CentOS-7下搭建Hadoop环境
CentOS-7下搭建Hadoop环境
- 前言
- 安装包版本
- ssh免密登录环境搭建
-
- 1.修改网络配置信息
- 2.关闭防火墙
- 3.时间同步
- 4.设置主机名
- 5.hosts设置
- 6.ssh配置
- JAVA安装
- Hadoop配置文件
-
- 1. 解压Hadoop
- 2. 配置env文件
- 3. 配置核心组件文件
- 4. 配置文件系统
- 5. 配置yarn-site.xml
- 6. 配置 MapReduce 计算框架文件
- 7. 配置 Master 和 slaves 文件
- 8. 复制 Master 上的 Hadoop 到 Slave 节点
- 9. 创建 Hadoop 数据目录
- 10. 格式化文件系统 master
- 11. 启动关闭查询
前言
从今天开始正式开启我的博客之旅,书写整理接触程序到现在所用过、解决过、学过的知识,是自我的总结&分享。
Hadoop在大数据技术体系中的地位至关重要,Hadoop是大数据技术的基石,而环境搭建是学习Hadoop的至关重要的第一步,关于虚拟机搭建相关问题本篇后续文字会讲解,那么不说废话了,开始下面的搭建讲解。
安装包版本
虚拟机/服务器数量:3台。
Linux版本——————CentOS-7
Hadoop版本—————hadoop-2.7.5.tar.gz
Java版本 —————— jdk-8u162-linux-x64.tar.gz
ssh免密登录环境搭建
注:以下内容在3台虚拟机都得进行配置。
1.修改网络配置信息
步骤目的:把网络IP改为静态,网络开启开机自启动,为后续host映射做准备。
//1.用这个找到当前Linux系统的IP地址。
ifconfig
//2.用这条指令打开centOS网络配置信息,注:有些网络配置文件名称可能不是“ifcfg-ens33”
vi /etc/sysconfig/network-scripts/ifcfg-ens33
//修改内容如下没有的添加有的修改,注:“IPADDR=”内容写当前系统IP格式与下面相同。
BOOTPROTO=static
ONBOOT=yes
IPADDR=
NETMASK=255.255.255.0
GATEWAY=192.168.112.2
DNS1= 8.8.8.8
DNS2=8.8.8.4
2.关闭防火墙
步骤目的:关闭防火墙,是为了端口的正常访问,在企业开发中是通过设置防火墙端口白名单来实现,想了解的自行百度相应命令。
//3条指令分别为:关闭防火墙、关闭防火墙自启动、查询防火墙。
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
3.时间同步
步骤目的:同步3台虚拟机时间,防止后续Hadoop时间不一样导致运行出错。
//打开配置文件后添加YS_HWLOCK=yes信息保存退出,后执行后面那条指令。
vi /etc/sysconfig/ntpd
YS_HWLOCK=yes
systemclt start ntpd
4.设置主机名
步骤目的:为后续host映射做准备。
//3条指令分别为:查询主机信息、修改主机名、刷新,”主机名“改成要修改的主机名。
//我通常改为:master、slave0、slave1 注:这里改什么后面相应的就要改为你改的内容。
hostnamectl
hostnamectl set-hostname ”主机名“
bash
5.hosts设置
步骤目的:设置主机与ip之间映射,简单来说就是设置当前服务器的电话簿。
//打开etc下hosts文件添加 “ip 主机名”注:ip是3台虚拟机的ip主机名也是对应的主机名。
vi /etc/hosts
192.168.56.110 master
192.168.56.111 slave0
192.168.56.112 slave1
6.ssh配置
步骤目的:设置主机与ip之间映射,简单来说就是设置当前服务器的电话簿。
//第一条创建ssh密钥,敲完按按多次回车,第二条命令把生成的密钥传输给另外的服务器。
//@后面跟着是在hosts里面映射的主机名。
//敲多次回车然后yes回车,root密码。
ssh-keygen
例:ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
//成功就是ssh+主机名不需要输入密码。
JAVA安装
步骤目的:安装Java为后续安装hadoop做准备。
rpm -qa | grep java //进行查询本地Java如果版本低于1.7就用下面的命令卸载Java。
rpm -e --nodeps 软件名 //把需要卸载的软件名填上,我的centos是4个Java要进行删除。
tar -zxvf jdk-8u162-linux-x64.tar.gz//—C 是指定解压目录,这个目录要记住。
vi /root/.bash_profile //打开文件,添加Java环境变量。
#JAVA_HOME//JAVA_HOME=后面是指定Java路径和上面解压路径相同。
export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
