【Linux】网络原理
计算机网络,贯穿这整个计算机的发展,让我们一起来了解一下网络的基本原理
1.网络发展背景
关于网络发展的历史背景这种东西就不多bb了,网上很容易就能找到参考资料,我的专业性欠缺,文章参考意义也不大。这里只做简单说明。
网络发展经过了如下几个模式
- 独立模式:计算机之间相互独立,靠人移动数据
- 互联模式:多台计算机连接到一起,实现数据共享
- 局域网LAN:计算机数量增多,通过交换机/路由器连接到一起
- 广域网WAN:将相隔距离非常远的计算机连在一起
交换机是啥?简单来说就是一个有很多网口的设备,将设备插上去后(一般用的都是RJ45网线)就能相互交流信息。
我们家用的WIFI路由器其实已经集成了交换机的功能!
1.1 计算机设备之间是怎么交流的?
计算机内部有非常多的设备,在设备和设备之间一定要用“线”进行连接。这样这些设备才能相互通信。比如主板上的总线,链接硬盘的sata线等等。
而这个计算机的结构本质上也能被看作一个小型网络。
此时我们将计算机A和B用数据线连接起来,就能在物理层面上,让A和B相互通信(此时暂且不考虑通过何种方式通信,只要用数据线连起来了,那就一定能通信)
- 在主机内,线短
- 跨主机,线长
当数据线长了之后,线路和线路之间就容易产生信号的干扰,导致数据的错误/丢失。此时我们就需要一个更可靠、高效的方式来实现远距离计算机之间的通信,这就是网络的意义
1.2 集群
进一步扩大,实际上,还可以用多台主机相连,实现单一的功能。这时候,这一堆主机被称为集群
- 存储集群:硬盘
- 缓存集群:内存
- 计算集群:Cpu/Gpu
不同的集群干不同的事,再用数据线连起来,就成了一台由多个主机共同构成的电脑

在大型的数据中心里面,就是用这种方式来处理海量的数据的。
2.协议
协议是一种约定,约定好两台设备要用什么方式来交流。
比如我们都是中国人,可以用普通话这个协议来交流;而广东地区的人,可以用粤语来交流。
计算机之间想交流,肯定也需要确定好一个行业通用的协议!
否则不同计算机的架构/操作系统/硬件设备不一样,若协议不统一,也就无法正常交流。这就好比一个说英语的人听不懂普通话一样。
2.1 分层
网络的协议是分层的
2.1.1 为什么要分层
软件分层,就好比将主代码和功能代码给分开
- 此时只要功能代码提供的接口不变,主代码的调用方式就不变
- 主代码无须关心功能代码是如何处理的,只关心其处理的结果(返回值)
- 工程师修改代码的时候,只需要定位到具体模块进行修改,不会出现牵一发动全身的情况
这样,就实现了主模块和功能模块的解耦
由于网络涉及到了软件到硬件各种层面的设备操作,所以其必须采用分层的协议。不同设备采用不同的协议,才能最大层面的保证网络系统整体不出bug
网络协议有一个特点:同层设备都可以认为自己在直接和对方通信
2.1.2 电话机例子
以下图为例,当俩个人用座机打电话的时候,他们会认为自己在直接和对方交流,而不会认为自己是在和电话机交流
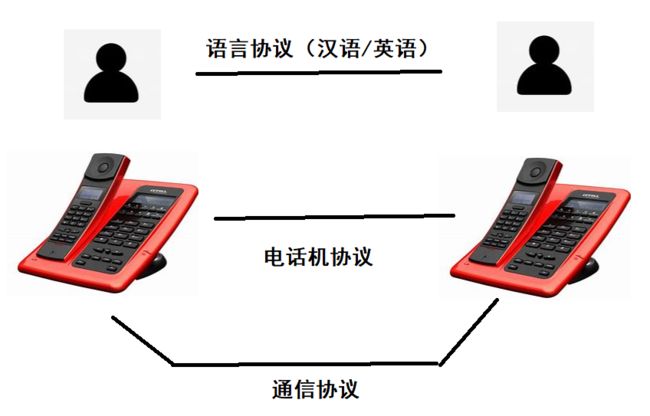
此时,就可以把这个系统分3层:分别是两人之间的语言协议,电话机和电话机之间读取数据的协议,以及最底层用于传输信号的通信协议
- 用户不会去关心电话机用的是什么协议,而是关心自己应该用什么语言和对方交流
- 电话机不会去关心用户是用什么语言交流的,其只负责把收到的声音转换成电信号
- 通信协议不管电话机是怎么封装的,其只负责传输数据
这里就能看出来,不仅同层的设备可以认为自己是直接和对方交流,而且它还不需要管其他层用的是什么协议!
