DGL分布式训练图划分函数
''' Partition a graph for distributed training and store the partitions on files.
The partitioning occurs in three steps: 1) run a partition algorithm (e.g., Metis) to
assign nodes to partitions; 2) construct partition graph structure based on
the node assignment; 3) split the node features and edge features based on
the partition result.
When a graph is partitioned, each partition can contain *HALO* nodes, which are assigned
to other partitions but are included in this partition for efficiency purpose.
In this document, *local nodes/edges* refers to the nodes and edges that truly belong to
a partition. The rest are "HALO nodes/edges".
划分分三步进行:1)运行划分算法(例如Metis)以将节点分配给分区;2)构建基于节点分配的划分图结构
3)根据分区结果分割节点特征和边特征。
当一个图被分区时,每个分区可以包含*HALO*节点,这些节点被分配
其他分区,但为了提高效率,将其包含在此分区中。
在本文中,*local节点/边*指的是真正属于一个partition。剩下的就是“HALO 节点/边”。
分区数据存储在多个文件中,组织如下:
.. code-block:: none
data_root_dir/
|-- graph_name.json # partition configuration file in JSON
|-- node_map.npy # partition id of each node stored in a numpy array (optional)
|-- edge_map.npy # partition id of each edge stored in a numpy array (optional)
|-- part0/ # data for partition 0
|-- node_feats.dgl # node features stored in binary format
|-- edge_feats.dgl # edge features stored in binary format
|-- graph.dgl # graph structure of this partition stored in binary format
|-- part1/ # data for partition 1
|-- node_feats.dgl
|-- edge_feats.dgl
|-- graph.dgl
首先,原始图和分区的元数据存储在一个JSON文件中
以“图形名称”命名。这个JSON文件包含原始图形的信息
以及存储每个分区的文件的路径。下面展示一个例子。
First, the metadata of the original graph and the partitioning is stored in a JSON file
named after ``graph_name``. This JSON file contains the information of the original graph
as well as the path of the files that store each partition. Below show an example.
.. code-block:: none
{
"graph_name" : "test",
"part_method" : "metis",
"num_parts" : 2,
"halo_hops" : 1,
"node_map": {
"_U": [ [ 0, 1261310 ],
[ 1261310, 2449029 ] ]
},
"edge_map": {
"_V": [ [ 0, 62539528 ],
[ 62539528, 123718280 ] ]
},
"etypes": { "_V": 0 },
"ntypes": { "_U": 0 },
"num_nodes" : 1000000,
"num_edges" : 52000000,
"part-0" : {
"node_feats" : "data_root_dir/part0/node_feats.dgl",
"edge_feats" : "data_root_dir/part0/edge_feats.dgl",
"part_graph" : "data_root_dir/part0/graph.dgl",
},
"part-1" : {
"node_feats" : "data_root_dir/part1/node_feats.dgl",
"edge_feats" : "data_root_dir/part1/edge_feats.dgl",
"part_graph" : "data_root_dir/part1/graph.dgl",
},
}
以下是分区配置文件中字段的定义:
*“图形名称”是用户给定的图形名称。
part _ method”是用于将节点分配给分区的方法。
目前支持“随机”和“metis”。
num _ parts”是分区的数量。
halo _ hops”是我们作为halo节点包含在分区中的节点的跳数。
node _ map”是节点分配图,它告诉一个节点被分配到的分区ID。
“节点图”的格式描述如下。
edge _ map”是边缘分配图,它告诉分区ID边缘被分配到哪个分区。
*“节点数”是全局图中的节点数。
*“边数”是全局图中的边数。
* `part-* `存储分区的数据。
如果“reshuffle=假”,则分区的节点id和边id 在ID范围不连续
。在这种情况下,DGL存储节点/边映射(来自节点/边id到分区id)存储在单独的文件(node_map.npy和edge_map.npy)中。节点/边映射存储在numpy文件中。
..警告:
这种格式已被弃用,下一版本将不再支持。换句话说,
未来的版本在划分一个图时总是会打乱节点id和边id。
如果“重新洗牌=真”,“节点映射”和“边映射”包含全局节点/边id到分区本地节点/边id之间的映射信息。对于异构图,“节点图”和“边图”中的信息也可用于计算节点类型和边类型。“节点图”和“边图”中的数据格式如下:
{
"node_type": [ [ part1_start, part1_end ],
[ part2_start, part2_end ],
... ],
...
},
Here are the definition of the fields in the partition configuration file:
* ``graph_name`` is the name of the graph given by a user.
* ``part_method`` is the method used to assign nodes to partitions.
Currently, it supports "random" and "metis".
* ``num_parts`` is the number of partitions.
* ``halo_hops`` is the number of hops of nodes we include in a partition as HALO nodes.
* ``node_map`` is the node assignment map, which tells the partition ID a node is assigned to.
The format of ``node_map`` is described below.
* ``edge_map`` is the edge assignment map, which tells the partition ID an edge is assigned to.
* ``num_nodes`` is the number of nodes in the global graph.