export PATH=$PATH:$JAVA_HOME/bin
source /root/.bash_profile //重启环境变量。
java -version //看Java版本是否是你解压的版本即安装成功。
Hadoop配置文件
1. 解压Hadoop
步骤目的:解压到要按照位置,并配置好环境变量,只在master节点操作,配置好在发送到其他节点。
tar -zxvf hadoop-2.7.5.tar.gz //—C 是指定解压目录,这个目录要记住。
mv hadoop-2.7.5 hadoop //修改文件名。
vi /root/.bash_profile//打开文件,添加Hadoop环境变量。
#HADOOP//HADOOP_HOME=后面指定路径和上面解压路径相同。
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source ~/.bash_profile //重启环境变量。
2. 配置env文件
步骤目的:配置Java路径,让hadoop找到java。
vi /opt/hadoop/etc/hadoop/hadoop-env.sh
//这里添加Java安装的路径。
export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
3. 配置核心组件文件
//用vi/vim 编辑器打开hadoop/etc/hadoop 目录下的core-site.xml文件,指令如下供参考。
vi /opt/hadoop/etc/hadoop/core-site.xml
//在和 之间,添加下面配置信息,不解释含义。
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
//这里是配置数据目录路径,如果路径有更改这里也要相应更改。
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
4. 配置文件系统
//用vi/vim 编辑器打开hadoop/etc/hadoop 目录下的hdfs-site.xml文件,指令如下供参考。
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
//在和 之间,添加下面配置信息,不解释含义。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
5. 配置yarn-site.xml
//用vi/vim 编辑器打开hadoop/etc/hadoop 目录下的yarn-site.xml文件,指令如下供参考。
vi /opt/hadoop/etc/hadoop/yarn-site.xml
//在和 之间,添加下面配置信息,不解释含义。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
6. 配置 MapReduce 计算框架文件
//先复制hadoop/etc/hadoop目录下mapred-site.xml.template文件,并改名为mapred-site.xml,
//然后在用vi/vim 编辑器打开mapred-site.xml 指令如下供参考。
cp mapred-site.xml.template mapred-site.xml
vi /opt/hadoop/hadoop/etc/hadoop/ mapred-site.xml
//在和 之间,添加下面配置信息,不解释含义。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
7. 配置 Master 和 slaves 文件
//用vi/vim 编辑器打开hadoop/etc/hadoop 目录下的slaves文件 指令如下供参考。
vi /opt/hadoop/etc/hadoop/slaves
//需要删除原来文件里面localhost那一行,这里的名字是前面定义主机名时候的名字。
slave0
slave1
8. 复制 Master 上的 Hadoop 到 Slave 节点
// 运用指令把主节点搭建好的hadoop 复制到另外从节点。
scp -r /opt/ root@slave0:/opt
scp -r /opt/ root@slave1:/opt
9. 创建 Hadoop 数据目录
//创建数据目录,这里路径要和上面配置一样,否则报错。
mkdir /opt/hadoop/hadoopdata
10. 格式化文件系统 master
//格式化目录,只能格式化一次,第二次格式化会报错,如果有进程出不来可以把数据目录清空!!!
//在进行格式化操作 。
hadoop namenode -format
11. 启动关闭查询
//开启所有:
start-all.sh
//关闭所有:
stop-all.sh
//启动dfs:
start-dfs.sh
//启动Yarn:
start-yarn.sh
//查询进程:
jsp
当节点出现如图所示。
主节点出现如图所示4个进程:
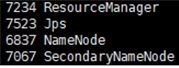
从节点出现如图所示3个进程:
