目标检测算法:YOLO v1论文解读
目标检测算法:YOLO v1论文解读
前言
其实网上已经有很多很好的解读各种论文的文章了,但是我决定自己也写一写,当然,我的主要目的就是帮助自己梳理、深入理解论文,因为写文章,你必须把你所写的东西表达清楚而正确,我认为这是一种很好的锻炼,当然如果可以帮助到网友,也是很开心的事情。
说明
如果有笔误或者写错误的地方请指出(勿喷),如果你有更好的见解也可以提出,我也会认真学习。
原始论文地址
点击这里,或者复制链接
https://arxiv.org/abs/1506.02640
目录结构
文章目录
-
- 目标检测算法:YOLO v1论文解读
-
- 1. 文章内容概述:
- 2. YOLO流程介绍:
- 3. CNN架构:
- 4. 损失函数:
- 5. 注意点:
- 6. 总结:
1. 文章内容概述:
作者提出了一种新的目标检测方法,是一种单阶段检测方法,称其为YOLO,全称为You only look once。这个方法的主要特点是不再生成区域建议框,而是全部交给网络架构来实现,是真正的端到端结构(其实并不是严格意义上的端到端,因为还需要进行后处理操作)。
正是因为没有了区域建议框的生成,其运行速度非常快,可以实现实时检测,但是同样的,其mAP和最先进的检测方法Faster-RCNN比还是较低。
2. YOLO流程介绍:
如果你看了我之前的关于RCNN、Fast-RCNN、Faster-RCNN的解读,你马上就会感概,YOLO真的好简单。
论文原图如下:

对上图进行简单的说明:
- 首先,将输入图片改变大小(一般是取大的分辨率,文中取得的是448*448)
问题:为什么要取大分辨率图像?
因为检测问题需要更细致的信息,因此提高分辨率。
- 然后,将该图片传输给CNN架构,然后产生输出(即预测框和类别预测信息)
3. CNN架构:
这里作者自己设计了CNN架构,当然,对于读了这么多的CNN架构论文来说,小case(如果你是无基础直接看的话,当我没说,此时建议你可以先看看基础的)。
论文原图如下:
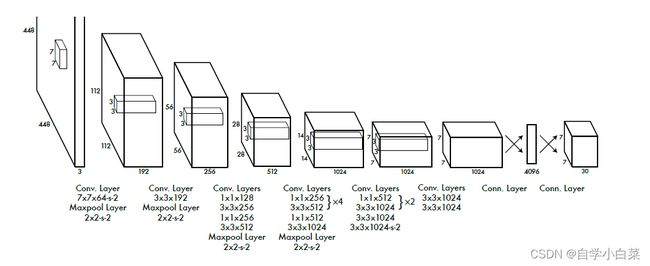
具体的网络架构就不谈了,只是要注意,其实网络架构中用到了激活函数,并且不是我们常规的ReLu激活函数,而是leaky relu(最后一层还是relu):

另外,需要注意它的输出,**这是最重要的部分。**因为它的输出和我们平时的输出不一样,因为无论是图像分类的架构,还是之前的两阶段检测算法,输出就没有三维结构的。
那么,7*7*30是什么意思?下面先分开解释,再结合一起解释。
解释:7*7含义
作者将一张图像划分为S*S个网格,如下图(S=7):

作者认为:
- 如果某个物体对象中心落在某一网格中,那么该网格就负责该对象的检测
- 每个单元格预测B个边界框和其对应的置信度分数,以及一组类概率(比如总共20个类别,则产生20个概率值)
其中,置信度公式和概率公式分别如下,其中Pr(object)取{0,1},表示该网格有对象,则取值为1,否则取值为0。

