Golang源码探究 —— 网络轮询器netpoller
目录
-
- 一、Linux网络编程基础知识
-
- 1.1 socket编程
- 1.2 三次握手
- 二、网络I/O模型
-
- 2.1 阻塞I/O模型
- 2.2 非阻塞I/O模型
- 2.3 I/O多路复用
- 2.4 信号驱动I/O
- 2.5 异步I/O
- 三、Go网络轮询器netpoller
-
- 3.1 Go网络编程常用模式
- 3.2 Go网络编程架构
- 3.3 netpoller
-
- 3.3.1 netpoll epoll实现
-
- 变量定义:
- 初始化netpoller:netpollinit
- 注册fd事件监听:netpollopen
- 删除fd事件监听:netpollclose
- 定期轮询:netpoll
- netpollBreak
- netpollIsPollDescriptor
- 3.3.2 netpollinit的调用时机
-
- poll.pollDesc
- 3.4 net包底层实现
-
- 3.4.1创建监听器(Listen)和接受新连接(Accept)
-
- net.Listen
- TcpListener.AcceptTCP()
- 3.4.2 conn读写操作
-
- conn.Read
- conn.Write
- 3.4.3 关闭连接
-
- conn.Close
- 3.5 定期轮询netpoll是在哪里被调用的
网络通信是服务端程序必不可少也是至关重要的一部分,基于TCP Socket的通信则是网络编程的主流。TCP Socket是最常见的网络编程,在POSIX标准发布后,Socket得到了各大主流操作系统平台很好的支持。
Go是自带运行时的跨平台编程语言,Go的net包中暴露给开发者的Socket也是建立在操作系统原生socket接口之上的。netpoller是Go语言用来屏蔽各个操作系统底层高效I/O多路复用的网络轮询器,它屏蔽了各个操作系统底层不同而且复杂的I/O多路复用的使用,在上层为我们提供最简单最容易理解的阻塞I/O的编程方式,在使用时我们只需要一个协程对应一个连接的读写操作即可。
在讲解netpoller的实现之前,需要对linux网络编程以及网络I/O模型有一个清晰的了解,这样才能让我们更容易地去理解netpoller的实现。
一、Linux网络编程基础知识
1.1 socket编程
我们可能学习过很多计算机网络相关的知识,TCP、UDP、三次握手、四次挥手等。但是在实践中,我们编写网络应用离不开socket编程,因此在本章中主要介绍一下socket编程。最基础的socket编程也就是两个流程,在合适的时候调用合适的系统调用,下面是最基础的阻塞式的客户端-服务端socket编程:

下面是这些系统调用的作用:
- socket:创建socket,获取一个文件描述符fd,后续的操作都需要这个fd。
- connect:客户端发起请求进行三次握手连接服务端。
- bind:绑定端口和IP地址。
- listen:监听客户端的连接。
- accept:接收已经完成三次握手的客户端连接,并获取客户端fd,后续收发数据都会使用这个fd。
- read:接收数据。
- write:发送数据。
- close:关闭连接。
下面是linux c编写的回射服务器,服务端将客户端发来的消息转化为大写后发送回去。
#include \n" , argv[0]);
return 0;
}
int port = atoi(argv[1]);
// 1.创建socket
int fd = socket(AF_INET, SOCK_STREAM, 0);
err_exit(fd, "create socket");
// 2.bind addr
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port);
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
err_exit(ret, "bind");
// 3.调用listen开启监听
ret = listen(fd, 128);
err_exit(ret, "listen");
struct sockaddr_in cli_addr; // 客户端地址
socklen_t sock_len = sizeof(cli_addr);
int cfd; // 客户端文件描述符
char addrbuf[32] = {0};
int n;
char buf[1024] = {0};
printf("Waiting for new client...\n");
while (1)
{
// 4. 阻塞接收新的连接
cfd = accept(fd, (struct sockaddr *)&cli_addr, &sock_len);
if (cfd < 0) {
printf("accept error:%s\n", strerror(errno));
continue;
}
printf("Received new connection, ip:%s port:%d\n",
inet_ntop(AF_INET, &cli_addr.sin_addr, addrbuf, sizeof(addrbuf)), ntohs(cli_addr.sin_port));
// 5.阻塞读取数据
n = read(cfd, buf, sizeof(buf));
if (n < 0) { // 发生错误
printf("read error:%s\n", strerror(errno));
close(cfd);
continue;
} else if (n == 0) { // 客户端关闭了连接
printf("remote connection has been closed by client\n");
close(cfd);
continue;
}
// 6.转换为大写
for (int i = 0; i < n; i++) {
buf[i] = toUpper(buf[i]);
}
// 7.发送数据
write(cfd, buf, n);
// 8.关闭连接
close(cfd);
}
return 0;
}
char toUpper(char c) {
if (c >= 'a' && c <= 'z') {
return c - 32;
}
return c;
}
void err_exit(int n, const char *msg) {
if (n < 0) {
printf("%s error, reason:%s\n", msg, strerror(errno));
exit(1);
}
}
1.2 三次握手
我们在按着这个流程编写网络应用时很简单,但是在服务端开启和客户端建立连接的过程中各个系统调用的作用是什么呢,我们需要了解一下。
首先抛出一个问题:有没有想过为什么服务端为都要listen一下,它的作用是什么?
如下图所示为socket编程中三次握手发生的流程图:
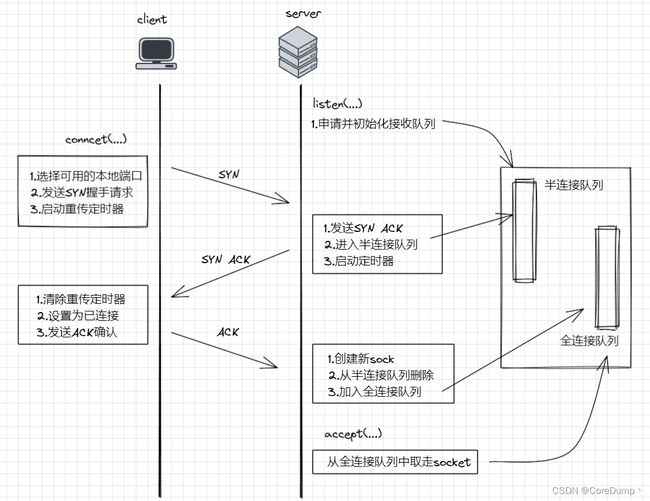
listen:主要工作就是申请和初始化接受队列,包括半连接队列和全连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速查找,所以使用的是一个哈希表。connect:客户端在调用connect的时候,会将本地socket状态设置为TCP_SYN_SENT,选择一个可用的端口,接着发出SYN握手请求并启动重传定时器。服务端响应SYN:判断接受队列是否满了,满的话可能会丢弃该请求,否则发出SYN ACK。然后将该连接加入半连接队列中,启动重传定时器。客户端响应SYN ACK:响应服务端的SYN ACK时清除了connect时设置的重传定时器,将当前socket状态设置为ESTABLISHED,开启保活计时器后发出第三次握手的ACK确认。服务端收到ACK:服务端处理第三次握手ACK所做的工作是把当前半连接对象从半连接队列中删除,创建了新的sock后加入全连接队列,最后将新连接状态设置为ESTABLISHED。accept:accept的工作主要就是从已经建立好的全连接队列中取出一个返回给用户进程。
结论:服务端listen的作用是因为在调用listen时候在内核中创建了半连接和全连接队列,这两个队列是三次握手中很重要的数据结构,有了它们服务端才能正常响应来自客户端的三次握手。所以服务端提供服务前都需要先调用listen才行。
二、网络I/O模型
操作系统网络I/O模型包含五种:阻塞I/O、非阻塞I/O、I/O多路复用、信号驱动I/O、异步I/O
网络I/O模型定义的是应用线程与操作系统内核之间的交互行为模式。我们通常用阻塞(Blocking)和非阻塞(Nonblocking)来描述网络I/O模型。但是不同标准对于网络I/O模型的说法有所不同,比如POSIX.1标准还定义了同步(Sync)和异步(Async)这两个术语。

2.1 阻塞I/O模型
阻塞I/O是最常见的模型,也是应用起来最简单、容易理解的的模型。
如下图所示:
我们可以看到,当用户调用例如accept、read等系统调用向内核发起I/O请求后,如果没有数据准备就绪,内核就会挂起当前的线程,直到数据准备就绪后,将数据从内核空间拷贝到进程空间。在此期间,应用线程处于阻塞状态。
阻塞I/O是非常容易理解的,因为我们不知道用户什么时候会发来数据,因此就要一直等着,用户发送了数据,我们才能接收数据。
举个例子,阻塞I/O就像这样一种场景:假如你在淘宝上买了一件商品,然后你就直接跑到快递点问你的快递有没有到,老板告诉你还没到,然后你就一直在那傻傻地等着,直到快递到了之后,才拿着快递回去了。
如果我们在单线程的应用服务器中使用这种方式,那么每次只能对一个客户进行服务,因为在接收了一个客户的连接后,就要阻塞读取数据,那么将不能处理其它客户的请求。效率非常低,因此在实际的服务器中并不会仅使用这种方式。虽然该模型对应用而言整体是非常低效的,但是对开发人员来说,基于该模型开发网络通信却最容易的。