* ``num_edges`` is the number of edges in the global graph.
* `part-*` stores the data of a partition.
If ``reshuffle=False``, node IDs and edge IDs of a partition do not fall into contiguous
ID ranges. In this case, DGL stores node/edge mappings (from
node/edge IDs to partition IDs) in separate files (node_map.npy and edge_map.npy).
The node/edge mappings are stored in numpy files.
.. warning::
this format is deprecated and will not be supported by the next release. In other words,
the future release will always shuffle node IDs and edge IDs when partitioning a graph.
If ``reshuffle=True``, ``node_map`` and ``edge_map`` contains the information
for mapping between global node/edge IDs to partition-local node/edge IDs.
For heterogeneous graphs, the information in ``node_map`` and ``edge_map`` can also be used
to compute node types and edge types. The format of the data in ``node_map`` and ``edge_map``
is as follows:
.. code-block:: none
{
"node_type": [ [ part1_start, part1_end ],
[ part2_start, part2_end ],
... ],
...
},
Essentially, ``node_map`` and ``edge_map`` are dictionaries. The keys are
node/edge types. The values are lists of pairs containing the start and end of
the ID range for the corresponding types in a partition.
The length of the list is the number of
partitions; each element in the list is a tuple that stores the start and the end of
an ID range for a particular node/edge type in the partition.
The graph structure of a partition is stored in a file with the DGLGraph format.
Nodes in each partition is *relabeled* to always start with zero. We call the node
ID in the original graph, *global ID*, while the relabeled ID in each partition,
*local ID*. Each partition graph has an integer node data tensor stored under name
`dgl.NID` and each value is the node's global ID. Similarly, edges are relabeled too
and the mapping from local ID to global ID is stored as an integer edge data tensor
under name `dgl.EID`. For a heterogeneous graph, the DGLGraph also contains a node
data `dgl.NTYPE` for node type and an edge data `dgl.ETYPE` for the edge type.
The partition graph contains additional node data ("inner_node" and "orig_id") and
edge data ("inner_edge"):
* "inner_node" indicates whether a node belongs to a partition.
* "inner_edge" indicates whether an edge belongs to a partition.
* "orig_id" exists when reshuffle=True. It indicates the original node IDs in the original
graph before reshuffling.
Node and edge features are splitted and stored together with each graph partition.
All node/edge features in a partition are stored in a file with DGL format. The node/edge
features are stored in dictionaries, in which the key is the node/edge data name and
the value is a tensor. We do not store features of HALO nodes and edges.
When performing Metis partitioning, we can put some constraint on the partitioning.
Current, it supports two constrants to balance the partitioning. By default, Metis
always tries to balance the number of nodes in each partition.
* ``balance_ntypes`` balances the number of nodes of different types in each partition.
* ``balance_edges`` balances the number of edges in each partition.
To balance the node types, a user needs to pass a vector of N elements to indicate
the type of each node. N is the number of nodes in the input graph.
本质上,“node_map”和“edge_map”是字典。关键字是节点/边类型。这些值是包含分区中相应类型的ID范围的开始和结束的成对列表。列表的长度是分区的数量;列表中的每个元素都是存储分区中特定节点/边类型的ID范围的开始和结束的元组。
分区的图形结构存储在DGLGraph格式的文件中。每个分区中的节点都被*重新标记*为总是从零开始。我们将原始图中的节点ID称为*全局ID*,而将每个分区中重新标记的ID称为*本地local ID*。每个划分图都有一个以名称“dgl.NID”存储的整数节点数据张量,每个值都是节点的全局ID。类似地,边也被重新标记,并且从局部ID到全局ID的映射被存储为名为“dgl.EID”的整数边数据张量。对于异构图,DGLGraph还包含用于节点类型的节点数据“dgl.NTYPE”和用于边类型的边数据“dgl.ETYPE”。
分区图包含附加的节点数据(“inner_node”和“orig_id”)和边数据(“inner _ edge”):
*“inner _ node”表示一个节点是否属于一个分区。
*“inner _ edge”指示边缘是否属于分区。
*“orig _ id”在reshuffle=True时存在。它指示在重组之前原始图中的原始节点id。
节点和边特征被分割并与每个图分区一起存储。分区中的所有节点/边要素都存储在DGL格式的文件中。节点/边特征存储在字典中,其中关键字是节点/边数据名称,值是张量。我们不存储边缘节点和边缘的特征。
在执行Metis分区时,我们可以对分区设置一些约束。目前,它支持两种约束来平衡分区。默认情况下,Metis总是试图平衡每个分区中的节点数量。
balance _ ntypes”平衡每个分区中不同类型的节点数量。
balance _ edges”平衡每个分区中的边数。
为了平衡节点类型,用户需要传递N个元素的向量来指示每个节点的类型。N是输入图中的节点数。
Parameters
----------
g : DGLGraph
The input graph to partition
graph_name : str
The name of the graph. The name will be used to construct
:py:meth:`~dgl.distributed.DistGraph`.
num_parts : int
The number of partitions
out_path : str
The path to store the files for all partitioned data.
num_hops : int, optional
The number of hops of HALO nodes we construct on a partition graph structure.