- 电话机不会因为你说英语而用不了
这就是分层实现解耦的效果,也算是每一层都实现了自己的封装
2.2 OSI七层模型
- OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型, 是一个逻辑上的定义和规范;
- 它把网络从逻辑上分为了7层。每一层都有相关、相对应的物理设备,比如路由器,交换机;
- OSI 七层模型是一种框架性的设计方法,其最主要的功能使就是帮助不同类型的主机实现数据传输;
- 它的最大优点是将服务、接口和协议这三个概念明确地区分开来,概念清楚,理论也比较完整。 通过七 个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯

可以用下面的这个表格来简单了解一下每一层的功能
| 分层名称 | 功能 | 概览 |
|---|---|---|
| 应用 | 针对特定应用的协议 | STMP邮件/远程登录/文件传输 |
| 表示 | 数据固有格式和网络标准格式的转换 | 接收不同表现形式的信息 |
| 会话 | 通信管理,负责建立/断开通信连接,维持不同应用程序的通信 | 何时建立/何时断开/建立多久 |
| 传输 | 两个节点之间的数据传输 | 维持传输可靠性 |
| 网络 | 地址管理/路由选择(逻辑寻址 | 确定最佳路径 |
| 数据链路 | 互联设备之间传送和识别数据 | 将数据组合成字节 |
| 物理 | 以01二进制进行数据传输 | 网线 |
但是OSI七层模型相对比较复杂,我们主要关注的还是TCP/IP模型
2.3 TCP/IP
TCP/IP是一组协议的代名词,它其中包括很多协议,组成了一个整体
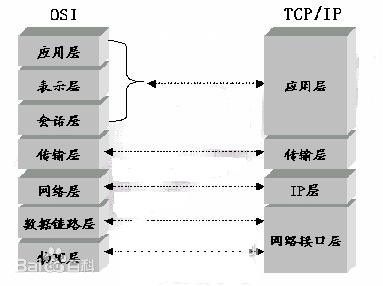
TCP/IP模型可以认为是4/5层,每一层也有自己不同的功能。每一层都会调用另外一层,来实现自己的需求
- 物理层: 负责光/电信号的传递方式。 比如现在以太网通用的网线(双绞 线)、早期以太网采用的的同轴电缆 (现在主要用于有线电视)、光纤, 现在的wifi无线网使用电磁波等都属于物理层的概念。物理层的能力决 定了最大传输速率、传输距离、抗干扰性等。集线器(Hub)工作在物理层
- 数据链路层: 负责设备之间的数据帧的传送和识别。 例如网卡设备的驱动、帧同步(就是说从网线上检测 到什么信号算作新帧的开始)、冲突检测(如果检测到冲突就自动重发)、数据差错校验等工作。 有以太 网、令牌环网, 无线LAN等标准。交换机(Switch)工作在数据链路层
- 网络层: 负责地址管理和路由选择。 例如在IP协议中, 通过IP地址来标识一台主机, 并通过路由表的方式规 划出两台主机之间的数据传输的线路(路由)。路由器(Router)工作在网路层
- 传输层: 负责两台主机之间的数据传输。 如传输控制协议 (TCP), 能够确保数据可靠的从源主机发送到目标 主机
- 应用层: 负责应用程序间沟通,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问 协议(Telnet)等。 我们的网络编程主要就是针对应用层。
为啥这里有5层,却有时候又说是4层呢?
因为物理层关注的较少,所以一般都只注重于剩下的4层
3.网络和操作系统之间的关系
用户的网络请求要想成功发送给对方,那就一定要经过网卡这个硬件;而要经过网卡,那就肯定要经过操作系统——只有操作系统能直接访问硬件!
所以,数据在主机内流动的时候,就一定会从用户走到内核,再最终走到物理层进行传输!