阻塞I/O模型 + 多线程:
单线程的阻塞模式非常低效,但是这种方式可以配合多线程来进行编程,在accept到一个客户端后,就启动一个新的线程来处理客户的的读写操作, 如下图所示。
例如阿帕奇服务器就是使用这样的方式的。这种方式在并发量不大的情况下效率是非常高的,但是比较占用资源,每个线程都需要2M的栈空间,而且当并发量增大时,就会启动大量的线程,不但占用大量的内存资源,而且频繁的线程切换也会消耗大量的CPU资源。操作系统在启动上千个线程以后,它的效率将会变得非常低,因为大部分的时间都花在了线程切换上。因此我们可以在后面的Go源码中看到,go runtime将启动的线程的最大数量定为了1W。

阻塞I/O + 多线程在linux上的实现代码如下:
在下面的代码中,在接收到一个客户的连接后,我们就会启动一个线程来负责处理客户端的数据读取以及后续的业务处理,这样便可以实现并发的服务器。
#include \n" , argv[0]);
return 0;
}
int port = atoi(argv[1]);
// 1.创建socket
int fd = socket(AF_INET, SOCK_STREAM, 0);
err_exit(fd, "create socket");
// 2.bind addr
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port);
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
err_exit(ret, "bind");
// 3.调用listen开启监听
ret = listen(fd, 128);
err_exit(ret, "listen");
// 4. 阻塞接收新的连接
struct sockaddr_in cli_addr; // 客户端地址
socklen_t sock_len = sizeof(cli_addr);
int *cfd; // 客户端文件描述符
char addrbuf[32] = {0};
pthread_t tid;
printf("Waiting for new client...\n");
while (1)
{
cfd = new int;
// 5. 阻塞接收新的连接
*cfd = accept(fd, (struct sockaddr *)&cli_addr, &sock_len);
if (*cfd < 0) {
printf("accept error:%s\n", strerror(errno));
delete cfd;
continue;
}
// 6. 创建线程来处理客户端请求
pthread_create(&tid, nullptr, &thread_task, (void *)(cfd));
// 7.设置线程分离
pthread_detach(tid);
printf("Received new connection, thread id:%lu, ip:%s port:%d\n", tid,
inet_ntop(AF_INET, &cli_addr.sin_addr, addrbuf, sizeof(addrbuf)), ntohs(cli_addr.sin_port));
}
return 0;
}
// 线程入口函数,用来处理客户端请求
void *thread_task(void *arg) {
int *pfd = (int *) arg;
int fd = *pfd;
delete pfd;
int n;
char buf[1024] = {0};
while(1)
{
// 1.阻塞读取数据
n = read(fd, buf, sizeof(buf));
if (n < 0) { // 发生错误
printf("read error:%s\n", strerror(errno));
// 关闭连接
close(fd);
break ;
} else if (n == 0) { // 客户端关闭了连接
printf("remote connection has been closed by client\n");
close(fd);
break;
}
// 2.转换为大写
for (int i = 0; i < n; i++) {
buf[i] = toUpper(buf[i]);
}
// 3.发送数据
write(fd, buf, n);
}
return nullptr;
}
char toUpper(char c) {
if (c >= 'a' && c <= 'z') {
return c - 32;
}
return c;
}
void err_exit(int n, const char *msg) {
if (n < 0) {
printf("%s error, reason:%s\n", msg, strerror(errno));
exit(1);
}
}
2.2 非阻塞I/O模型
如下图所示:
非阻塞I/O,从它的名字就可以看出它是不会阻塞的,也就是在调用I/O系统调用后,无论数据有没有就绪都要直接返回(如果有数据复制数据然后返回,如果没有数据返回错误码)。
但是由于我们不知道客户端什么时候会发来数据,因此不得不循环调用read系统调用来读取数据,如果没有数据就继续尝试,如果不停地轮询执行系统调用,将会导致CPU资源的浪费。因此也可以先做一些其它的事情或者休眠一段时间再进行尝试。
举个例子:还是在淘宝买东西,但是你这次机灵了一点,你先给快递点打了个电话,然后快递老板告诉你快递没到,然后你挂了电话。但是每过几分钟,你就会给快递点打电话询问,快递点老板都快被你折磨死了。最后,终于老板告诉你快递到了,然后你就去快递点拿着快递走了。
非阻塞I/O的设置也非常简单,我们只需要使用linux提供的fcntl系统调用来设置即可:
// fcntl的函数声明
int fcntl(int fd, int cmd, ... /* arg */ );
// 先获取fd对应的flag,然后再或上非阻塞标志即可
int flag = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
在设置了非阻塞之后,我们再使用accept或者read来读取时,如果没有数据将会返回EAGAIN或者EWOULDBLOCK的错误码,然后我们可以根据该错误码来决定后续怎么处理。
注意:通常我们会在使用I/O多路复用时搭配非阻塞I/O来使用

非阻塞I/O在linux上的实现代码如下:
#include \n" , argv[0]);
return 0;
}
int port = atoi(argv[1]);
// 1.创建socket
int fd = socket(AF_INET, SOCK_STREAM, 0);
err_exit(fd, "create socket");
// 2.bind addr
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port);
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
err_exit(ret, "bind");
// 3.调用listen开启监听
ret = listen(fd, 128);
err_exit(ret, "listen");
// 4. 阻塞接收新的连接
struct sockaddr_in cli_addr; // 客户端地址
socklen_t sock_len = sizeof(cli_addr);
int cfd; // 客户端文件描述符
char addrbuf[32] = {0};
int n;
char buf[1024] = {0};
printf("Waiting for new client...\n");
while (1)
{
// 5. 阻塞接收新的连接
cfd = accept(fd, (struct sockaddr *)&cli_addr, &sock_len);
if (cfd < 0) {
printf("accept error:%s\n", strerror(errno));
continue;
}
printf("Received new connection, ip:%s port:%d\n",
inet_ntop(AF_INET, &cli_addr.sin_addr, addrbuf, sizeof(addrbuf)), ntohs(cli_addr.sin_port));
// 6.设置非阻塞
setNonblocking(cfd);
// 7.轮询读取数据
while(1)
{
n = read(cfd, buf, sizeof(buf));
if (n < 0) {
if ((errno == EAGAIN || errno == EWOULDBLOCK)) {
printf("No data to read\n");
// 休眠1s
sleep(1);
continue;
} else {
printf("read error:%s\n", strerror(errno));
close(cfd);
break;
}
} else if (n == 0) {
printf("remote connection has been closed by client\n");
close(cfd);
break;
}
// 转换为大写
for (int i = 0; i < n; i++) {
buf[i] = toUpper(buf[i]);
}
// 8.发送数据
write(cfd, buf, n);
// 9.关闭连接
close(cfd);
break;
}
}
return 0;
}
// 给对应fd设置为非阻塞
void setNonblocking(int fd) {
int flag = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
}
char toUpper(char c) {
if (c >= 'a' && c <= 'z') {
return c - 32;
}
return c;
}
void err_exit(int n, const char *msg) {
if (n < 0) {
printf("%s error, reason:%s\n", msg, strerror(errno));
exit(1);
}
}
2.3 I/O多路复用
I/O多路复用的思想是:不应该由应用程序自己监视客户端连接,取而代之由内核替应用程序监视客户端连接。
之前我们都是在自己的应用程序中监视客户端的连接,比如要监视客户端的连接建立请求和数据发送,但是它们本质上都是服务端数据的接收。我们可以让内核来监视这些客户端的请求,有新的连接到来或者数据到来,我们只需要询问内核是否有数据到来或者事件发生,然后我们来处理即可。
还是那个例子:但是这次你买了商品后,由快递小哥来接管了这件事,就算你买了很多东西,你也只管在家等着快递小哥的电话就行了,一旦你的快递到了,快递小哥就会给你打电话。然后就可以愉快地去取快递了。
Linux提供了三种I/O多路复用的方式,分别是:select、poll和epoll。
select是POSIX标准规定的I/O多路复用,在大多数的操作系统都有实现比如unix和windows等。对于不同的操作系统,也有其更加高效的实现接口,比如linux下有epoll,mac下有kquque,windows下有IOCP(异步I/O)。在后面Go的netpoller中,我们可以看到Go运行时针对不同的操作系统进行了不同的实现,在编译时会根据操作系统来编译对应的文件。
以下是linux下三种I/O多路复用方式的优缺点:
select:能监听的文件描述符的最大个数为1024,每次调用select时需要将整个fd集合传入,调用返回时内核又需要将修改的数据拷贝回用户fd集合中,涉及两次数据拷贝,效率较低。而且需要我们遍历整个集合来确定活跃的客户端连接,时间复杂度O(n)。poll:相比于select,poll改善了select只能监听1024个文件描述符的限制,其内部使用了链表的设计。但是治标不治本,依然存在数据拷贝和遍历整个集合来获取活跃fd的问题。即使它监听的文件描述符没有上限,但是当连接达到一定的数量级,每次都需要拷贝大量的数据以及遍历集合,那么它的效率是很低的。epoll:能监听的文件描述符个数理论上没有上限(与机器配置大小相关),而且由于底层使用了红黑树来保存需要监听的fd,对于fd的添加、删除和修改更加高效。在每次获取就绪事件列表时无需传入整个fd集合, 而且epoll内部存在一个就绪链表用来存放已经就绪的fd,在获取活跃fd时,epoll会直接返回所有活跃的fd列表,无需遍历整个监听的fd集合。相比于阻塞式I/O,使用epoll可以大幅减少socket阻塞时的进程上下文切换(因为得到事件通知后再去读取数据就不会导致阻塞)。相比于select和poll,它的效率和使用率是最高的。
接下来我们主要介绍linux下的epoll。
epoll是linux下I/O多路复用接口select/poll的增强版本,它能显著提高程序在大量连接中只有少量活跃的情况下的系统CPU的利用率。目前epoll是linux大规模并发网络应用程序的首选,大部分高性能的网络服务器使用的I/O复用模型均是epoll,比如nginx、redis、memcached等。
epoll模型总共有三个API:
// 创建epoll句柄(epoll文件描述符),可以通过返回的epoll句柄来操作epoll
int epoll_create(int size);
// 将文件描述符加入、删除或修改epoll的事件监听,比如监听一个连接的读事件、写事件或者错误事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 向内核查询是否有事件发生
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
-
epoll_create:创建epoll句柄,会在内核中创建一颗红黑树,用来存放要监听的fd和相应事件,每个fd将作为红黑树的一个节点。 -
epoll_ctl:添加、修改或删除epoll监听的fd。第二个参数op支持三种操作:- EPOLL_CTL_ADD: 添加fd和要监视的事件
- EPOLL_CTL_MOD:修改fd和要监视的事件
- EPOLL_CTL_DEL:删除fd和要监视的事件
-
epoll_wait:向内核询问是否有事件发生,最后一个参数timeout如果设置为-1,那么将会是阻塞模式,如果没有事件发生,将会一直阻塞下去直到有事件发生,返回值是发生事件的文件描述符的个数,evnets是一个数组,需要用户创建并传入,发生事件的文件描述符对应的事件将会被放入events数组中,因此只需要遍历数组一个个处理即可。如果timeout被设置为0,就是非阻塞模式,如果没有事件发生,直接返回。如果timeout大于0,那么将会最多等待timeout毫秒。
如下图所示:
epoll的使用步骤如下:
-
首先我们需要使用epoll_create来创建epoll,然后获得epoll句柄(epoll文件描述符)epfd,之后我们就可以通过epfd来操作epoll了。
-
然后使用epoll_ctl来将要内核帮我们监听的文件描述符加入epoll中,同时指定要监听的事件,比如读事件(EPOLLIN)、写事件(EPOLLOUT)(
注意:调用read会阻塞很容易理解,但是调用write时也可能会发生阻塞。因为TCP通信连接两端的操作系统内核都会为该连接保留数据缓冲区,一端调用write后,实际上数据是写入了操作系统协议栈的数据缓冲区中的。TCP是全双工通信,因此每个方向都有独立的数据缓冲区。当发送方将对方的接收缓冲区及自身的发送缓冲区都写满后,write调用就会阻塞)。 -
之后,我们调用epoll_wait来向内核查询是否有事件发生,比如客户端发来了数据,那么epoll_wait就会返回,返回值是发生事件的文件描述符的个数,events数组中存放了发生的事件,然后我们直接遍历events数组来处理即可。如果我们传入的timeout参数小于0,那么在没有数据的情况下,用户线程将会阻塞在epoll_wait系统调用中。如果设置的非负,而且在超时后也没有事件发生,那么epoll_wait将会返回-1,errno的错误码为EAGAIN或者EWOULDBLOCK。

