YOLOv8-pose在ncnn框架下部署过程记录(包含ncnn、pnnx安装以及模型结构更改及转换)
目录
1.YOLOv8-pose转onnx模型
2.ncnn编译
3. 方案一:onnx转ncnn
4. 方案二:使用pnnx对模型进行转换
4.1 在pnnx官网下载可执行文件,进行测试
4.2 参照pnnx官网教程进行编译
4.3 下载最新ncnn进行编译
4.3.1 ncnn编译
4.3.2 pnnx编译
4.4 模型使用pnnx进行转换
4.4.1 torchscript生成
4.4.2 使用pnnx对torchscript进行转换
5 终极方案:更改模型结构
5.1 生成只有backbone和neck部分的onnx
5.2 生成*.bin和*.param
5.3 对模型推理结果进行解析
1.YOLOv8-pose转onnx模型
参照官网GitHub - ultralytics/ultralytics: NEW - YOLOv8 in PyTorch > ONNX > CoreML > TFLite,安装ultralytics后,转onnx模型
(1)安装ultralytics
|
|
(2)转onnx代码
|
|
2.ncnn编译
在ncnn官网GitHub - Tencent/ncnn: ncnn is a high-performance neural network inference framework optimized for the mobile platform下载ncnn,进行编译,可以选用cmake-gui,更直观写,编译时注意要将NCNN_BUILD_TOOLS和NCNN_VULKAN勾选上,勾选NCNN_BUILD_TOOLS可以生成转模型的工具,勾选NCNN_VULKAN可以使NCNN选用GPU进行推理。
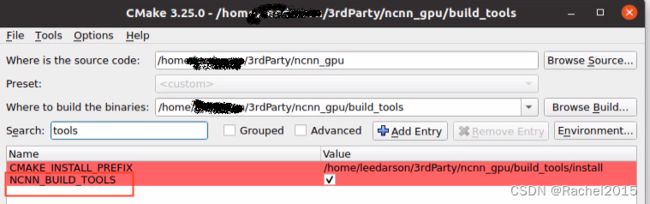

配置完成后,进行make和install
|
|
3. 方案一:onnx转ncnn
使用ncnn生成的onnx2ncnn工具生成相应的模型和参数,参考命令如下
|
|

报出了该问题,当时看依旧生成了*.param和*.bin,就没管强行进行优化
|
|
注意:这里的参数最后的flag指的是fp32和fp16,其中0指的的是fp32,1指的是fp16,FP16、FP32速度耗时一般情况下:GPU使用FP16模型 后来在使用ncnn加载模型的时候就报了错,报错依旧是scatterND无法支持。然后网上查阅资料才明白原来ncnn不支持scatterND算子,所以转ncnn模型时会报错,而之前转tensorRT的engine时没有该问题是因为tensorRT已支持scatterND算子。 参考 关于ncnn转换focus模块报错Unsupported slice step !_何33512336的博客-CSDN博客 原因:ncnn不支持scatterND算子。 解决思路:尝试先将模型解析为TorchScript(torchscript可以将深度学习中一些复杂的处理算子解析为由多个简单算子组合的复杂算子来完成计算),然后使用pnnx转为ncnn可以解析的模型。 尝试下载在pnnx官网下载可执行文件,测试运行失败 采用chmod +x更改pnnx权限后依旧失败 5分钟学会!用 PNNX 转换 TorchScript 模型到 ncnn 模型 - 知乎 参照官网GitHub - pnnx/pnnx: PyTorch Neural Network eXchange给出的如下教程,对旧版本ncnn进行编译,依旧失败报错 报错如下: 怀疑ncnn版本太旧了,下载最新ncnn,进行如下步骤 参照官网how to build · Tencent/ncnn Wiki · GitHub ,下载最新ncnn,进行编译 cmake时,按照cmake提示执行以下命令 考虑需要使用GPU进行推理,以及需要使用tools中的编译工具,做了如下更改,参考上述步骤2,将NCNN_BUILD_TOOLS/ NCNN_VULKAN/ 勾选上 configure无误后进行make和make install 至此,ncnn编译成功。 参照pnnx官网GitHub - pnnx/pnnx: PyTorch Neural Network eXchange教程进行编译 DTorch_INSTALL_DIR为本机torch安装目录 torch安装目录查找方法 大概三四十分钟,编译完成,可以看到在ncnn/tools/pnnx/build/src目录下生成了pnnx可执行文件,参照4.1步骤进行测试, 得到了如下5个新增文件,pnnx安装成功。 参考400 行代码玩转 YOLOv8 检测/分割/关键点 NCNN 部署 - 知乎,给出的方案,尝试对yolov8-pose模型只导出模型的backbone和neck部分结果,不加后处理如anchor解析、nms等,解决许多推理后端对后处理算子支持差的问题。 参照GitHub - triple-Mu/yolov8 at triplemu/model-only给出的示例,生成只有backbone和neck部分的模型 作者triplemu对yolov8做了如下更改 最终输出形状 参考步骤3,使用编译ncnn生成的onnx2ncnn工具或在线转换一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine 命令如下 参照5.1步骤中的模型结构图,按照116 表示 yolov8s-pose的fp16解析结果见下图。 相关代码已上传,见如下链接,如果有帮助,麻烦给个star!谢谢。 https://download.csdn.net/download/Rachel321/87755279 https://github.com/Rachel-liuqr/yolov8s-pose-ncnn
详细记录u版YOLOv5目标检测ncnn实现 - 知乎
实践教程|YOLOX目标检测ncnn实现4. 方案二:使用pnnx对模型进行转换
4.1 在pnnx官网下载可执行文件,进行测试
import torchimport torchvision.models as models#net = models.resnet18(pretrained=True)net = models.mobilenet_v2(pretrained=True)net = net.eval()x = torch.rand(1, 3, 224, 224)mod = torch.jit.trace(net, x)torch.jit.save(mod, "mobilenet_v2.pt")
4.2 参照pnnx官网教程进行编译


