【大数据之路3】分布式协调系统 Zookeeper
3. 分布式协调系统 Zookeeper
-
- 1. Zookeeper 概述
-
- 1. Zookeeper 介绍
- 2. Zookeeper 结构/功能【重点】
-
- 1. 文件系统 ZNode
-
- 1. ZNode 特点
- 2. ZNode 功能
- 3. ZNode 介绍【非常重要】
- 2. 监听机制
- 3. 典型应用场景
-
- 1. 命名服务
- 2. 配置管理
- 3. 集群管理
- 4. 分布式锁
- 5. 队列管理
- 2. 架构与原理
-
- 1. Zookeeper 架构
-
- 1. 架构概述
- 2. 主从架构
- 3. 集群角色描述
- 2. 集群选主【非常重要】
-
- 1. 全新的集群选主
- 2. 非全新集群选主
- 3. 数据同步
- 4. 功能/工作流程
-
- 1. Leader 功能
- 2. Follower 功能
- 3. ObServer 工作流程
- 4. Zookeeper 工作流程
- 5. 配置文件 zoo.cfg 详解
- 3. Zookeeper 相关操作
-
- 1. 命令行操作
- 2. API 操作
1. Zookeeper 概述
1. Zookeeper 介绍
Zookeeper 是一个开放源码的分布式应用程序协调服务,是 Google 的 Chubby(分布式锁)一个开源的实现。它提供了简单原始的功能(ZNode 和监听机制),分布式应用可以基于它实现更高级的服务,比如 分布式同步、配置管理、集群管理、命名管理、队列管理。它被设计为易于编程,使用 文件系统目录树作为数据模型。服务端运行在 Java 上,提供 Java 和 C 客户端 API。
Zookeeper 是集群的管理者,监视着集群中各节点的状态,根据节点的反馈进行下一步合理的操作,最终将简单易用的接口和功能稳定、性能高效的系统提供给用户。
Zookeeper 的数据模型是树结构,在内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据、ACL 信息,zk 会定时将这些数据存储到磁盘上。
Zookeeper 作用:解决分布式集群中的业务协调问题
Zookeeper 设计目的: Zookeeper 作为一个集群提供数据一致的协调服务,最好的方式就是在整个集群中的各服务节点进行数据的复制和同步
数据复制的好处:
- 容错:一个节点出错,不至于让整个集群无法提供服务
- 扩展性:通过增加服务器节点能提高 Zookeeper 系统的负载能力,把负载分布到多个节点上
- 高性能:客户端可访问本地 Zookeeper 节点或访问就近的节点,以此提高用户的访问速度
Zookeeper 的特点:
-
最终一致性:Client 无论连接到哪个 Server,展示给它的都是同一个视图【Zookeeper 最重要的性能】
-
可靠性:具有简单、健壮、良好的性能。如果 消息m 被一台服务器接受,那它将被所有的服务器接受
-
实时性:Zookeeper 保证客户端将在一个时间间隔内获得服务器更新或失效的信息。但由于网络延迟等原因,Zookeeper 不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用
sync()接口进行同步 -
等待无关(wait-free):慢的或失效的 Client 不得干预快速的 Client 的请求,使得每个 Client 都能有效的等待
-
原子性:更新只能成功或失败,没有中间状态
-
顺序性:包括全局有序和偏序两种。全局有序指如果在一台服务器上 消息a 在 消息b 之前发布,则在所有 Server 上 消息a 都将在 消息b 之前发布;偏序指如果 消息b 在 消息a 之后被同一个发布者发布,a 必将排在 b 后面
2. Zookeeper 结构/功能【重点】
1. 文件系统 ZNode
ZNode(Zookeeper Node):Zookeeper 的文件系统。Zookeeper 的命令空间就是 Zookeeper 的文件系统
1. ZNode 特点
-
跟 Linux 类似,也是树状,每一个节点都有一个唯一的绝对路径,对于命名空间的操作必须都是绝对路径的操作