I/O多路复用在linux上的实现如下(使用epoll):
#include \n" , argv[0]);
return 0;
}
int port = atoi(argv[1]);
// 2.获取监听fd
int fd = Listen(port);
// 3.创建epoll
epfd = epoll_create(1024);
err_exit(epfd, "create epoll");
// 4.将server fd设为非阻塞并加入epoll的监听事件中
setNonblocking(fd);
Conn server{
.fd = fd,
.handler = acceptConn
};
// 将监听fd加入到epoll中监听其读事件(新连接到来也是读事件)
epollAddEvent(fd, EPOLLIN, &server);
// 5.调用epoll_wait等待处在epoll监听下的文件描述符有可读事件
int nready;
struct epoll_event events[1024];
while(1)
{
nready = epoll_wait(epfd, events, 1024, -1);
if (nready < 0) {
printf("epoll_wait error:%s\n", strerror(errno));
continue;
}
// 6.处理有读事件发生的fd
for (int i = 0; i < nready; i++) {
if (events[i].events & EPOLLIN) {
Conn *c = (Conn *)(events[i].data.ptr);
// 7.调用回调函数进行处理
c->handler(c);
}
}
}
return 0;
}
// 依次调用socket、bind、listen获取一个监听socket
int Listen(int port) {
// 1.创建socket
int fd = socket(AF_INET, SOCK_STREAM, 0);
err_exit(fd, "create socket");
// 2.bind addr
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(port);
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
err_exit(ret, "bind");
// 3.调用listen开启监听
ret = listen(fd, 128);
err_exit(ret, "listen");
return fd;
}
// 将指定fd和事件加入epoll的监听中
void epollAddEvent(int fd, int event, Conn *conn) {
epoll_event ev;
ev.events = event;
ev.data.ptr = conn; // ev.data是一个联合体,ev.data.ptr是一个void *类型的指针,可以用来存放任何数据的指针
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
}
// 从epoll中删除对应fd的监听
void epollDelEvent(int fd) {
epoll_event ev;
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, &ev);
}
// 接收新的连接,并将连接加入epoll中监听读事件
void acceptConn(Conn *conn) {
struct sockaddr_in cli_addr; // 客户端地址
socklen_t sock_len = sizeof(cli_addr);
int cfd; // 客户端文件描述符
char addrbuf[32] = {0};
// 1.接收新的连接
cfd = accept(conn->fd, (struct sockaddr *)&cli_addr, &sock_len);
if (cfd < 0) {
printf("accept error:%s\n", strerror(errno));
return;
}
printf("Received new connection, ip:%s port:%d\n",
inet_ntop(AF_INET, &cli_addr.sin_addr, addrbuf, sizeof(addrbuf)), ntohs(cli_addr.sin_port));
// 2.将fd设为非阻塞
setNonblocking(cfd);
// 2.将新的连接加入epoll中监听读事件
Conn *c = new Conn;
c->fd = cfd;
c->handler = readData;
epollAddEvent(cfd, EPOLLIN, c);
}
// 读取数据,并转为大写发送给客户端
void readData(Conn *conn) {
int n;
//1. 读取数据
n = read(conn->fd, conn->buf, sizeof(conn->buf));
if (n < 0) { // 发生错误,删除该fd在epoll中的读事件并关闭连接
printf("read error:%s\n", strerror(errno));
closeConn(conn, true);
return;
} else if (n == 0) { // 客户端关闭了连接
printf("remote connection has been closed by client\n");
closeConn(conn, true);
return;
}
// 2.转换为大写
for (int i = 0; i < n; i++) {
conn->buf[i] = toUpper(conn->buf[i]);
}
// 3.发送数据
write(conn->fd, conn->buf, n);
}
// 删除对应fd的epoll监听、关闭连接以及释放资源
void closeConn(Conn *conn, bool free) {
epollDelEvent(conn->fd);
close(conn->fd);
if (conn && free) {
delete conn;
}
}
// 为fd设置非阻塞模式
void setNonblocking(int fd) {
int flag = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
}
char toUpper(char c) {
if (c >= 'a' && c <= 'z') {
return c - 32;
}
return c;
}
void err_exit(int n, const char *msg) {
if (n < 0) {
printf("%s error, reason:%s\n", msg, strerror(errno));
exit(1);
}
}
I/O多路复用的优点:系统不必创建大量的线程来处理客户端,一个网络轮询器就可以处理成千上万的连接,大大减少了系统的开销。
最后,介绍一下epoll的两种模式:
- ET(Edge Triggered):边缘触发模式,当数据到来后epoll_wait会返回,但是如果数据没有读取完,epoll_wait后续也将不再通知。
- LT(Level Triggered):水平触发,如果数据没有读取完,epoll_wait将会持续性通知。
我们在编程时通常使用水平触发的方式,这种方式使用起来更简单。ET是epoll的高速模式,使用起来较为复杂,需要开发者自己把握好数据的读取。Go运行时中netpoller的实现使用的是ET边缘触发的模式。
2.4 信号驱动I/O
使用信号驱动I/O需要我们注册SIGIO信号,并安装一个信号处理函数,进程继续运行并不阻塞。
当数据准备好时,内核就为该进程产生一个 SIGIO 信号。随后信号处理函数会被调用,我们可以在信号处理函数中调用 read 读取数据,并通知主循环数据已准备好待处理,也可以立即通知主循环,让它来读取数据报。无论如何处理 SIGIO 信号,这种模型的优势在于等待数据报到达(第一阶段)期间,进程可以继续执行,不被阻塞。但是这种方式主要在UDP通信中使用,因为内核并不会告诉我们哪个连接有数据可读。
购物例子:在你买了商品后,告诉快递点,一旦快递到了,就给我打电话,然后自己该干嘛干嘛去。快递到了后,快递点打电话通知你,然后再去拿取。