4.3 下载最新ncnn进行编译
4.3.1 ncnn编译
cd ncnnmkdir -p buildcd buildcmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=../toolchains/jetson.toolchain.cmake -DNCNN_VULKAN=ON -DNCNN_BUILD_EXAMPLES=ON ..make -j$(nproc)
git submodule update --init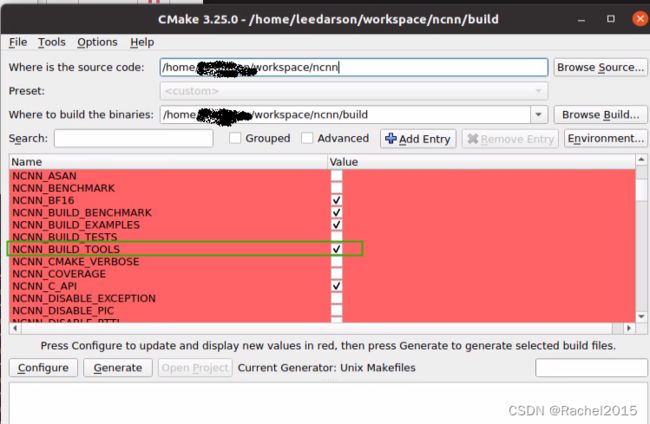

