@开源爱好者,字节跳动这项技术,正式宣布开源了
告诉大家一个好消息,字节跳动的云原生数据仓库 ByConity 正式宣布开源了。
ByConity 是一个云原生数据仓库,由字节跳动数据平台团队在国际知名开源数据库管理系统 ClickHouse 社区版本基础上开发。
早期,字节跳动的数据存储使用的是 ClickHouse 的开源版本。但由于业务体量大、业务场景复杂,数据平台团队对此进行了大量的深度优化和自研改进,用以支撑字节跳动业务中各类与数据相关的功能模块,现在正式宣布开源,回馈社区。此前,字节跳动还发布过云原生数据仓库的商业化版本 ByteHouse。
ByConity 开源之前,字节跳动数据平台团队也曾考虑将自研修改合并回 ClickHouse 社区,与 ClickHouse 核心研发团队、ClickHouse 创业公司负责人沟通后,得到的反馈是架构差异过大、合并难度和代价大、无法联合开发。按照 ClickHouse 社区给到的建议,数据平台团队决定独立开源。
ByConity 具有读写分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等特点,其计算-存储分离的架构,结合主流的 OLAP 引擎优化,确保了优异的读写性能。
今年 1 月,ByConity Beta 版本发布后,得到了来自华为、电子云、展心展力、天翼云、唯品会、传音控股等十几家企业开发者的支持,他们帮助 ByConity 在各自的场景下进行了测试与验证,并反馈出不错的效果。
话不多说,先上 GitHub 地址:
GitHub - ByConity/ByConity: ByConity is an open source cloud-native data warehouse
ByConity:三层架构的数据仓库
ByConity 的整体架构分为三层,包括服务接入层,计算层和数据存储层。
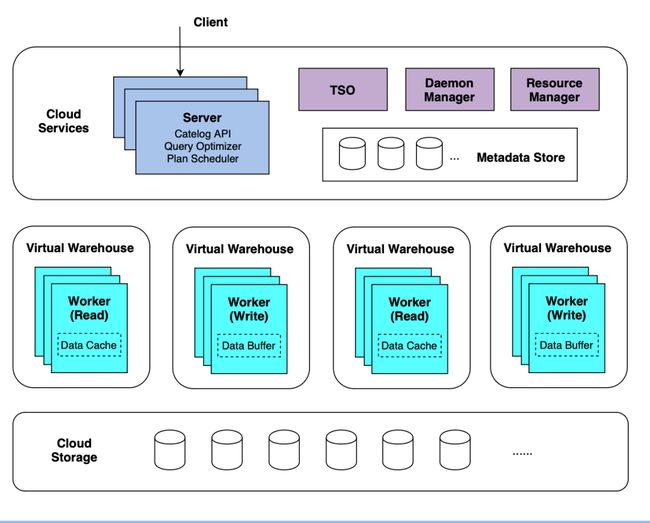
ByConity 三层技术架构图
服务接入层:
接受用户的查询,由一个或者多个 server 构成,并支持水平扩张,充当的是响应用户服务和协调调度的角色。除了用户作业之外,在 ByConity 里还有后台任务,例如 compaction/gc 等等,这些后台任务由 Daemon manager 管理,调度到相应的 server 进行执行。
计算层:
由一个或者多个计算组(Virutual Warehouwe,VW)构成,不同的租户可以使用不同的计算组实现物理资源隔离。资源管理器负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据、资源使用量,为查询、写入和后台任务动态分配资源并进行动态扩缩容,提高资源使用率。
数据存储层:
用于存放用户数据。ByConity 的元数据和数据都实现了存储计算分离,元数据存储在分布式 key-value store 里,数据存储在分布式文件系统或者对象存储里。
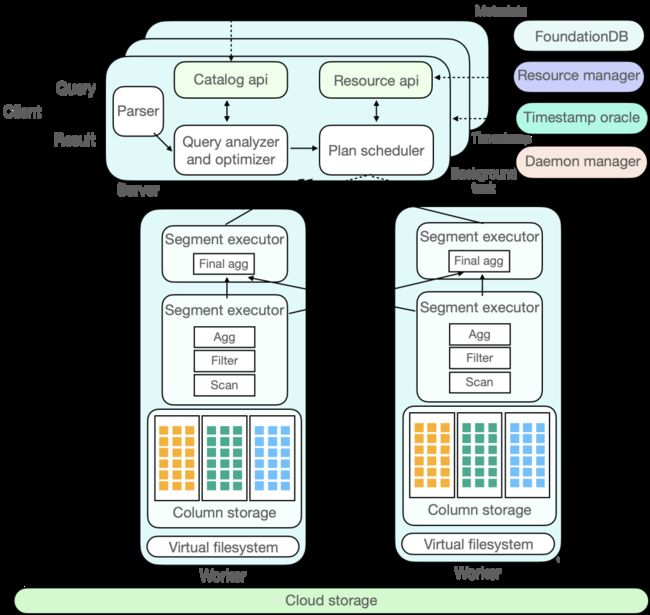
ByConity 内部组件交互图
目前,ByConity 支持单机 Docker、K8s 集群部署、物理机部署和源代码编译四种获取和部署模式。