-
与 Linux 文件系统不同的是 Linux 文件系统有目录和文件的区别,而 Zookeeper 统一叫做 ZNode,一个 ZNode 节点可以包含子 ZNode,同时也可以包含数据
2. ZNode 功能
(1)存储数据。ZNode 既是文件夹又是文件,每个 ZNode 有唯一的路径表示。Zookeeper 的每个 ZNode 不能存储大批量的数据,只能存储小批量的关键性的数据(数据格式可看成 key-value 形式:key 是节点的绝对路径,value 是当前 ZNode 节点的值。数据不能超过 1M,最好小于 1KB)
(2)挂载子节点。既可以当文件夹包含文件,又可以当文件存储数据
3. ZNode 介绍【非常重要】
ZNode 分类:
(1)ZNode 分两类:(不管是什么节点,都要有一个特定的 session 会话连接创建)
- 持久节点 persistent(默认):可以有子节点
- 临时节点 ephemeral:不能有子节点
(2)ZNode 分四类:
- 持久节点 persistent
- 带有顺序编号的持久节点
- 举例:
create -s /hadoop "hello"表示在节点里创建名字叫做 /hadoop_01 带有顺序编号的节点并赋予其值为 hello,可重复创建,名字按顺序递增
- 举例:
- 不带顺序编号的持久节点
- 举例:
create /hadoop "hello"表示在根目录下创建 hadoop 节点并赋予其值为 hello,创建相同的节点会失败
- 举例:
- 带有顺序编号的持久节点
- 临时节点 ephemeral
- 带顺序编号的临时节点
- 不带顺序编号的临时节点
说明:
- 创建 ZNode 时设置顺序标识,ZNode 名称后会增加一个值,顺序号是一个单调递增的计数器,由父节点维护
- 在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
- 客户端可以在 ZNode 上设置监听器
2. 监听机制
概念: 客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,Zookeeper 会通知客户端。监听机制保证 Zookeeper 保存的任何数据的任何改变,都能快速的响应到监听了该节点的应用程序
监听器的工作机制/本质: 在客户端会专门建立一个监听机制,在本机的一个端口上等待 zk 集群发送事件过来
Zookeeper 的 Watcher(监听器)机制主要包括: 客户端线程、客户端 WatcherManager、Zookeeper 服务器
监听步骤: 客户端在向 Zookeeper 服务器注册的同时,会将 Watcher 对象(监听机制)存储在客户端的 WatcherManager(监听机制管理器)中。当 Zookeeper 服务器触发 Watcher 事件后,会向客户端发送通知,客户端线程从 WatcherManager 中取出对应的 Watcher 对象来执行回调逻辑。
步骤总结:
- 拿链接,注册监听
- Zookeeper 系统等待该节点的事件
- Client 接收到事件通知后,会自动调用 回调代码
- 回调代码:提前写好节点数据发生变化和节点被删除后对应的业务逻辑代码,当数据发生改变或节点被删除时会自动调用相应代码,从而根据事件类型调用相应的业务逻辑
监听机制流程图:
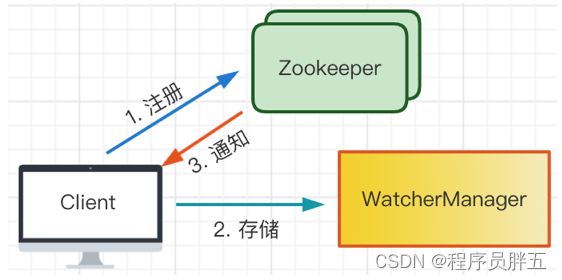
如果监听的节点发生变化,客户端会收到相应通知,监听的线程就不存在了。客户端的监听进程被触发一次后,再有事件触发客户端就接收不到了,此时可以在回调的方法里再次调用处理的方法,相当于做了循环监听。
3. 典型应用场景
1. 命名服务
命名空间 namespace。被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等,通过命名服务,客户端可以根据指定名字获取资源的实体、服务地址和提供者的信息。
2. 配置管理
程序配置部署在多台服务器上,这些配置放到 Zookeeper 上,保存在某个目录节点上,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中即可。