2.5 异步I/O
在异步I/O模型下,用户应用和操作系统内核的交互模式与前几个模型差异较大,如下图所示:
用户线程在发起异步I/O调用后,内核将启动等待数据的操作并马上返回。之后,用户线程可以继续执行其它操作,既无需阻塞,也无需轮询并再次发起I/O调用。当数据准备就绪后,内核负责将数据从内核空间拷贝到用户空间,内核会主动生成信号以驱动执行用户线程在异步I/O调用时注册的信号处理函数,或主动执行用户线程注册的回调函数。
购物例子:这次就更方便了,买了东西后,你告诉快递点,东西到了直接给我送过来就行。

三、Go网络轮询器netpoller
伴随着网络模型的演进,服务器的愈发强大,可以支持更多的连接,获得更好的处理性能。目前主流网络服务器采用的多是I/O多路复用的模型(unix)。有的使用单进程单线程的方式,比如早期的redis;有的则是多进程的方式,比如nginx;还有单进程多线程的方式。但是I/O多路复用模型在支持更多连接、提升I/O操作效率的同时,也给使用者带来了不低的复杂性,熟悉linux C/C++网络编程的开发者深有体会。虽然有很多高性能的I/O多路复用框架,比如libevent、libev等,但是在做这样的网络应用开发时也有不小的心智负担。
Go语言的设计者们认为I/O多路复用的这种通过回调割裂控制流的模型依旧很复杂。而且有悖于一般顺序程序的设计逻辑,为此他们结合Go语言的自身特点,将该复杂性隐藏在了Go的运行时中。在运行时中将各个操作系统底层高效I/O多路复用模型抽象和封装为了一个netpoller,结合Go语言最强大的goroutine,为我们上层开发提供了最简单易用的阻塞开发方式。可以让我们在进行网络编程的时候,使用一个goroutine对应一个conn的阻塞读写操作,也就是阻塞I/O模型 + goroutine的方式,大大降低了网络开发人员的心智负担。
虽然Go语言设计者已经为我们提供了简单的网络编程方式,但是还是有必要去了解一下runtime底层的实现,对于我们开发网络应用程序有更大的帮助。
3.1 Go网络编程常用模式
一个Go语言编写的回射服务端大致如下:
package main
import (
"bytes"
"errors"
"fmt"
"io"
"net"
)
func main() {
// 1.创建监听器
listener, err := net.Listen("tcp", ":8888")
if err != nil {
panic(err)
}
for {
// 2.接收新的连接
conn, err := listener.Accept()
if err != nil {
fmt.Println("Accept error:", err)
continue
}
// 3.启动一个协程来处理连接
go dealConn(conn)
}
}
// 处理客户端连接
func dealConn(conn net.Conn) {
defer conn.Close()
buf := make([]byte, 4069)
for {
// 1.读取数据
n, err := conn.Read(buf)
if err != nil {
if errors.Is(err, io.EOF) {
fmt.Println("Remote connection has been closed by client")
return
}
fmt.Println("Read error:", err)
return
}
//2. 转化为大写
wbuf := bytes.ToUpper(buf[:n])
// 3.发送给客户端
_, err = conn.Write(wbuf[:n])
if err != nil {
fmt.Println("Write error:", err)
return
}
}
}
上面的go代码与2.3节中的基于I/O多路复用的C++代码的功能是一样的,但是用Go编写的代码要清晰的多,我们只需按照顺序程序的设计方法来编写即可,因为底层复杂的epoll逻辑已经被runtime给隐藏起来了,虽然我们没有显式地去使用epoll,但是runtime帮我们使用了。
在用户层来看(相对于Go的runtime),goroutine采用了阻塞I/O模型进行网络操作,Socket都是"阻塞"的。但实际上,这样的假象是Go运行时中的netpoller(网络轮询器)通过I/O多路复用机制模拟出来的,实际上对应的底层操作系统socket是非阻塞的。只是运行时拦截了针对底层Socket系统调用返回的错误码,并通过netpoller和goroutine调度让gouroutine阻塞在用户层所看到的Socket上。
比如,当某个goroutine发起read操作时,底层会调用到操作系统的read调用,由于socket在创建时已经被设置为了非阻塞,因此如果没有数据,read将直接返回,并且返回EAGAIN或EWOULDBLOCK的错误码。runtime在获取到错误码后,即可将当前进行读操作的goroutine挂起,让出CPU给其它goroutine使用。在socket创建时,runtime将会把socket加入netpoller中监听(在linux下netpoller使用了epoll),当Go运行时收到该socket数据可读的通知后,运行时才会唤醒阻塞在该socket上的goroutine。
如下图所示,当一个goroutine发起Read之后,会依次调用netFD.Read、poll.FD.Read,最终在poll.FD.Read中会先调用操作系统提供的read系统调用,如果没有数据,就会返回EAGIN错误码,然后goroutine将会被挂起。当gouroutine被唤醒后,也就意味着已经有数据可读了,读取数据,最后返回。
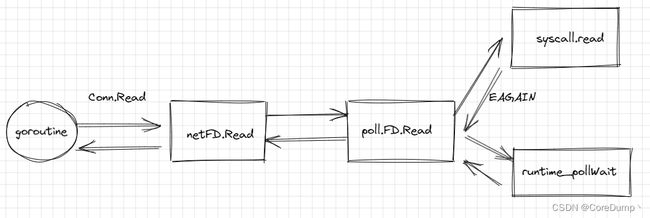
可以看到,用Go编写的网络服务器在用户层面的网络I/O方式为阻塞I/O + goroutine,与2.1节中的阻塞I/O + 多线程的方式很相似,但是Go的协程相比较于线程要轻量级的多,而且使用起来也更加方便,即启即用,因此在程序中启动成千上万的协程也不是问题。而线程不仅会占用大量资源,而且阻塞I/O操作会挂起整个线程,当线程较多时,操作系统的调度将会非常频繁,频繁的上下文切换也会消耗大量资源。但是goroutine的调度由Go运行时的调度器负责调度,不会涉及到内核的上下文切换,因为内核对于goroutine是无感知的,而且goroutine的挂起并不会导致线程的挂起,线程还可以继续运行其它的goroutine,因此这种方式对于开发人员是非常友好而且高效的。
3.2 Go网络编程架构
Go网络使用了非阻塞模型+多路复用的方式,但是在用户层是阻塞模型+goroutine的方式:
- 在底层使用操作系统的I/O多路复用和非阻塞
- 在协程层次使用阻塞模型,没有数据可读是,休眠协程
虽然大部分操作系统都有select这种多路复用方式,但是考虑到select有比较多的限制,比如监听的socket的数量有上限(1024)、事件复杂度高等。Go运行时选择在不同的操作系统上使用各个操作系统提供的高性能多路复用函数,比如Linux上的epoll、Windows上的iocp(异步I/O)、maxOS/FreeBSD上的kqueue、Solaris上的event port等,如下图所示:

如下图所示为go网络编程的整体框架,最底层是操作系统提供的socket编程接口。多路复用抽象层是为了统一各个操作系统对多路复用器的实现,在不同的操作系统上实现了不同的I/O多路复用逻辑,在具体的平台上编译时会编译对应的实现文件。go将底层的多路复用隐藏在了runtime中,在上层为我们提供了net包。

