如何利用Python爬虫,高效获取大规模数据
分享前的小唠叨:
针对一些小站的话,单机Scrapy爬虫方式完全够用,杀鸡焉用牛刀?
针对一些大站的话,这个时候可能就显得有些无力了。这个时候如果你还是继续选择单机Scrapy采集… 过了几天后…
老大或者老板:嗨!采集的怎么样了?数据都采集完了吧?
你说:这个网站数据量真的是巨大啊!我都跑了三天三夜了。正采集着呢!放心吧,我刚初步瞄了一下应该再采三天三夜基本就差不多了! 说到这里!
Ta可能扛着40米的牛刀正朝你走来…
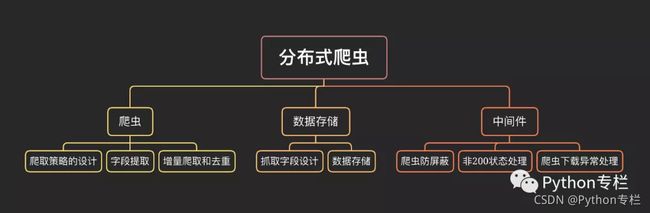
看到上面这几句对话,你就可以猜到我们本次文章的主题啦!对,分布式爬虫!!!
什么是分布式爬虫?
分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。
其实搜索引擎都是爬虫,负责从世界各地的网站上爬取内容,当你搜索关键词时就把相关的内容展示给你,只不过他们那都是非常大的爬虫,爬的内容量也超乎想象,所以也就无法再用单机爬虫去实现了,而是考虑使用分布式爬虫。要想更加清楚的理解上图并使用分布式爬虫,我们首先了解下之前一直使用的单机Scrapy。
Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。如果新的Request生成就会放到队列里面,随后Request被Scheduler调度。之后,Request交给Downloader执行爬取,简单的调度架构如下图所示。
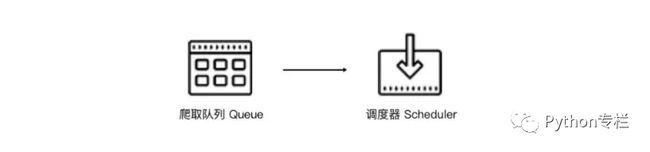
单机爬虫的问题:
- 一台计算机的效率问题
- IO 的吞吐量,传输速率也有限
如果两个Scheduler同时从队列Queue里面取Request,每个Scheduler都有其对应的Downloader,如果爬取的机器带宽是足够的且正常爬取,不考虑队列存取压力的情况下,爬取效率则会翻倍。
于是为了提高效率Scheduler可以扩展多个,Downloader也可以扩展多个。而爬取队列Queue则始终为一个即共享爬取队列。之所以保持一个共享爬取队列是保证Scheduer从队列里调度某个Request之后,其他Scheduler不会重复调度此Request,就可以做到多个Schduler同步爬取。
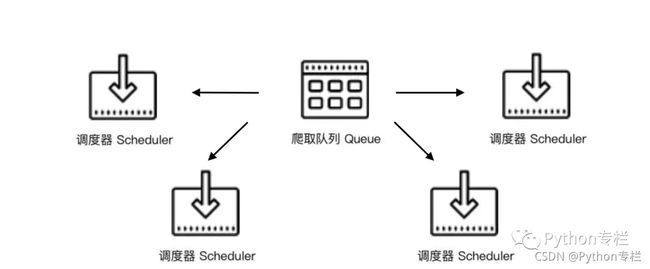
通过上图我们了解到,需要做的就是在多台主机上同时运行爬虫任务协同爬取,而协同爬取的前提就是共享爬取队列。这样各台主机就不需要各自维护爬取队列,而是从共享爬取队列存取 Request。但是各台主机还是有各自的 Scheduler 和 Downloader,所以调度和下载功能分别完成。
要实现上面设计的思路,使用什么实现共享队列Queue的功能?如果我们还要兼顾性能,并且能达到更好的存取效率,基于内存的Redis就是最好的选择。Redis可以支持多种数据结构,存取的操作也非常简单。
Scrapy_redis安装与使用
很多人都知道Scrapy它是一个通用的爬虫框架,但是并不能支持分布式。而Scrapy-redis则是为了更方便的实现Scrapy分布式采集而提供了以redis为基础的组件,Scrapy-Redis 库已经为我们提供了 Scrapy 分布式的队列、调度器、去重等功能。所以Scrapy_redis是一套基于Scrapy框架之上的一套组件,它是一个提供可以支持分布式的组件,Scrapy-redis重写了Scrapy一些比较关键的代码,从而用来替换Scrapy本身的一些东西,让Scrapy拥有了支持分布式的功能。
scrapy-redis安装
安装:pip install scrapy-redis
详细内容可以参照其站点:https://github.com/rmax/scrapy-redis
可以使用git下载源代码:
git clone https://github.com/rmax/scrapy-redis.git
scrapy原生架构:
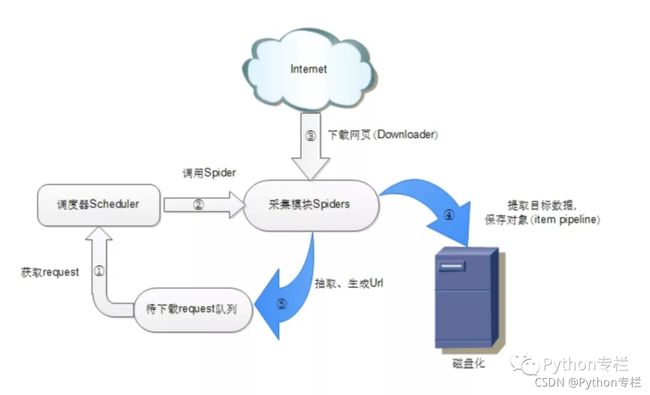
原生架构中有调度器Scheduler、Spiders、Item Pipeline等部分。
调度器(Scheduler):调度器维护request 队列,每次执行取出一个request。
Spiders:Spider是Scrapy用户编写用于分析response,提取item以及跟进额外的URL的类。每个spider负责处理一个特定(或一些)网站。
Item Pipeline:Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
Scrapy-redis架构图
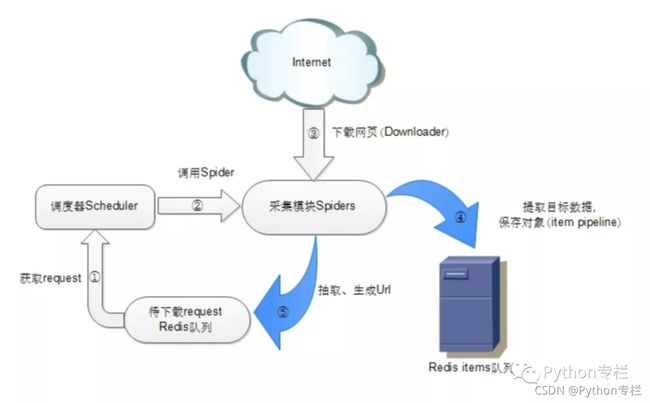
scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
1)Scheduler(调度器)
Scrapy 改造了 python 本来的 collection.deque(双向队列)形成了⾃⼰的Scrapy queue,但是 Scrapy 多个 spider 不能共享待爬队列 Scrapy queue, 即 Scrapy 本 身不⽀持爬⾍分布式,scrapy-redis是把Scrapy框架中的 Scrapy queue 换成 redis数 据库,从同⼀个 redis-server 存放要爬取的 request。
Scrapy 中跟“待爬队列”直接相关的就是调度器 Scheduler ,它负责对新的request 进⾏⼊列操作(即加⼊Scrapy queue),取出下⼀个要爬取的 request(从 Scrapy queue 中取出)等操作。
它把待爬队列按照优先级建⽴了⼀个字典结构,⽐如:
{
优先级 0 : 队列0,
优先级 1 : 队列1,
优先级 2 : 队列2
}
然后根据 request 中的优先级,来决定该⼊哪个队列,出列时则按优先级较⼩的优先出列。
为了管理这个⽐较⾼级的队列字典,Scheduler 需要提供⼀系列 的⽅法。但是原来的 Scheduler 已经⽆法使⽤,所以使⽤Scrapy-redis 的scheduler 组件。
2)Duplication Filter(requst的去重过滤器)
Scrapy 中⽤集合实现这个 request 去重功能,Scrapy 中把已经发送的 request指纹放⼊到⼀个集合中,把下⼀个 request 的指纹拿到集合中⽐对,如果该指纹存在于集合中,说明这个 request 发送过了,如果没有则继续操作。这个核⼼的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints 就是⼀个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核⼼操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由 Duplication Filter 组件来实现的,它通过redis的set不重复的特性,巧妙的实现了Duplication Filter去重
scrapy-redis调度器从引擎接受request,将request的指纹存入redis的set检查是否重复,并将不重复的request push写入redis的request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