3. 集群管理
- 管理主节点和从节点
- 是否有机器退出或加入
- 选举 Leader
4. 分布式锁
- 写锁(独占锁和排他锁):对写加锁,保持独占,别人无法访问
- 读锁(共享锁):对读加锁,可共享访问,释放锁后才能进行事务操作
- 时序锁:控制时序
5. 队列管理
- 同步队列:当一个队列的成员都聚集时该队列才能用,否则一直等待聚集
- 先进先出队列:队列按照 FIFO 方式进行入队和出队操作
- FIFO(first in, first out):先进先出
- LIFO(last in, first out):后进先出
2. 架构与原理
1. Zookeeper 架构
HDFS 是主从架构,Zookeeper 也是主从架构,但 HDFS 主节点固定,Zookeeper 主节点不固定,任何一个节点都可以成为 Leader。
1. 架构概述
(1)首先要有一个算法
(2)原来的主节点宕机后,集群要能够立刻选举出一个新的主节点
- Zookeeper 集群中的任意两个节点的状态都一模一样
- Zookeeper 能够对外提供服务的最低要求:宕机节点的个数不超过一半【重要】
- Zookeeper 集群的生存能力取决于服务器节点的个数。数量一般在 20 个节点之内,官方配置文件在 256 个之内
2. 主从架构
所有 Zookeeper 节点中都保存了一份完整的 ZNode 系统的数据。这样才能做到无缝链接,才能保证所有的客户端无论连接到 Zookeeper 的哪台服务器,都能读到 ZNode 系统中的最新数据。
ZAB 原子广播协议: 处理 写数据 请求。确保每台机器能获取到最新数据进行写入,用户获取到的都是最新数据
- 主节点接收到会直接进行广播,让所有节点都写入最新数据
- 从节点接收到写数据请求,会转发这条请求给主节点,主节点进行写数据操作,然后广播给其他所有节点进行同步
- 若没有接收到新的数据,则该节点无法对外提供服务
主节点控制 Zookeeper 系统的全局事务(事务编号 zxid 全局递增)
说明:
- 每个从节点都有一条线连接着主节点,当从节点接收到写数据请求,会通过这条线转发给主节点
- 当从节点接收到读数据请求就不需要转发,直接将数据返回给客户端
3. 集群角色描述
Zookeeper 集群的节点个数,一般都是 奇数。

2. 集群选主【非常重要】
1. 全新的集群选主
每个节点里有对应的 serverid,是一个 1~255 的数值( 0 也可以,实际一共 256个),不能重复
选举规则:谁的 serverid 大谁胜出。 但在启动过程中节点超过半数,Leader 就被选出来了,后续的 serverid 再大也只能是 Follower。
Zookeeper 集群的 Leader 选举实例:
- 3 个节点 Hadoop0、Hadoop1、Hadoop2,myid 依次为0、1、2,启动顺序为 Hadoop0、Hadoop1、Hadoop2,则 Hadoop1 是 Leader
- 原因:集群有 3 个节点,启动 Hadoop0 和 Hadoop1 后节点数过半,集群可正常运行。Hadoop1 的 myid 大,为 Leader;当 Hadoop2 加入后,因为有了 Leader 了就不会因为 Hadoop2 的 myid 大 Hadoop1 就让位,Hadoop2 只能做从节点;等 Hadoop1 故障宕机后,Hadoop2 才能以自己的 myid 大而胜出上位 Leader
Zookeeper Server 的三种工作状态:
- LOOKING: 当前 Server 不知道 Leader 是谁,正在搜寻,正在选举
- LEADING: 当前 Server 即为选举出来的 Leader,负责协调事务
- FOLLOWING: Leader 已经选举出来,当前 Server 与之同步,服从 Leader 命令
2. 非全新集群选主
当 Zookeeper 集群运行一段时间后有机器宕机,重新进行选举时,选举过程相对复杂
因素:
- version(数据版本):数据每次更新都会更新 version,数据新的 version 大
- serverid(服务id):myid 中的值,每个机器一个