3.3 netpoller
netpoller是网络轮询器的抽象层,是与平台无关的,它抽象出了几个方法,这些方法的具体实现是平台相关的。就相当于接口定义和接口实现的关系。
源码在src/runtime/netpoll.go中, sdk版本:go1.18
接下来看他都定义了哪些接口:
func netpollinit()
// Initialize the poller. Only called once.
//
func netpollopen(fd uintptr, pd *pollDesc) int32
// Arm edge-triggered notifications for fd. The pd argument is to pass
// back to netpollready when fd is ready. Return an errno value.
//
func netpollclose(fd uintptr) int32
// Disable notifications for fd. Return an errno value.
//
func netpoll(delta int64) gList
// Poll the network. If delta < 0, block indefinitely. If delta == 0,
// poll without blocking. If delta > 0, block for up to delta nanoseconds.
// Return a list of goroutines built by calling netpollready.
//
func netpollBreak()
// Wake up the network poller, assumed to be blocked in netpoll.
//
func netpollIsPollDescriptor(fd uintptr) bool
// Reports whether fd is a file descriptor used by the poller.
netpollinit():初始化网络轮询器,在整个应用生命周期内,只会被调用一次netpollopen():fd的边缘触发通知。将fd加入到网络轮询器中监听netpollclose():删除fd在网络轮询器中的监听netpoll():轮询网络,向内核查询是否有事件发生。delta < 0,阻塞模式,delta == 0,非阻塞模式,delta > 0 最多等待delta纳秒。返回一个goroutine的列表。netpollBreak():唤醒网络轮询器netpollIsPollDescriptor():判断fd是否是被poller使用的fd
接下来是网络轮询器需要使用的一个结构Network poller descriptor:
pollDesc中包含了底层网络文件描述符fd,以及rg、wg,当协程在读取数据时可能会阻塞,此时就会将阻塞的协程地址写入rg中,以便有数据到来时唤醒该goroutine。
type pollDesc struct {
link *pollDesc // pollDesc指针,用来组成链表
fd uintptr // 底层系统调用创建的文件描述符fd
// poll信息
atomicInfo atomic.Uint32 // atomic pollInfo
// 该字段可能有四个值,pdReady、pdWait、nil或者等待读的goroutine的g结构体的地址
rg atomic.Uintptr
// 该字段可能有四个值,pdReady、pdWait、nil或者等待写的goroutine的g结构体的地址
wg atomic.Uintptr
lock mutex // 互斥锁,用来包含下面字段
closing bool
user uint32 // user settable cookie
rseq uintptr // protects from stale read timers
// 读数据定时器
rt timer // read deadline timer (set if rt.f != nil)
rd int64 // read deadline (a nanotime in the future, -1 when expired)
wseq uintptr // protects from stale write timers
// 写数据定时器
wt timer // write deadline timer
wd int64 // write deadline (a nanotime in the future, -1 when expired)
self *pollDesc // storage for indirect interface. See (*pollDesc).makeArg.
}
const (
pdReady uintptr = 1
pdWait uintptr = 2
)
type pollInfo uint32
const (
pollClosing = 1 << iota
pollEventErr
pollExpiredReadDeadline
pollExpiredWriteDeadline
)
pollDesc中,rg和wg可能有如下3种状态:
-
pdReady == 1:网络I/O就绪状态,goroutine消费完后置为nil(0) -
pdWait == 2:goroutine等待被挂起,后续有3种情况:goroutine被挂起,置为goroutine的地址
收到I/O通知,置为pdReady
超时或者被关闭,置为nil
-
goroutine的地址:被设置为挂起的goroutine的地址,当I/O就绪、超时或者被关闭了,记录的goroutine将被唤醒,同时将状态改为pdReady或者nil
pollCache是一个全局的pollDesc链表,pollDesc的分配都要从中获取,使用完后也会插入到链表中重用:
var pollcache pollCache // 全局pollDesc链表
type pollCache struct {
lock mutex
first *pollDesc
}
接下来我们看netpoller在linux下的实现,源码在src/runtime/netpoll_epoll中
3.3.1 netpoll epoll实现
变量定义:
var (
epfd int32 = -1 // epoll文件描述符
netpollBreakRd, netpollBreakWr uintptr // linux管道,用来打断网络轮询器,epoll也可以监听管道的读写事件
netpollWakeSig uint32 // used to avoid duplicate calls of netpollBreak
)
初始化netpoller:netpollinit
下面是epoll的netpollinit的实现:
netpollinit的逻辑很简单,就是初始化epoll,步骤如下:
- 使用epollcreate1和epollcreate系统调用创建epoll。
- 创建了一个非阻塞的linux管道,然后将管道的读端写入了epoll的读事件监听中。
func netpollinit() {
// 使用epollcreate创建epoll
epfd = epollcreate1(_EPOLL_CLOEXEC)
// 如果失败,再次尝试
if epfd < 0 {
epfd = epollcreate(1024)
if epfd < 0 {
println("runtime: epollcreate failed with", -epfd)
throw("runtime: netpollinit failed")
}
closeonexec(epfd)
}
// 创建一个非阻塞的linux管道
r, w, errno := nonblockingPipe()
if errno != 0 {
println("runtime: pipe failed with", -errno)
throw("runtime: pipe failed")
}
ev := epollevent{
events: _EPOLLIN,
}
*(**uintptr)(unsafe.Pointer(&ev.data)) = &netpollBreakRd
// 将管道的写端加入epoll的读事件监听中
errno = epollctl(epfd, _EPOLL_CTL_ADD, r, &ev)
if errno != 0 {
println("runtime: epollctl failed with", -errno)
throw("runtime: epollctl failed")
}
netpollBreakRd = uintptr(r)
netpollBreakWr = uintptr(w)
}
注册fd事件监听:netpollopen
netpollopen就相当于2.3节C++代码中的epollAddEvent。使用epollctl来将指定的fd加入到epoll中监听,而且使用了边缘触发的方式(EPOLLET),而pd就相当于2.3节中的conn,用来记录fd相关信息。
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
// 设置监听的事件以及边缘触发的方式
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
// 将fd对应的pollDesc记录在epollevent中
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
// 使用epollctl将fd加入epoll中监听
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
删除fd事件监听:netpollclose
同样,netpollclose就相当于2.3节中的epollDelEvent,使用epollctl来删除fd在epoll中的监听
func netpollclose(fd uintptr) int32 {
var ev epollevent
// 删除fd在epoll中的监听
return -epollctl(epfd, _EPOLL_CTL_DEL, int32(fd), &ev)
}
定期轮询:netpoll
netpoll的步骤如下:
- 调用epolwait向内核询问是否有事件发生,如果没有,返回或者重试;如果有事件发生,则继续下面的逻辑
- 遍历返回的事件列表,获取对应fd发生的事件,返回正在等待读写的协程地址,并将pollDesc的rg或wg置为pdReady,表示数据已经可读或可写了。
- 最后返回具备读写条件的协程链表,由netpoll的调用方来唤醒这些协程。
func netpoll(delay int64) gList {
if epfd == -1 {
return gList{}
}
... // 省略了一些代码,传入的delay如果大于0,单位是纳秒,需要转换为毫秒
var events [128]epollevent
retry:
// 调用epollwait向内核查询是否有事件发生
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
if n < 0 {
if n != -_EINTR {
println("runtime: epollwait on fd", epfd, "failed with", -n)
throw("runtime: netpoll failed")
}
if waitms > 0 {
return gList{}
}
// 返回EINTR,说明epollwait被操作系统信号打断了,要重试
goto retry
}
// 到此处,说明监听的fd有事件发生
var toRun gList
for i := int32(0); i < n; i++ {
ev := &events[i]
if ev.events == 0 {
continue
}
// 判断是否是被管道发来的数据而打断
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
if ev.events != _EPOLLIN {
println("runtime: netpoll: break fd ready for", ev.events)
throw("runtime: netpoll: break fd ready for something unexpected")
}
if delay != 0 {
var tmp [16]byte
read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp)))
atomic.Store(&netpollWakeSig, 0)
}
continue
}
var mode int32
// 判断当前事件是否有读事件
if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'r'
}
// 判断当前事件是否有写事件
if ev.events&(_EPOLLOUT|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'w'
}
if mode != 0 {
pd := *(**pollDesc)(unsafe.Pointer(&ev.data))
pd.setEventErr(ev.events == _EPOLLERR)
// 调用netpollready处理,在netpollready中将对应fd等待读写的goroutine放入链表中
netpollready(&toRun, pd, mode)
}
}
// 最后返回gList,由调用方唤醒
return toRun
}
// 将等待的协程地址放入toRun链表中
func netpollready(toRun *gList, pd *pollDesc, mode int32) {
var rg, wg *g
if mode == 'r' || mode == 'r'+'w' {
rg = netpollunblock(pd, 'r', true)
}
if mode == 'w' || mode == 'r'+'w' {
wg = netpollunblock(pd, 'w', true)
}
if rg != nil {
toRun.push(rg)
}
if wg != nil {
toRun.push(wg)
}
}
// 获取正在等待的协程地址,并将rg或wg置为pdReady,表示I/O操作已经就绪。如果没有,则返回nil
func netpollunblock(pd *pollDesc, mode int32, ioready bool) *g {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
for {
old := gpp.Load()
// 如果pollDesc.rg为pdReady说明没有goroutine正在等待读取或写入数据
if old == pdReady {
return nil
}
if old == 0 && !ioready {
// Only set pdReady for ioready. runtime_pollWait
// will check for timeout/cancel before waiting.
return nil
}
var new uintptr
if ioready {
new = pdReady
}
if gpp.CompareAndSwap(old, new) {
if old == pdWait {
old = 0
}
// 返回正在等待的协程地址
return (*g)(unsafe.Pointer(old))
}
}
}
netpollBreak
netpollBreak的代码逻辑就是向管道中发送数据来打断网络轮询器,因为管道的读端已经加入了epoll的监听,因此通过写端写入数据后就会被epoll检测到。
func netpollBreak() {
if atomic.Cas(&netpollWakeSig, 0, 1) {
for {
var b byte
// 向管道写端写入数据
n := write(netpollBreakWr, unsafe.Pointer(&b), 1)
if n == 1 {
break
}
if n == -_EINTR {
continue
}
if n == -_EAGAIN {
return
}
println("runtime: netpollBreak write failed with", -n)
throw("runtime: netpollBreak write failed")
}
}
}
netpollIsPollDescriptor
判断fd是否是被poller使用的fd,主要有三个 epfd和管道的读写端。
func netpollIsPollDescriptor(fd uintptr) bool {
return fd == uintptr(epfd) || fd == netpollBreakRd || fd == netpollBreakWr
}
3.3.2 netpollinit的调用时机
netpollinit是用来初始化epoll,那么它是在哪里被调用的又是在什么时候被调用的呢?
我们可以在src/runtime/netpoll.go下找到
调用链路如下:
poll_runtime_pollServerInit --> netpollGenericInit -->netpollinit
在poll_runtime_pollServerInit函数声明上面加了go:linkname,将该函数链接到了internal/poll.runtime_pollServerInit函数中,因此该函数将会在poll包中被调用。
var (
netpollInitLock mutex
netpollInited uint32
)
//go:linkname poll_runtime_pollServerInit internal/poll.runtime_pollServerInit
func poll_runtime_pollServerInit() {
netpollGenericInit()
}
func netpollGenericInit() {
if atomic.Load(&netpollInited) == 0 {
lockInit(&netpollInitLock, lockRankNetpollInit)
lock(&netpollInitLock)
if netpollInited == 0 {
// 在这里调用了netpollinit
netpollinit()
atomic.Store(&netpollInited, 1)
}
unlock(&netpollInitLock)
}
}
poll包是连接runtime netpoller和net包的一个中间包,我们知道,go中使用标识符首字母大小写作为包内资源访问的权限,正常情况下,poll包是无法使用runtime包下的私有数据的,但是利用go:linkname就可以将poll包下的函数声明在链接时链接到runtime中的函数。
下面poll包中定义的函数就相当于是runtime包下的。src/internal/poll/fd_poll_unix.go
func runtime_pollServerInit()
func runtime_pollOpen(fd uintptr) (uintptr, int)
func runtime_pollClose(ctx uintptr)
func runtime_pollWait(ctx uintptr, mode int) int
func runtime_pollWaitCanceled(ctx uintptr, mode int) int
func runtime_pollReset(ctx uintptr, mode int) int
func runtime_pollSetDeadline(ctx uintptr, d int64, mode int)
func runtime_pollUnblock(ctx uintptr)
func runtime_isPollServerDescriptor(fd uintptr) bool
poll.pollDesc
在poll包中也定义了一个名为pollDesc的结构体:
pollDesc中只包含了一个原始指针runtimeCtx
type pollDesc struct {
runtimeCtx uintptr
}
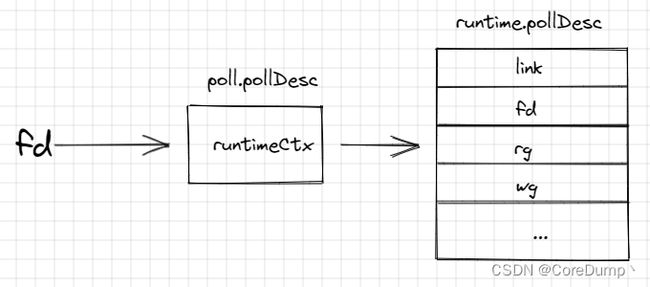
在pollDesc的init方法中可以看到调用了runtime_pollServerInit方法,而且使用了一个全局的sync.Once来初始化,保证netpoller在整个程序的运行期间只会被初始化一次。调用runtime_pollOpen时获取了一个ctx,这个ctx正是runtime.pollDesc的实例指针,因此poll.pollDesc中的指针记录的正是runtime.pollDesc的一个实例。函数调用传入的参数是底层操作系统I/O文件描述符。
var serverInit sync.Once
func (pd *pollDesc) init(fd *FD) error {
// 初始化netpoller
serverInit.Do(runtime_pollServerInit)
// 调用runtime_pollOpen将fd加入netpoller中监听,并获取ctx(runtime.pollDesc的一个实例)
ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd))
if errno != 0 {
return errnoErr(syscall.Errno(errno))
}
pd.runtimeCtx = ctx
return nil
}
runtime_pollOpen的实现是在runtime/netpoll.go中:
步骤如下:
- 在poll_runtime_pollOpen中分配了一个runtime.pollDesc结构体,然后对其中的字段进行了重置(因为是从pollCache中获取的,需要重置字段)
- 将传入的fd加入netpoller的监听,最后返回了runtime.pollDesc实例的地址
//go:linkname poll_runtime_pollOpen internal/poll.runtime_pollOpen
func poll_runtime_pollOpen(fd uintptr) (*pollDesc, int) {
// 分配runtime.pollDesc结构体
pd := pollcache.alloc()
// 重置pd中的字段
lock(&pd.lock)
wg := pd.wg.Load()
if wg != 0 && wg != pdReady {
throw("runtime: blocked write on free polldesc")
}
rg := pd.rg.Load()
if rg != 0 && rg != pdReady {
throw("runtime: blocked read on free polldesc")
}
pd.fd = fd
pd.closing = false
pd.setEventErr(false)
pd.rseq++
pd.rg.Store(0)
pd.rd = 0
pd.wseq++
pd.wg.Store(0)
pd.wd = 0
pd.self = pd
pd.publishInfo()
unlock(&pd.lock)
// 调用netpollopen将当前fd加入到netpoller监听
errno := netpollopen(fd, pd)
if errno != 0 {
pollcache.free(pd)
return nil, int(errno)
}
// 返回pd的地址
return pd, 0
}
因此poll.pollDesc中的runtimeCtx指针指向的正是runtime.pollDesc结构体的实例,每个fd都会对应一个poll.pollDesc和runtime.pollDesc结构体实例,如下图所示:
3.4 net包底层实现
接下来看net包是如何实现的,而且net包是如何跟底层的netpoller联系在一起的,主要看TCPConn的实现,代码在src/net/net.go中。
net.Dial以及使用Listner的Accept后,都会返回一个net.Conn的接口类型,其底层类型是TCPConn:
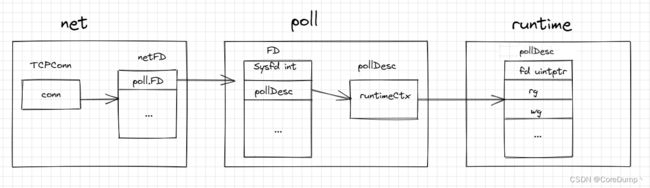
TCPConn中包含了一个非导出的conn,主要的读写逻辑都在conn中实现。
而conn中又包含了netFD,这个结构体是net包对socket的抽象
netFD中又包含了poll.FD,这个结构体是poll包对文件描述符fd的抽象
// TCPConn is an implementation of the Conn interface for TCP network
// connections.
type TCPConn struct {
conn
}
type conn struct {
fd *netFD
}
// Network file descriptor.
type netFD struct {
pfd poll.FD
...
}
type FD struct {
// 对Sysfd的Read和Write操作将会加锁
fdmu fdMutex
// 系统文件描述符,直到关闭前是不可修改的
Sysfd int
// poll.pollDesc
pd pollDesc
...
}
FD就表示为Go中的文件描述符,net包和os包最终都会使用这个结构体,它是对linux操作系统底层文件描述符的抽象。而且可以看到poll.FD中包含了poll.pollDesc,因此net包->poll包->runtime包的联系就建立起来了。
3.4.1创建监听器(Listen)和接受新连接(Accept)
net.Listen
在socket编程中,启动一个监听socket的步骤主要有三个:创建socket(socket)、绑定IP和端口(bind)、启动监听(listen),go的TCP Listen步骤也是如此。但是在go中会使用netpoller,因此还需要初始化netpoller以及将监听socket加入到netpoller中。
net.Listen的执行流程如下图,在Linsten中主要进行了以下步骤:
- 使用系统调用socket创建了一个socket,并获取操作系统文件描述符,并将该文件描述符设置为了非阻塞。
- 然后接着调用bind和listen系统调用
- 然后调用runtime_pollServerInit来初始化netpoller(runtime_pollServerInit只会被调用一次,一般作为TCP Server是在此处被调用)
- 之后使用runtime_pollOpen创建runtime.pollDesc结构并将文件描述符加入netpoller的监听中,最后将文件描述符包装为一个net.TCPListener返回

