Doris---数据表设计
表的基本概念
1 Row & Column
一张表包括行(Row)和列(Column);
Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
doris中的列分为两类:key列和value列
key列在doris中有两种作用:
聚合表模型中,key是聚合和排序的依据
其他表模型中,key是排序依据
2 分区与分桶
-
partition(分区):是在逻辑上将一张表按行(横向)划分
-
tablet(又叫bucket,分桶):在物理上对一个分区再按行(横向)划分

2.1 Partition
-
Partition 列可以指定一列或多列,在聚合模型中,分区列必须为 KEY 列。
-
不论分区列是什么类型,在写分区值时,都需要加双引号。
-
分区数量理论上没有上限。
-
当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改。
-
创建分区时不可添加范围重叠的分区。
1)Range 分区
range分区创建语法
-- Range Partition
drop table if exists test.expamle_range_tbl;
CREATE TABLE IF NOT EXISTS test.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别"
)
ENGINE=OLAP
DUPLICATE KEY(`user_id`, `date`) -- 表模型
-- 分区的语法
PARTITION BY RANGE(`date`) -- 指定分区类型和分区列
(
-- 指定分区名称,分区的上界 前闭后开
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1;
-
分区列通常为时间列,以方便的管理新旧数据。
-
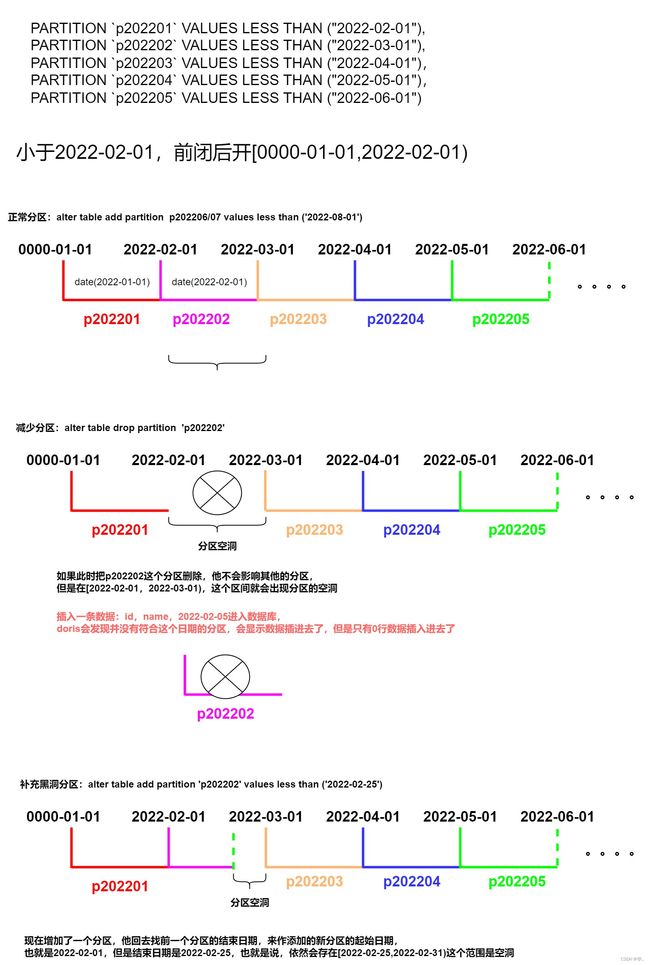
Partition 支持通过 VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。同时,也支持通过 VALUES [...) 指定上下界,生成一个左闭右开的区间。
-
通过 VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (...) 语句进行分区的增删操作时,分区范围的变化情况:
当 我们删除分区
p201702 和 p201705 的分区范围并没有发生变化,而这两个分区之间,出现了一个空洞:[2017-03-01, 2017-04-01)。即如果导入的数据范围在这个空洞范围内,是无法导入的。
2)List 分区
-
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
-
Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。
-
下面通过示例说明,进行分区的增删操作时,分区的变化。
List分区创建语法
-- List Partition
CREATE TABLE IF NOT EXISTS test.expamle_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",
`age` SMALLINT NOT NULL COMMENT "用户年龄",
`sex` TINYINT NOT NULL COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
-- 指定分桶的语法
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES
(
"replication_num" = "3"
);如上 example_list_tbl 示例,当建表完成后,会自动生成如下3个分区:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
List分区也支持多列分区,示例如下
PARTITION BY LIST(`id`, `city`)
(
PARTITION `p1_city` VALUES IN (("1", "Beijing",), ("2", "Shanghai")),
PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("1", "Shanghai")),
PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("4", "Shanghai"))
)Bucket
-
如果使用了 Partition,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。
-
分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
-
分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
-
如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
-
如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
-
-
分桶的数量理论上没有上限

关于 Partition 和 Bucket的数量和数据量的建议。
-
一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
-
一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
-
单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。分桶应该控制桶内数据量 ,不易过大或者过小
-
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
-
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
-
一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
小例子:
假设在有10台BE,每台BE一块磁盘的情况下。 ==> 总共有多少个磁盘数量 按照数量原则 10 15
如果一个表总大小为 500MB,则可以考虑4-8个分片。 5个
5GB:8-16个分片。
50GB:32个分片。
500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。
5TB:建议分区,每个分区大小在 500GB 左右,每个分区16-32个分片。