- 逻辑时钟:该值从 0 开始递增,每次选举对应一个值,即在每次选举中该值是一致的。逻辑时钟值越大说明这次选举 Leader 的进程越新,也就是每次选举拥有一个 zxid,投票结果只取 zxid 最新的
选举标准:
- 逻辑时钟小的选举结果被忽略,重新投票
- 统一逻辑时钟后,数据 version 大的胜出
- 数据 version 相同时,serverid 大的胜出
3. 数据同步
选完 Leader 后,Zookeeper 就进入 状态同步 过程:
- Leader 等待 Follower 连接
- Follower 连接 Leader,将最大的 zxid(事务编号) 发送给 Leader
- Leader 根据 Follower 的 zxid 确认同步点
- 完成同步后通知 Follower 已经成为 uptodate 状态
- Follower 收到 uptodate 消息后,又可以重新接收 Client 的请求进行服务了
流程图:

4. 功能/工作流程
1. Leader 功能
1、恢复数据
2、维持与 Learner 的心跳,接收 Learner 请求并判断 Learner 的请求消息类型
- Leader 与 Follower 之间数据传输类型,数据 packet 中都会包含一个特定的类型用来告知对方如何处理数据,这些类型为常量值,在 Leader 类中。消息类型主要是:
- PING 消息:Learner 的心跳信息
- REQUEST 消息:Follower 发送的提议信息,包括读写请求
- ACK 消息:Follower 对提议的回复,超过半数 Follower 通过则 commit 该提议
- REVALIDATE 消息(重新验证):用来延长 session 有效时间
3、根据不同的消息类型进行不同的处理
2. Follower 功能
1、向 Leader 发送请求(PING 消息、REQUEST 消息、ACK 消息、REVALIDATE 消息[重新验证消息])
2、接收 Leader 消息并进行处理
3、接收 Client 的请求,如果是写请求则转发给 Leader
4、返回 Client 结果
Follower 的消息循环,处理如下几种来自 Leader 的消息:
- PING 消息:心跳信息
- PROPOSAL 消息:Leader 发起的提案,要求 Follower 投票
- COMMIT 消息:服务器端最新一次提案的信息
- UPTODATE:表明同步完成
- REVALIDATE:根据 Leader 的 REVALIDATE 结果,关闭待 revalidate 的 session 允许其接收消息
- SYNC 消息:返回 sync 结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新
3. ObServer 工作流程
ObServer 流程和 Follower 的唯一不同之处是 ObServer 不会参加 Leader 发起的投票,也不会被选举成为 Leader
4. Zookeeper 工作流程
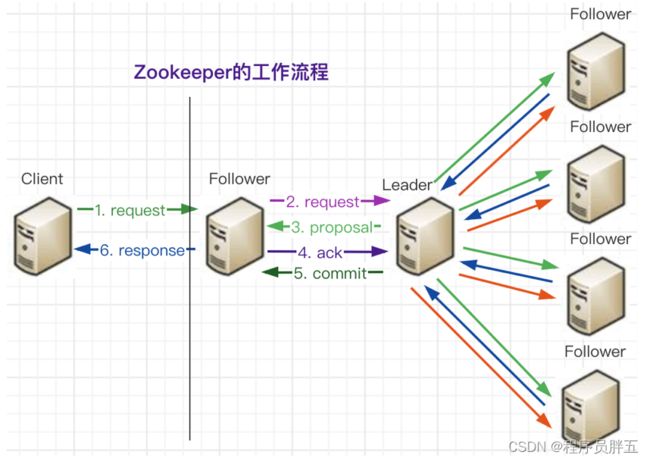
场景一:Client 将写数据请求发到了 Follower
- 首先 Client 向 Follower 发出一个写数据的请求
- Follower 会把该请求转发给 Leader
- Leader 接收到以后开始发起投票并通知 Follower 进行投票
- Follower 把投票结果发给 Leader
- Leader 把结果汇总后,如果需要写入则开始写入,同时把写入操作通知给 Follower,然后 commit
- 当 Follower 中有半数以上写入完成,Leader 会通知 Follower 写入完成,Follower 会响应客户端数据写入完成
场景二:Client 将写数据请求直接发到了 Leader
- Leader 会先将数据写入自身,同时通知其他 Follower 写入
- 当 Follower 中有半数以上响应写入完成,Leader 就会告诉客户端数据写入完成,提前响应了客户端
综合来说:Leader 主要是发起投票决议、更新系统状态;Follower 主要是转发请求、参与投票、返回投票结果。