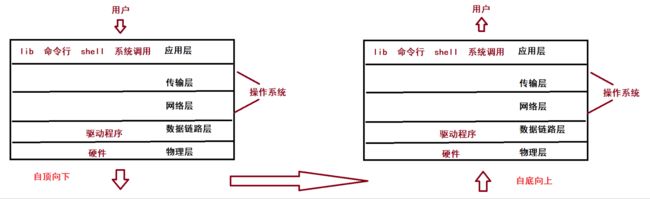
因为计算机的体系结构决定了数据流动的时候,一定要经过操作系统,所以肯定会是自顶向下/自底向上进行流动的!
- 这就引出了二者的关系
网络协议栈是属于操作系统的:在操作系统中,有一个模块就是专门来处理tcp/ip协议的。
前面提到,每一层都可以认为自己是在和对方同层的用户直接通信。这样做是有一定代价的,且听我细细道来。
3.1 快递例子
当我们网购商品的时候,我们作为用户,是直接和商家联系的。下了订单后,商家要去做一系列的操作,最终我们从快递小哥处拿到了商品
| 客户 | 商家 |
|---|---|
| 在商家处下订单 | 接收到用户订单 |
| 从快递员处收到货物 | 将货物交给快递员 |
| 货物运输到集散点 | 货物运输到集散点 |
但,我们收到的快递并不是只有我们要的商品,往往这里面都会多出一些东西

如图,我们的商品被一个盒子包裹着,外头还多了一个快递单
| 客户 | 商家 | |
|---|---|---|
| 在商家处下订单 | 接收到用户订单 | 给出收件地址 |
| 从快递员处收到货物 | 将货物交给快递员 | 添加外箱并填写邮寄单 |
| 货物运输到集散点 | 货物运输到集散点 | 开始运输 |
在这个例子中,每一层其实都给出了自己的独有协议。我们可以把最下面的运输当作物理层。
快递小哥在包装快递的时候,就会给快递增加一个外箱,并填写好邮寄单。当另外一边的快递小哥收到这个货物的时候,就可以更具邮寄单上的信息,将快递送到用户手上。
3.2 报头/解包
此过程中,为了维护快递的出发地/终点地信息,快递员给货物添加上了客户不需要的东西。
- 在网络协议中,每一层协议,都会给我们要传输的数据添加上独有的协议信息,再交付给下一层;这些信息是用来维护数据的(就好比快递单号上的地址)
- 多出来的协议数据被称为:报头
- 收到信息后,同层协议会取出自己的那份协议信息进行分析,再交付给上一层
- 拆开数据的过程被称为:解包
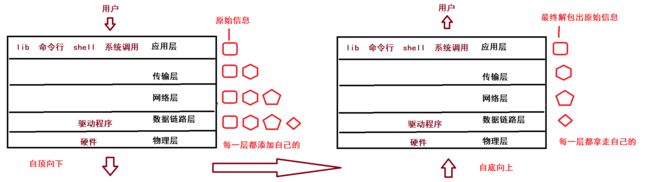
不知道快递的例子能否帮助你理解这个过程

3.3 报头的作用
数据会有不同的应用,也对应了不同的协议。在封包的时候,添加的报头信息里面就应包含目标的协议信息
- 比如我的信息是SMTP邮箱信息,那么在目标主机接收到进行解包了以后,也需要将这个信息交给支持SMTP的邮箱软件进行处理
- 报头属性里面就需要包含支持分用的属性(还有一些公共属性)
- 报头属性里面还需要包含区分
有效载荷和报头的属性,也就是将要发送的数据,和这一层的报头给拆开,不能到时候分不出来,无法正常解包了
这个过程就是一个分用的过程,我们传送的信息,被称为有效载荷

快递点也是一样,如果快递点收到的都是商品而没有快递单,快递小哥也就无法知道快递应该送给谁了
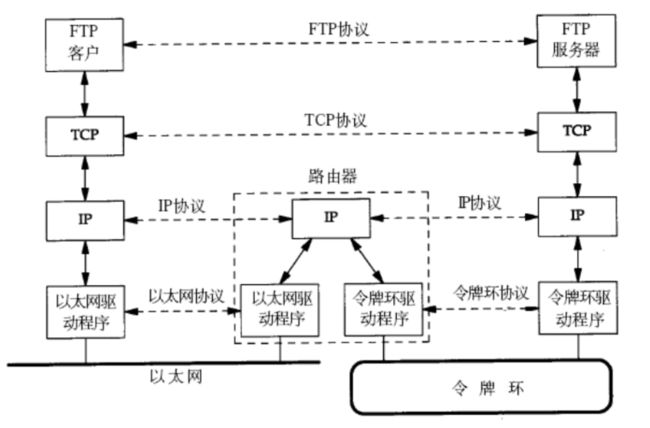
4.局域网
以太网的命名来自物理学中的以太,这部分的故事可以百度️大学物理课上也讲过。
- 如果两台主机,处于同一局域网中,他们之间能通信吗?