4.3.2 pnnx编译
mkdir ncnn/tools/pnnx/buildcd ncnn/tools/pnnx/buildcmake -DCMAKE_INSTALL_PREFIX=install -DTorch_INSTALL_DIR=cmake --build . --config Release -j 2cmake --build . --config Release --target install
import torchprint(torch.__path__)
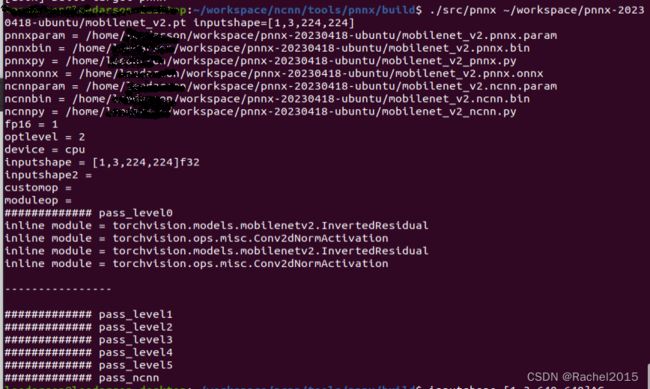
mobilenet_v2.ncnn.binmobilenet_v2.ncnn.parammobilenet_v2.pnnx.binmobilenet_v2.pnnx.parammobilenet_v2.py4.4 模型使用pnnx进行转换4.4.1 torchscript生成参考代码如下
from ultralytics import YOLO# Load a modelmodel = YOLO("pt/yolov8n-pose.pt") # load a pretrained model (recommended for training)success = model.export(format="torchscript", simplify=True) # export the model to onnx formatassert success4.4.2 使用pnnx对torchscript进行转换执行命令如下
./pnnx /home/path/to/yolov8s-pose.torchscript inputshape=[1,3,640,640]依旧报错
user@user-desktop:~/workspace/ncnn/tools/pnnx/build/src$ ./pnnx ~/workspace/YOLOv8-TensorRT/yolov8s-pose.torchscript inputshape=[1,3,640,640]pnnxparam = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose.pnnx.parampnnxbin = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose.pnnx.binpnnxpy = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose_pnnx.pypnnxonnx = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose.pnnx.onnxncnnparam = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose.ncnn.paramncnnbin = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose.ncnn.binncnnpy = /home/user/workspace/YOLOv8-TensorRT/yolov8s-pose_ncnn.pyfp16 = 1optlevel = 2device = cpuinputshape = [1,3,640,640]f32inputshape2 =customop =moduleop =############# pass_level0inline module = ultralytics.nn.modules.Bottleneckinline module = ultralytics.nn.modules.C2finline module = ultralytics.nn.modules.Concatinline module = ultralytics.nn.modules.Convinline module = ultralytics.nn.modules.DFLinline module = ultralytics.nn.modules.Poseinline module = ultralytics.nn.modules.SPPFinline module = ultralytics.nn.modules.Bottleneckinline module = ultralytics.nn.modules.C2finline module = ultralytics.nn.modules.Concatinline module = ultralytics.nn.modules.Convinline module = ultralytics.nn.modules.DFLinline module = ultralytics.nn.modules.Poseinline module = ultralytics.nn.modules.SPPF----------------############# pass_level1unknown Parameter value kind prim::Constant of TensorType, t.dim = 2unknown Parameter value kind prim::Constant of TensorType, t.dim = 2unknown Parameter value kind prim::Constant of TensorType, t.dim = 2unknown Parameter value kind prim::Constant of TensorType, t.dim = 2unknown Parameter value kind prim::Constant of TensorType, t.dim = 2unknown Parameter value kind prim::Constant of TensorType, t.dim = 2############# pass_level2############# pass_level3############# pass_level4############# pass_level5make_slice_expression input 206make_slice_expression self 207make_slice_expression src 209make_slice_expression input 210make_slice_expression self 214make_slice_expression src 216make_slice_expression input 217make_slice_expression self 221make_slice_expression src 223############# pass_ncnnforce batch axis 233 for operand 212force batch axis 233 for operand 219force batch axis 233 for operand pnnx_expr_35_sub(212,5.000000e-01)force batch axis 233 for operand pnnx_expr_9_sub(219,5.000000e-01)binaryop broadcast across batch axis 0 and 233 is not supportedbinaryop broadcast across batch axis 0 and 233 is not supportedbinaryop broadcast across batch axis 0 and 233 is not supportedbinaryop broadcast across batch axis 0 and 233 is not supportedbinaryop broadcast across batch axis 0 and 233 is not supportedselect along batch axis 0 is not supportedselect along batch axis 0 is not supportedslice with step 3 is not supportedslice with step 3 is not supportedslice with step 3 is not supportedslice_copy with step 3 is not supportedslice_copy with step 3 is not supportedslice_copy with step 3 is not supportedignore Crop select_0 param dim=0ignore Crop select_0 param index=0ignore Crop select_1 param dim=0ignore Crop select_1 param index=1看来使用torchscript对模型中的算子进行转换后,使用pxnn进行模型转换,这条路行不通,pnnx依旧对torchscript中的部分算子无法支持。5 终极方案:更改模型结构5.1 生成只有backbone和neck部分的onnx

执行如下代码,生成onnx
from ultralytics import YOLO# load a pretrained model#model = YOLO('yolov8n.pt')model = YOLO('yolov8s-pose.pt')# model = YOLO('yolov8n-seg.pt')# predict on an imageresults = model('ultralytics/assets/bus.jpg', show=True, save=False)# export onnxmodel.export(format='onnx', opset=11, simplify=True, dynamic=False, imgsz=640)

BxHxWx116,116 表示 1 类分数 + 64 dfl 回归参数 + 51 关键点预测参数。由于关键点只有人回归,因此类别是 1,51 个回归预测表示 17 组 x,y,score 。5.2 生成*.bin和*.param
./tools/onnx/onnx2ncnn ~/workspace/YOLOv8-TensorRT/yolov8s-pose.onnx ~/Two_Wheel_Car/src/yolov8s-pose.param ~/Two_Wheel_Car/src/yolov8s-pose.bin./tools/ncnnoptimize ~/Two_Wheel_Car/src/yolov8s-pose.param ~/Two_Wheel_Car/src/yolov8s-pose.bin ~/Two_Wheel_Car/src/yolov8s-pose-opt.param ~/Two_Wheel_Car/src/yolov8s-pose-opt.bin 15.3 对模型推理结果进行解析
1 类分数 + 64 dfl 回归参数 + 51 关键点预测参数的存放顺序以及8/16/32的尺度变化对推理结果进行解析,注意数据的存放顺序,完成最后的解析工作。