源码如下:
可以看到TCPListener中也包含了一个netFD的指针。
type TCPListener struct {
fd *netFD
lc ListenConfig
}
func (lc *ListenConfig) Listen(ctx context.Context, network, address string) (Listener, error) {
... // 解析地址
sl := &sysListener{
ListenConfig: *lc,
network: network,
address: address,
}
var l Listener
la := addrs.first(isIPv4)
switch la := la.(type) {
case *TCPAddr:
l, err = sl.listenTCP(ctx, la) // 调用ListenTCP来监听TCP
...
return l, nil
}
func (sl *sysListener) listenTCP(ctx context.Context, laddr *TCPAddr) (*TCPListener, error) {
// 继续调用internetSocket获取netFD实例
fd, err := internetSocket(ctx, sl.network, laddr, nil, syscall.SOCK_STREAM, 0, "listen", sl.ListenConfig.Control)
if err != nil {
return nil, err
}
return &TCPListener{fd: fd, lc: sl.ListenConfig}, nil
}
func internetSocket(ctx context.Context, net string, laddr, raddr sockaddr, sotype, proto int, mode string, ctrlFn func(string, string, syscall.RawConn) error) (fd *netFD, err error) {
...
// 调用socket
return socket(ctx, net, family, sotype, proto, ipv6only, laddr, raddr, ctrlFn)
}
func socket(ctx context.Context, net string, family, sotype, proto int, ipv6only bool,
laddr, raddr sockaddr, ctrlFn func(string, string, syscall.RawConn) error) (fd *netFD, err error) {
// 创建监听socket,并间fd设置为非阻塞
s, err := sysSocket(family, sotype, proto)
if err != nil {
return nil, err
}
...
// 构造netFD实例
if fd, err = newFD(s, family, sotype, net); err != nil {
poll.CloseFunc(s)
return nil, err
}
...
// 监听TCP
if err := fd.listenStream(laddr, listenerBacklog(), ctrlFn); err != nil {
...
}
func sysSocket(family, sotype, proto int) (int, error) {
// 使用系统调用socket来创建一个socket,并设置SOCK_NONBLOCK属性将fd设置为非阻塞
s, err := socketFunc(family, sotype|syscall.SOCK_NONBLOCK|syscall.SOCK_CLOEXEC, proto)
switch err {
case nil:
return s, nil
default:
return -1, os.NewSyscallError("socket", err)
case syscall.EPROTONOSUPPORT, syscall.EINVAL:
}
// 如果创建成功,在上面就已经返回
// 如果操作系统不支持使用SOCK_NONBLOCK和SOCK_CLOEXEC参数来创建socket就不使用这些参数创建
// 然后使用SetNonblock来将fd设置为非阻塞
syscall.ForkLock.RLock()
// 重新创建socket
s, err = socketFunc(family, sotype, proto)
if err == nil {
syscall.CloseOnExec(s)
}
syscall.ForkLock.RUnlock()
if err != nil {
return -1, os.NewSyscallError("socket", err)
}
// 设置非阻塞
if err = syscall.SetNonblock(s, true); err != nil {
poll.CloseFunc(s)
return -1, os.NewSyscallError("setnonblock", err)
}
return s, nil
}
func (fd *netFD) listenStream(laddr sockaddr, backlog int, ctrlFn func(string, string, syscall.RawConn) error) error {
var err error
// 在setDefaultListenerSockopts中设置SO_REUSEADDR来复用端口,也就是服务端在关闭之后,也可以立即启动,而不会因为address in use的错误而重启失败
if err = setDefaultListenerSockopts(fd.pfd.Sysfd); err != nil {
return err
}
var lsa syscall.Sockaddr
if lsa, err = laddr.sockaddr(fd.family); err != nil {
return err
}
if ctrlFn != nil {
c, err := newRawConn(fd)
if err != nil {
return err
}
if err := ctrlFn(fd.ctrlNetwork(), laddr.String(), c); err != nil {
return err
}
}
// 使用bind系统调用绑定端口和IP
if err = syscall.Bind(fd.pfd.Sysfd, lsa); err != nil {
return os.NewSyscallError("bind", err)
}
// 使用listen系统调用来启动监听
if err = listenFunc(fd.pfd.Sysfd, backlog); err != nil {
return os.NewSyscallError("listen", err)
}
// 在pd.init中初始化netpoller并将当前监听fd加入到netpoller中监听
if err = fd.init(); err != nil {
return err
}
lsa, _ = syscall.Getsockname(fd.pfd.Sysfd)
fd.setAddr(fd.addrFunc()(lsa), nil)
return nil
}
可以看到,在上面的代码和常规的socket编程流程差不多,都是先调用socket来创建一个监听socket,然后调用bind绑定端口和IP,调用listen来启动监听。最后调用poll.FD.init来将当前socket和netpoller联系起来。在3.32节中已经介绍了poll.FD.init函数,在其中先初始化netpoller,然后将传入的fd加入到netpoller中监听。
TcpListener.AcceptTCP()
在使用Listenr的Accept时,最终会调用TCPListner的AcceptTCP,AcceptTCP的执行流程如下:
- 调用AcceptTCP最终会调用系统调用accept,如果返回错误码EAGAIN说明还没有连接到来,因此最终会依次调用fd.pd.waitRead、pd.wait、runtime_pollWait、netpollblock,最终在netpollblock中调用gopark将当前协程休眠,并将当前协程地址记录在pollDesc的rg中。
- 如果有新的连接到来,或者被唤醒后,就会接收新的连接并返回fd,然后将该fd包装为一个netFD对象,并调用netFD的init来讲当前fd加入netpoller的监听中,最终包装为一个net.Conn接口并返回