5. 配置文件 zoo.cfg 详解
-
tickTime:基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime 时间就会发送一个心跳
-
dataDir:存储内存中数据库快照的位置,顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里
-
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
-
initLimit:这个配置项是用来配置 Zookeeper 接受客户端初始化连接时最长能忍受多少个心跳时间间隔数,当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10 * 2000 = 20 秒
-
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 5 * 2000 = 10 秒
-
server.A = B:C:D :
- A 表示这个是第几号服务器
- B 是这个服务器的 ip 地址
- C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口
- D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader
3. Zookeeper 相关操作
1. 命令行操作
进入 zk 客户端
bin/zkCli.sh
# 进入别的机器的zk程序中
zkCli.sh -server hadoop1:2181
查看 ZNode 子节点内容
ls /
ls /Zookeeper
创建 ZNode 节点
create /zk "myData"
获取 ZNode 数据
get /Zookeeper
get /Zookeeper/node1
设置 ZNode 数据
set /zk "myData1"
监听 ZNode 事件
ls /Zookeeper watch # 就对一个节点的子节点变化事件注册了监听
get /Zookeeper watch # 就对一个节点的数据内容变化事件注册了监听
创建临时 ZNode 节点
create -e /zk "myData"
创建顺序 ZNode 节点
create -s /zk "myData"
删除 ZNode 节点
delete /zk # 只能删除没有子ZNode的ZNode
rmr /zk # 不管里边有多少ZNode,统统删除
2. API 操作
创建一个 ZNode,其路径为 path,data 是存储在该 ZNode 上的数据,级别常用的有:
PERSISTENT(持久)
PERSISTENT_SEQUENTAIL
EPHEMERAL(短暂)
EPHEMERAL_SEQUENTAIL
删除一个 ZNode,可通过 version 删除指定的版本,如果 version 是 -1,表示删除所有的版本:
delete(path, verison):
判断指定的 ZNode 是否存在,并设置是否 watch 这个 ZNode。如果要设置 watch,watcher 是在创建 Zookeeper 实例时指定的,如果要设置特定的 watch,可调用另一个重载版本的:
exists(path, watcher):
- 以下几个带 watch 参数的 API 也都类似:
# 读取指定ZNode上的数据,并设置是否watch这个ZNode
getData(path, watch):
# 更新指定ZNode的数据,并设置是否watch这个ZNode
setData(path, watch):
# 获取指定ZNode的所有子ZNode的名字,并设置是否watch这个ZNode
getChildren(path, watch):
把所有在 sync 之前的更新操作都进行同步,达到每个请求都在半数以上的 Zookeeoer Server 上生效:
sync(path): # path参数目前没有用
设置指定 ZNode 的 Acl 信息:
setAcl(path, acl):
获取指定 ZNode 的 Acl 信息:
getAcl(path):