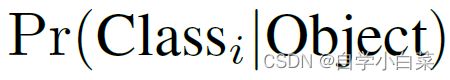
解释:30含义
30=(4+1)*2+20,其中4和1分别表示4个坐标值(x,y,w,h)和一个置信度分数;2表示每个单元格预测2个边界框,那么自然需要乘以2;20是因为数据集共20个类别。
解释:7*7*30怎么才能满足我们的要求?
神经网络的神奇之处,就是在于我们可以让它去适应任意的任务。比如这里,我们需要它按照我们的想象输出7*7*30,并且这里的值必须为我们所想的(比如30里面为坐标值、概率值等)。想要让它输出和我们想得一样,就必须让它在训练的时候,告诉它,30里面的值我们要用来生成预测框和判断类别。而,这个控制它的过程,就是定义一个优秀的损失函数,让7*7*30的值各有所用。
4. 损失函数:
原文中,给出的损失函数公式如下:
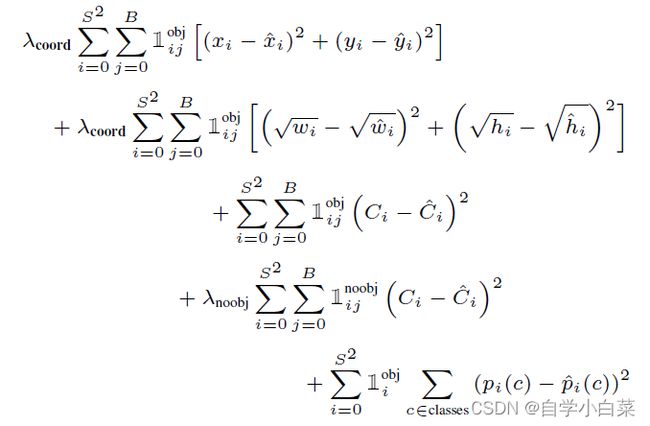
下面进行一一解读:
1[上标:obj,下标:ij] 、 1[上标:noobj,下标:ij] 和 1[上标:obj,下标:i] 含义:
1[上标:obj,下标:i],表示如果对象在单元格i中,则取值为1,否则取值为0。
1[上标:obj,下标:ij],表示如果对象在单元格i的第j个边界框中,则取值为1,否则取值为0。
1[上标:noobj,下标:ij],与上面恰好相反,即如果对象没有出现在单元格i的第j个边界框中,则取值为1,否则取值为0。
S和B 含义:
S就是一张图片划分为多少个单元格,文中为7*7。
B就是一个单元格有B个边界框预测,文中为2。
xi、yi、wi、hi、Ci、pi© 含义:
xi、yi、wi、hi就是中心点坐标值和预测框的宽高。
Ci是预测框的置信度分数,公式上面已经给过了。
pi© (小写c)是一个边框的一组概率值(向量)。
在这些变量上加上*号,表示为真实值。
λcoord,λnoobj 含义:
这两个值是超参数,主要是平衡值。因为,不包含对象的预测框肯定是多数,这会导致计算损失时,值失衡。因此一般会让λcoord值取得比较大,比如5,λnoobj取得比较小,比如0.5。
各行表达式的含义:
第一行+第二行 = 预测框(有对象的预测框)的回归损失,可以看出采取的时类似于MSE的损失,准确来说,后面所有的损失都采取的类似MSE的损失(这是一个缺点,分类损失还是用交叉熵好一点)。
第三行+第四行 = 分别为有无对象的预测框的置信度损失值。
第五行 = 分类损失值。
5. 注意点:
在上面写的时候,有一句”如果某对象的中心落在某单元格,则这个单元格负责该对象的检测“。而在后面中,经常会有”如果某对象落在第i个单元格中“,这里对象落在某单元格就是指的是对象中心落在单元格中。
另外,一个单元格有多个框,是否所有框都负责对象?不是的,而是IOU最大的负责预测,这样可以让不同的框产生不同的作用,有利于提高召回率。
6. 总结:
YOLO的特殊之处在于损失函数的构建和网络输出的利用。不过YOLO v1仍然有许多的缺点,比如预测框太少(7*7*2=98个)、损失函数中分类没有交叉熵损失等等。
不过,YOLO相比于两阶段检测方法,的确很简单,这也是它的一大优点。