- 和同学开手机热点联机MC的经历告诉我,是可以的
4.1 MAC地址
局域网就好比一个餐厅,里面有很多人在聊天。当你在餐厅里面和张三聊天的时候,旁边的人也能听到你们俩交流的内容。局域网内也是如此。
要想在局域网内准确地找到一个设备,那就需要一个唯一标识码。就好比想在教室里面找到一个人,需要知道名字一样(排除同名问题)
每台主机唯一的标识码,就是该主机对应的MAC地址
- MAC地址用来识别数据链路层中相连的节点
- 长度为48位, 及6个字节。 一般用16进制数字加上冒号的形式来表示(例如:
08:01:27:04:fb:19) - MAC地址在网卡出厂时就确定了,不能修改! 且mac地址通常是唯一的(虚拟机中的mac地址不是真实的mac地址,可能会冲突;也有些网卡支持用户配置mac地址)
局域网内没有发送限制,任何一台主机随时都可发送消息。此时还需要引入碰撞检测机制,在没有人发送信号的时候,本设备再发送信号。避免多台主机通信时,出现信号撞到一起(碰撞域)而导致的信息丢失。
以系统编程的角度来看,此时的局域网可以认为是一个临界资源。保证数据不被碰撞,就是保护临界资源的一致性!
4.2 通信原理
和前面提到的报头/解包一样,局域网内的数据,也是自顶向下、自底向上流动的。
每一层都有自己的协议,也需要加上自己的报头
5.广域网
在广域网内通信就没有那么简单了。这就好比唐僧去西天取经,不是直接走到西天的,而是需要经过多个驿站(中途地点)
在广域网内通信,我们则是通过ip地址来做驿站,来查找目标主机的
- 在局域网内用的是mac来标识目标的唯一性
- 广域网内采用ip来标识目标的唯一性
5.1 IP地址
IP协议有两个版本,IPv4和IPv6(本文只关注v4)
IP地址是在IP协议中,用来标识网络中不同主机的地址;
对于IPv4来说,IP地址是一个4字节,32位的整数。通常使用 “点分十进制” 的字符串表示IP地址, 例如 192.168.0.1;用点分割的每一个数字表示一个字节, 范围是 0 - 255;
因ipv4的规定的局限性,ipv4的ip现在已经逐渐枯竭,很多地方的运营商已经不提供家用宽带的公网IP地址。
5.2 通信过程
在广域网通信的时候,每次都需要提供源IP和目标IP,这就是从哪儿来/到哪儿去;同时,还需要提供源MAC和目标MAC进行标识。
在通信过程中,会有路由器来告诉你应该去哪儿。在这期间,我们的数据会在不同的局域网内进行切换。
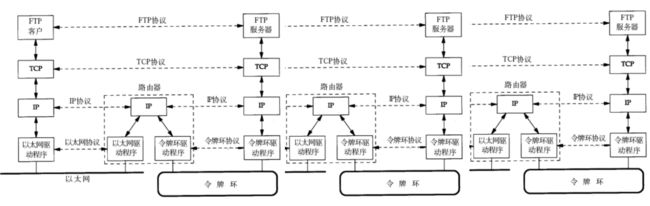
在切换过程中,路由器会更新你的源IP/MAC(目标IP不变)并提供目标的MAC地址
唐僧去西天取经,他的目的地是不会变的,但是上一站/下一站会不断变化
以下图为例,当我们的数据走到IP这一层时,就会加上IP协议的报头。并在路由器内进行解包,再换上新的IP报头。

此时IP一层就可以和其他层区分开,因为在IP层之上,发送/接收主机收到的数据是完全一样的!
