 5 complete, loss = 1.442
13m: epoch 6 [####################] 100% loss = 1.21919
epoch 6 complete, loss = 1.219
15m: epoch 7 [####################] 100% loss = 1.19595
epoch 7 complete, loss = 1.195
18m: epoch 8 [####################] 100% loss = 1.04545
epoch 8 complete, loss = 1.045
20m: epoch 9 [####################] 100% loss = 1.01818
epoch 9 complete, loss = 1.018
22m: epoch 10 [####################] 100% loss = 0.94545
"""......"""
204m: epoch 97 [####################] 100% loss = 0.28888
epoch 97 complete, loss = 0.288
206m: epoch 98 [####################] 100% loss = 0.27474
epoch 98 complete, loss = 0.274
208m: epoch 99 [####################] 100% loss = 0.27373
epoch 99 complete, loss = 0.273
210m: epoch 100 [####################] 100% loss = 0.28787
epoch 100 complete, loss = 0.287
training complete, save results? [y/n] : y
command not recognised, enter y or n : y
saving weights to weights/...
weights and field pickles saved to weights
train for more epochs? [y/n] : n
exiting program...
详细记录请参考github项目中的log.txt文件。
三、运行结果
1. 模型训练(train)
打开终端,输入命令即可训练Transformer用于英语翻译为法语的机器翻译任务。
python train.py -src_data data/english.txt -trg_data data/french.txt -src_lang en_core_web_sm -trg_lang fr_core_news_sm -epochs 10
即指定english.txt和french.txt语料(随项目代码提供),先训练个10epochs。原项目中用一张8GB显存的K100来跑,本文使用的是英伟达3060(显存12G),因此训练绰绰有余。10epochs一个小时内就能训练完吧。
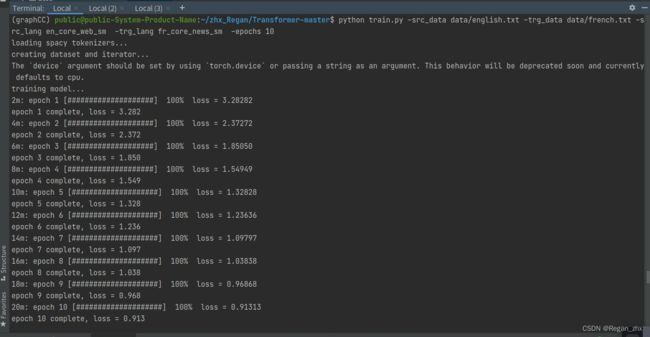
2. 翻译推理(inference)
训练完模型之后加载所保存的目录,此处为weights,其实也是训练时指定好的路径了。
python translate.py -load_weights weights -src_lang en_core_web_sm -trg_lang fr_core_news_sm

红框为输入的英文,篮框为模型翻译出的法语。
尽管我们可能看不懂法语,但是可以将法语交给现成翻译器让其翻译成中文。
我是一名研究生。
你为什么喜欢读书科学?
这是我学了四年的学校。——“有道翻译”
大概看得出翻译的还算有模有样,可以翻译得出where后置定语从句,那证明Transformer对机器翻译方面是一个可行的模型。
总结
目前本博客所体现的是比较表层的一部分,旨在引发大家对Transformer等深度学习模型学习的兴趣(同时也是激发我自己对学习的动力)。学习完模型后,将自己实现的模型用来做出一个可运行的demo或者应用,不仅能加深记忆还能像连锁反应一样触发更多知识点的学习,提高知识面的广度和认知深度。
参考网站
https://github.com/SamLynnEvans/Transformer
【Pytorch】torchtext终极安装方法及常见问题
PYTHON -M SPACY DOWMLOAD EN失败
离线安装NLTK工具包