func (l *TCPListener) AcceptTCP() (*TCPConn, error) {
...
// 调用accept
c, err := l.accept()
...
return c, nil
}
func (ln *TCPListener) accept() (*TCPConn, error) {
// 调用netFD的accept
fd, err := ln.fd.accept()
if err != nil {
return nil, err
}
tc := newTCPConn(fd)
...
return tc, nil
}
func (fd *netFD) accept() (netfd *netFD, err error) {
// 调用poll.FD的accept
d, rsa, errcall, err := fd.pfd.Accept()
if err != nil {
if errcall != "" {
err = wrapSyscallError(errcall, err)
}
return nil, err
}
// 将fd包装为一个netFD
if netfd, err = newFD(d, fd.family, fd.sotype, fd.net); err != nil {
poll.CloseFunc(d)
return nil, err
}
//调用netFD的init来将fd加入netpoller的监听中
if err = netfd.init(); err != nil {
netfd.Close()
return nil, err
}
lsa, _ := syscall.Getsockname(netfd.pfd.Sysfd)
netfd.setAddr(netfd.addrFunc()(lsa), netfd.addrFunc()(rsa))
return netfd, nil
}
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
// 上读锁
if err := fd.readLock(); err != nil {
return -1, nil, "", err
}
defer fd.readUnlock()
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return -1, nil, "", err
}
for {
// 使用系统调用accept获取一个客户端fd,如果返回了错误而且为EAGAIN,说明还没有新的连接到来
s, rsa, errcall, err := accept(fd.Sysfd)
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EINTR: // 被操作系统打断,重启accept
continue
case syscall.EAGAIN:
if fd.pd.pollable() { // 没有新连接到来,调用waitRead来将当前goroutine挂起,并记录goroutine地址
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
case syscall.ECONNABORTED:
// This means that a socket on the listen
// queue was closed before we Accept()ed it;
// it's a silly error, so try again.
continue
}
return -1, nil, errcall, err
}
}
// pd:poll.pollDesc
func (pd *pollDesc) waitRead(isFile bool) error {
return pd.wait('r', isFile)
}
// pd:poll.pollDesc
func (pd *pollDesc) wait(mode int, isFile bool) error {
if pd.runtimeCtx == 0 {
return errors.New("waiting for unsupported file type")
}
res := runtime_pollWait(pd.runtimeCtx, mode)
return convertErr(res, isFile)
}
协程挂起操作:
在Accep接收新的连接、Read读取数据或Write写数据时,可能会没有数据或者当前不能写出,就需要将当前协程挂起并记录协程地址,这个功能主要是在runtime的poll_runtime_pollWait函数中实现的:
// runtime_pollWait 被链接到runtime的poll_runtime_pollWait函数
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
...
// 调用netpollblock
for !netpollblock(pd, int32(mode), false) {
errcode = netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
}
return pollNoError
}
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// 将gpp设置为pdWait,gpp指向rg的地址
for {
// 如果当前是就绪状态,就不需要挂起,直接返回
if gpp.CompareAndSwap(pdReady, 0) {
return true
}
// 将gpp置为pdWait
if gpp.CompareAndSwap(0, pdWait) {
break
}
// Double check that this isn't corrupt; otherwise we'd loop
// forever.
if v := gpp.Load(); v != pdReady && v != 0 {
throw("runtime: double wait")
}
}
if waitio || netpollcheckerr(pd, mode) == pollNoError {
// 调用gopark挂起当前协程,在挂起协程之前会执行netpollblockcommit函数来记录挂起的协程地址
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent pdReady notification
old := gpp.Swap(0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
// 在netpollblockcommit记录要挂起的协程地址在rg中
func netpollblockcommit(gp *g, gpp unsafe.Pointer) bool {
r := atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp)))
if r {
atomic.Xadd(&netpollWaiters, 1)
}
return r
}
可以看到在上面将rg或wg的状态置为pdWait后,再将协程挂起前又将状态设置为了协程地址,因此pdWait只是一个中间状态,存在的时间很短。
3.4.2 conn读写操作
conn.Read
Read操作与Accept差不多,本质都是读取数据。Read首先会使用read系统调用来读取一次数据,如果没有数据则会返回EAGAIN,然后该协程会被挂起。当协程被唤醒时,说明已经有数据可读了,将会尝试再次读取数据并返回。协程挂起的操作与Accept一样,最终都会调用poll_runtime_pollWait来挂起协程并记录协程地址。