IP层是一个软件层,任何底层的差异,都可以通过加一层软件层来解决。这是一种
软件虚拟化技术,linux的文件系统也使用了这种技术
也就是说,通过IP层,可以屏蔽底层网络的差距。在通过ip通信的时候,不需要关注底层的路由等硬件信息以及数据传输的实现。
5.3 端口
一台主机里面有非常多的进程,每一个进程都能访问网络发送信息。
光用IP地址,我们实际上只能找到对应的主机,却无法确定是这台主机里面的xx应用发出的信息。
此时,就需要利用端口号来确定我们要访问的进程是什么了。
- IP:确保主机唯一性
- 端口port:确保该主机上的进程唯一性
如果你有用过docker,那肯定就知道端口号这一存在。大部分docker都需要映射一个端口以对外提供服务。
网络间的通信,本质上是不同主机上的进程通信
- 端口号是一个2字节的整数,限定了端口范围(1-65,536)
- 端口号用于标识一个进程,告诉系统,当前的数据应交给哪一个进程去运行
- 同一个进程可以使用多个端口号
- 但是一个端口号只能对应一个进程
网络通信中,有源IP和目标IP,也有源端口和目标端口。我们把这一对IP+端口被称为socket对
5.3.1 端口/PID的关系
在一台主机里面,PID也可以用于标识唯一的进程。但是,端口号和PID是属于两个完全不同的概念。
假设餐厅里有一个扫把,餐厅雇了个保洁员A,让他来打扫餐厅的卫生。此时就可以把扫把认为是端口,保洁员A是一个进程。
有一天,保洁员A生病了,请假一周。于是老板又请了一个保洁员B,让他来打扫一周的卫生。此时,保洁员B也能使用餐厅里面已有的扫把,来进行打扫工作
- 保洁员A/保洁员B干的工作是完全一致的
- 他们使用的是同一个扫把
我们知道,在linux中,一个同一个可执行程序,每一次执行的时候,它的进程PID都是不同的;但同一个可执行程序,干的活肯定是一样的。
保洁员A和B就可以看作是同一个可执行程序,他们用的也是同一个端口(扫把),但保洁员A和B的进程PID是不一样的!
所以,在网络通信的时候,采用了端口这个扫把来标识需要进行网络通信的进程,而不是继续采用PID来标识
操作系统只需要维护一个端口号和进程的哈希表,就能快速地通过端口号找到对应的进程
5.4 TCP/UDP
TCP(Transmission Control Protocol 传输控制协议)
- 传输层协议
- 有链接(必须要和目标建立连接,才能开始数据传输)
- 可靠传输(检查是否有丢包,需要保证数据完全被传输到目标主机)
- 面向字节流
UDP(User Datagram Protocol 用户数据报协议)
- 传输层协议
- 无连接(无须建立连接,比如所有人都能给你的电子邮箱发送邮件)
- 不可靠传输(不检查丢包)
- 面向数据报
6.网络字节序
在之前学习int类型的存储的时候,提到过大端/小端的概念
6.1 说明
在网络中,数据流同样有大端小端之分。TCP/IP协议规定,网络数据流应该采用大端字节序(低地址高字节)后发出的数据是高地址
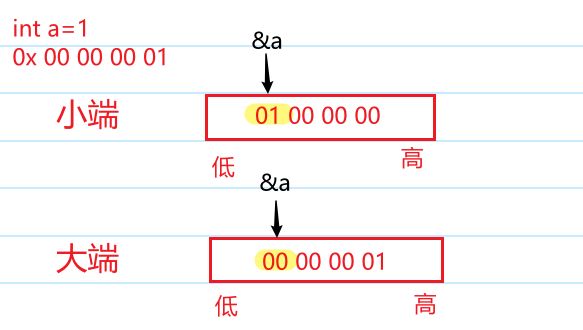
如上图的1为例,当网络中发送这个数字1的时候,会先发送00 00 00,最后发送的是01。这样能够方便数据的拼接
- 发送主机将缓冲区中的数据按内存地址从低到高的顺序发出
- 接受主机把数据依次保存到缓存区中,也是按地址从低到高的顺序保存
这个规定更重要的意思是,如果不对网络字节数据的大小端做出限制,那么网络里面就会出现既有大端又有小端的情况,得写俩套代码来处理这个问题。
而限制为大端之后,小端机器就需要在发送信息之前将数据转为大端,在接收到数据之后,将数据转换为小端。此时的处理就是操作系统的工作了,和TCP/IP协议本身没有关系了