五年时间,从 ClickHouse 到 ByConity
2018 年,字节跳动开始在内部使用 ClickHouse,因为业务发展迅速、用户体量大,数据规模变得越来越巨大。
由于 ClickHouse 是 Shared-Nothing 架构,每个节点相互独立,不会共享存储资源等,因而计算资源和存储资源紧耦合,这使它在字节跳动的应用过程中产生了一些不便之处。
比如扩缩容的成本比较高,且会涉及到数据迁移,不能实时按需扩缩容,导致资源浪费;比如多租户在共享集群环境相互影响,同时由于读写在同一个节点完成,导致读写相互影响;此外,ClickHouse 在复杂查询上例如多表 Join 等操作的性能支持并不是很好。
因此,字节跳动于 2020 年在内部启动了 ByConity 项目,在原有的 ClickHouse 架构基础上进行了升级,将原本计算和存储分别在每个节点本地管理的架构,转换为在分布式存储上统一管理整个集群内所有数据的架构,使得每个计算节点成为一个无状态的单纯计算节点,并利用分布式存储的扩展能力和计算节点的无状态特性实现动态的扩缩容。
这种改进使得升级后的架构具有以下重要特性:
- 资源隔离:对不同的租户进行资源的隔离,租户之间不会受到相互影响;
- 读写分离:计算资源和存储资源解耦,确保读操作和写操作不会相互影响;
- 弹性扩缩容:支持弹性的扩缩容,能够实时、按需的对计算资源进行扩缩容,保证资源的高效利用;
- 数据强一致:数据读写的强一致性,确保数据始终是最新的,读写之间没有不一致;
- 高性能:采用了主流的 OLAP 引擎优化,例如列存、向量化执行、MPP 执行、查询优化等提供优异的读写性能。
随着对自研表引擎、查询优化器、存储计算架构的优化与自研改造,字节跳动内部有越来越多的场景逐步使用新架构,也在不同的场景中进行了验证与优化,慢慢沉淀出了一个云原生版本的数仓 ByConity。
加入字节跳动,一起做开源
字节跳动还将继续增强 ByConity 的功能、性能和易用性,其中开发新的存储引擎、支持更多的数据类型和与其他数据管理工具的集成是重点关注的领域。
具体包含以下几个方向:
- 性能提升:使用索引进行加速,包含 Skip-index 优化、新的 Zorder-index 和倒排索引等支持、外表索引的构建和加速、以及索引的自动推荐和转换;查询优化器的持续优化;分布式缓存机制等。
- 稳定性提升:支持更多维度的资源隔离,提供更好多租户能力;丰富 Metrics,提升可观察性和问题诊断能力。
- 企业级特性增强:实现更细粒度权限控制;完善数据安全性相关的功能(备份、恢复和数据加密);持续探索数据的深度压缩,节约存储成本。
- 生态兼容性提升:支持 S3、TOS 等对象存储;提升生态兼容性方便集成;支持数据湖联邦查询如 Hudi、Iceberg等。
除开源版本之外,ByConity 产研团队还同时支持商业化版本 ByteHouse 和字节内部产品线,ByConity 即为 ByteHouse 的内核。团队相关负责人表示,开源版和商业版融合度非常高,未来 ByConity 会朝更加开放的引擎开发模式发展,后续对 ByteHouse 的改动会基于 ByConity 源代码用开源的方式来开发,开源先行,同步发展。