func (c *conn) Read(b []byte) (int, error) {
...
// 调用netFD的Read
n, err := c.fd.Read(b)
...
}
func (fd *netFD) Read(p []byte) (n int, err error) {
// 调用poll.FD的Read
n, err = fd.pfd.Read(p)
...
}
func (fd *FD) Read(p []byte) (int, error) {
// 加读锁
if err := fd.readLock(); err != nil {
return 0, err
}
defer fd.readUnlock()
if len(p) == 0 {
return 0, nil
}
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return 0, err
}
if fd.IsStream && len(p) > maxRW {
p = p[:maxRW]
}
for {
// 使用read系统调用读取数据
n, err := ignoringEINTRIO(syscall.Read, fd.Sysfd, p)
if err != nil {
n = 0
// 如果返回错误码为EAGAIN,挂起当前协程。协程被唤醒后将再次尝试读取数据
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
}
err = fd.eofError(n, err)
return n, err
}
}
结论:通过上面的代码可以看到,在FD.Read方法中,在使用系统调用read读取数据前会加读锁,就算当前协程被挂起,也不会解除读锁。因此多个协程对同一个连接的数据读取是没有任何意义的,因为并发的读取操作也会因为加锁而变成串行读取。而且由于TCP协议是流式协议,数据的边界也需要我们去判定,因此并发读取还可能会导致一个数据段被多个协程读到,从而导致数据边界的判定更加困难。
conn.Write
Write的操作也可能会导致当前协程的挂起,因为应用程序的write操作是将数据写入到操作系统内核协议栈的写缓冲区中,而不是直接写到网卡。因此,一旦写缓冲区没有剩余空间,将会导致阻塞。Write与Read流程相似,先使用write尝试写出数据,如果得到EAGAIN的错误码,将会挂起当前的协程,直到协程被唤醒后才会再次尝试写出数据。

func (c *conn) Write(b []byte) (int, error) {
...
// 调用netFD的Write
n, err := c.fd.Write(b)
...
}
func (fd *netFD) Write(p []byte) (nn int, err error) {
// 调用FD的Write
nn, err = fd.pfd.Write(p)
...
}
func (fd *FD) Write(p []byte) (int, error) {
// 加写锁
if err := fd.writeLock(); err != nil {
return 0, err
}
defer fd.writeUnlock()
if err := fd.pd.prepareWrite(fd.isFile); err != nil {
return 0, err
}
var nn int
for {
max := len(p)
if fd.IsStream && max-nn > maxRW {
max = nn + maxRW
}
// 读取数据
n, err := ignoringEINTRIO(syscall.Write, fd.Sysfd, p[nn:max])
if n > 0 {
nn += n
}
if nn == len(p) {
return nn, err
}
// 不可读,挂起当前协程
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitWrite(fd.isFile); err == nil {
continue
}
}
if err != nil {
return nn, err
}
if n == 0 {
return nn, io.ErrUnexpectedEOF
}
}
}
3.4.3 关闭连接
conn.Close
Close看似很简单,但是要做的工作其实还是挺多的。首先,可以有协程正阻塞在数据的读写上,因此首先要唤醒阻塞的协程,并返回连接已被关闭的错误。其次,需要删除netpoller对当前fd的监听,最终关闭socket。
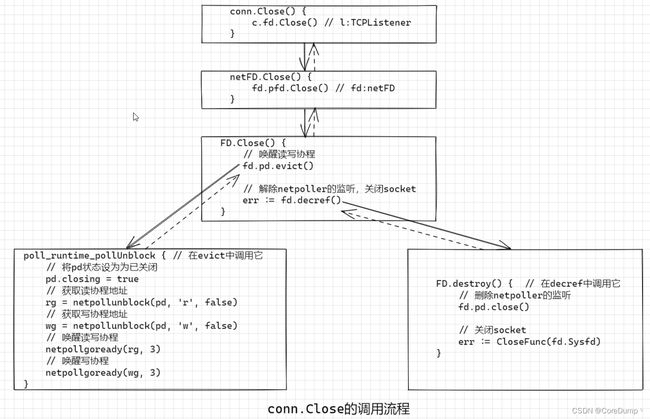
func (c *conn) Close() error {
...
// 调用netFD的Close
err := c.fd.Close()
...
}
func (fd *netFD) Close() error {
...
// 调用FD的Close
return fd.pfd.Close()
}
func (fd *FD) Close() error {
// 设置mu中的state为关闭状态,如果已经关闭,将会返回errClosing的错误
if !fd.fdmu.increfAndClose() {
return errClosing(fd.isFile)
}
// 唤醒读写协程
fd.pd.evict()
// 解除netpoller的监听,关闭socket
err := fd.decref()
if fd.isBlocking == 0 {
runtime_Semacquire(&fd.csema)
}
return err
}
在evict中主要是要将closing设置为true,然后获取读或写协程的地址(如果没有返回nil),然后删除对应的定时器,最后唤醒它们。
func (pd *pollDesc) evict() {
if pd.runtimeCtx == 0 {
return
}
runtime_pollUnblock(pd.runtimeCtx)
}
func poll_runtime_pollUnblock(pd *pollDesc) {
lock(&pd.lock)
if pd.closing {
throw("runtime: unblock on closing polldesc")
}
// 将pd状态设为为已关闭
pd.closing = true
pd.rseq++
pd.wseq++
var rg, wg *g
pd.publishInfo()
// 获取读协程地址
rg = netpollunblock(pd, 'r', false)
// 获取写协程地址
wg = netpollunblock(pd, 'w', false)
if pd.rt.f != nil {
// 删除写超时定时器
deltimer(&pd.rt)
pd.rt.f = nil
}
if pd.wt.f != nil {
deltimer(&pd.wt)
pd.wt.f = nil
}
unlock(&pd.lock)
if rg != nil {
// 唤醒读写协程
netpollgoready(rg, 3)
}
if wg != nil {
// 唤醒写协程
netpollgoready(wg, 3)
}
}
在decref中主要的工作有两个:删除fd在netpoller中的监听、关闭socket
func (fd *FD) decref() error {
if fd.fdmu.decref() {
return fd.destroy()
}
return nil
}
func (fd *FD) destroy() error {
// 删除netpoller的监听
fd.pd.close()
// 关闭socket
err := CloseFunc(fd.Sysfd)
fd.Sysfd = -1
runtime_Semrelease(&fd.csema)
return err
}
在将连接关闭后,将会唤醒阻塞的读协程和写协程,被唤醒后将会使用netpollcheckerr来检查是否在挂起期间有错误发生,比如连接被关闭(pollErrClosing)、超时(pollErrTimeout)等。如果没有发生错误,才会再次尝试读取数据,否则就逐层返回error。
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
...
if waitio || netpollcheckerr(pd, mode) == pollNoError {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// 协程被唤醒后,继续下面代码
old := gpp.Swap(0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
// 如果rg或wg不是pdReady,可能有错误发生
return old == pdReady
}
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
...
for !netpollblock(pd, int32(mode), false) {
// 检查是否在挂起期间是否有错误发生
errcode = netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
}
return pollNoError
}
// 这里返回的是int类型的错误码
func netpollcheckerr(pd *pollDesc, mode int32) int {
info := pd.info()
// 连接被关闭,将会返回pollErrClosing的错误码
if info.closing() {
return pollErrClosing
}
// 超时错误
if (mode == 'r' && info.expiredReadDeadline()) || (mode == 'w' && info.expiredWriteDeadline()) {
return pollErrTimeout
}
if mode == 'r' && info.eventErr() {
return pollErrNotPollable
}
return pollNoError
}
// 在poll.pollDesc的wait中将错误码包装为error接口的错误
func (pd *pollDesc) wait(mode int, isFile bool) error {
if pd.runtimeCtx == 0 {
return errors.New("waiting for unsupported file type")
}
res := runtime_pollWait(pd.runtimeCtx, mode)
return convertErr(res, isFile)
}
func convertErr(res int, isFile bool) error {
switch res {
case pollNoError:
return nil
case pollErrClosing:
return errClosing(isFile)
case pollErrTimeout:
return ErrDeadlineExceeded
case pollErrNotPollable:
return ErrNotPollable
}
println("unreachable: ", res)
panic("unreachable")
}
如果在读取数据时服务端主动将客户端conn关闭,我们将会得到ErrNetClosing的错误。
但是如果是客户端主动关闭了连接,那么将会得到io.EOF的error
type errNetClosing struct{}
var ErrNetClosing = errNetClosing{}
func (e errNetClosing) Error() string { return "use of closed network connection" }
3.5 定期轮询netpoll是在哪里被调用的
前面介绍了netpoller的初始的调用时机,在Dial、Listen、Accept中都会初始化netpoller,但是只会被初始化一次。那么netpoll是在哪调用呢?在2.3节中的C++代码中,我们是在主线程中不停阻塞调用的,那么接下来将看一下go的netpoller是在哪里轮询的。
使用Goland的ctrl+shift+f可以启用全局搜索来搜索netpoll的调用,搜到的结果如下:
1.在proc.go的startTheWorldWithSema函数中调用了netpoll
2.在proc.go的findrunnable函数中也找到了netpoll的调用

3.在proc.go的sysmon函数中调用了netpoll

可以看到在执行gc的STW时、在寻找可运行的goroutine时以及在系统监控线程sysmon中都会调用netpoll。
在调用netpoll后获取一个就绪的g链表,然后调用injectglist将链表中的g的状态从_Gwaiting置为_Grunnable,然后将这些g放入p的本地队列或者全局队列中。sysmon是系统监控线程的主要执行逻辑,sysmon没有p与其绑定,因此系统监控线程调用netpoll获取的g将会被放入全局可运行队列globrunq中。