The default value is 1.
part_method : str, optional
The partition method. It supports "random" and "metis". The default value is "metis".
reshuffle : bool, optional
Reshuffle nodes and edges so that nodes and edges in a partition are in
contiguous ID range. The default value is True. The argument is deprecated
and will be removed in the next release.
重新排列节点和边,使分区中的节点和边位于连续的ID范围内。默认值为True。该参数已被弃用,将在下一版本中删除。
balance_ntypes : tensor, optional
Node type of each node. This is a 1D-array of integers. Its values indicates the node
type of each node. This argument is used by Metis partition. When the argument is
specified, the Metis algorithm will try to partition the input graph into partitions where
each partition has roughly the same number of nodes for each node type. The default value
is None, which means Metis partitions the graph to only balance the number of nodes.
每个节点的节点类型。这是一个整数的1D数组。它的值指示每个节点的节点类型。Metis分区使用此参数。指定参数后,Metis算法将尝试将输入图划分为多个分区,其中每个分区对于每种节点类型具有大致相同数量的节点。默认值是None,这意味着Metis对图进行分区,只平衡节点的数量。
balance_edges : bool
Indicate whether to balance the edges in each partition. This argument is used bythe Metis algorithm.
return_mapping : bool
If `reshuffle=True`, this indicates to return the mapping between shuffled node/edge IDs
and the original node/edge IDs.
num_trainers_per_machine : int, optional
The number of trainers per machine. If is not 1, the whole graph will be first partitioned
to each trainer, that is num_parts*num_trainers_per_machine parts. And the trainer ids of
each node will be stored in the node feature 'trainer_id'. Then the partitions of trainers
on the same machine will be coalesced into one larger partition. The final number of
partitions is `num_part`.
每台机器的trainer数量。如果不为1,整个图形将首先划分给每个trainer,即num _ parts * num _ trainers _ per _ machine parts。并且每个节点的trainer id将被存储在节点特征‘trainer id’中。那么同一台机器上的训练器的分区将被合并成一个更大的分区。分区的最终数量是“num_part”。
objtype : str, "cut" or "vol"
Set the objective as edge-cut minimization or communication volume minimization. Thisargument is used by the Metis algorithm. 将目标设置为边缘切割最小化或通信量最小化。Metis算法使用此参数。
Returns
-------
Tensor or dict of tensors, optional
If `return_mapping=True`, return a 1D tensor that indicates the mapping between shuffled
node IDs and the original node IDs for a homogeneous graph; return a dict of 1D tensors
whose key is the node type and value is a 1D tensor mapping between shuffled node IDs and
the original node IDs for each node type for a heterogeneous graph.
Tensor or dict of tensors, optional
If `return_mapping=True`, return a 1D tensor that indicates the mapping between shuffled
edge IDs and the original edge IDs for a homogeneous graph; return a dict of 1D tensors
whose key is the edge type and value is a 1D tensor mapping between shuffled edge IDs and
the original edge IDs for each edge type for a heterogeneous graph.
张量或张量字典,如果“return_mapping=True”则可选,返回1D张量,该张量指示同质图的混洗节点id和原始节点id之间的映射;返回1D张量的字典,其关键字是节点类型,值是异构图中每个节点类型的混洗节点id和原始节点id之间的1D张量映射。
Examples
--------
>>> dgl.distributed.partition_graph(g, 'test', 4, num_hops=1, part_method='metis',
... out_path='output/', reshuffle=True,
... balance_ntypes=g.ndata['train_mask'],
... balance_edges=True)
>>> g, node_feats, edge_feats, gpb, graph_name = dgl.distributed.load_partition(
... 'output/test.json', 0)
'''
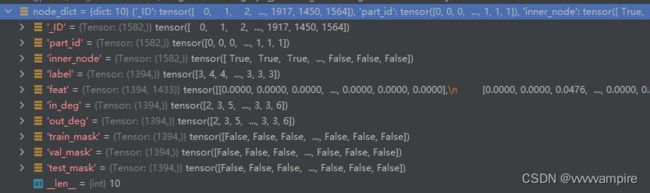
{'_ID': tensor([ 0, 1, 2, ..., 1917, 1450, 1564]), 'part_id': tensor([0, 0, 0, ..., 1, 1, 1]), 'inner_node': tensor([ True, True, True, ..., False, False, False]), 'label': tensor([3, 4, 4, ..., 3, 3, 3]), 'feat': tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0476, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]), 'in_deg': tensor([2, 3, 5, ..., 3, 3, 6]), 'out_deg': tensor([2, 3, 5, ..., 3, 3, 6]), 'train_mask': tensor([False, False, False, ..., False, False, False]), 'val_mask': tensor([False, False, False, ..., False, False, False]), 'test_mask': tensor([False, False, False, ..., False, False, False])}