举个栗子:
我们现在有一个爬虫,它已经运行采集了一段时间,但是这个时候呢,可能因为人为操作或者异常情况导致它中断了。那么我们再执行的时候它会接着读取redis数据库里面的请求指纹,之前采集过的它自然就不会再去发送了。
如果这个爬虫我们用Scrapy来做的话,它就不能像以上情况一样,一旦中断内存就会被清空了,再次采集就要从头继续了!也就是说一招回到解放前…
3)Item Pipeline(将Item存储在redis中以实现分布式处理)
引擎将(Spider 返回的)爬取到的 Item 给 Item Pipeline,scrapy-redis 的Item Pipeline 将爬取到的 Item 存⼊redis 的 items queue。
修改过 Item Pipeline 可以很⽅便的根据 key 从 items queue 提取 item,从⽽实现 items processes 集群。
4)Base Spider
不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
- 一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
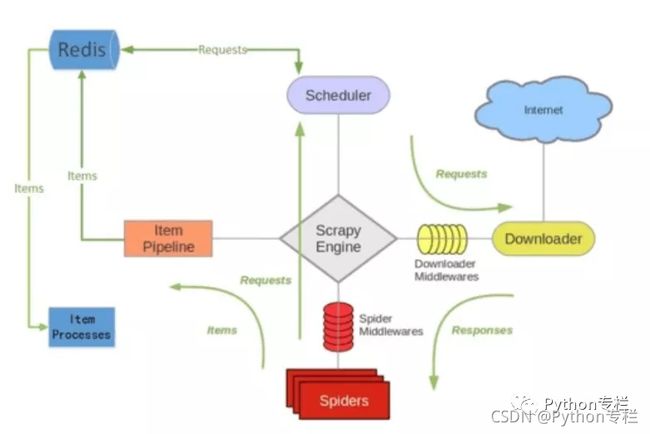
Scrapy-Redis分布式策略
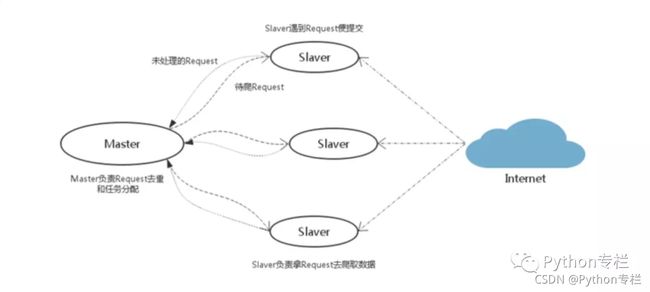
分布式爬取的结构采用的是主从模式。
主从模式,就是由一台服务器充当 master,若干台服务器充当 slave,master 负责管理所有连接上来的 slave,包括管理 slave 连接、任务调度与分发、结果回收并汇总等;每个 slave 只需要从 master 那里领取任务并独自完成任务最后上传结果即可,期间不需要与其他 slave 进行交流。这种方式简单易于管理。
即设置一个Master服务器和多个Slave服务器,Master端管理Redis数据库和分发下载任务,Slave部署Scrapy爬虫提取网页和解析提取数据,最后将解析的数据存储在同一个MongoDb数据库中。
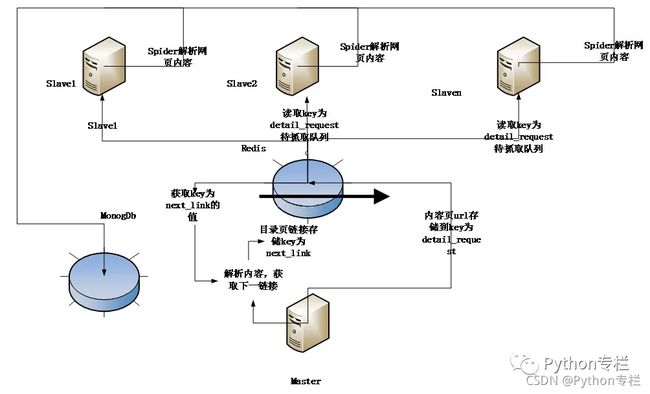
**优点:**Scrapy-redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-redis都已经帮我们做好了,我们只需要继RedisSpider、指定redis_key就行了。
**缺点:**Scrapy-redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间。当然我们可以重写方法实现调度url。
特别强调:
使用Scrapy-redis是要使用本地的redis数据库的,所以必须要提前安装好Redis数据库。
windows版 https://github.com/tporadowski/redis/releases
windows操作系统,64位版,截至发文,已经更新到了5.0.10,网上大部分教程却只停留在3.X版本。点击上面链接,即可下载(我用的是IDM下载插件)。如果觉得版本高的话,还可以点击“Next”,去下一页查找。
Linux版: https://redis.io/
点击,即可下载,在redis官网上只能下载Linux版本
Mac版: 使用Homebrew安装命令:brew install redis 安装完毕之后会有启动提示:
使用redis-cli连接redis服务
因为Master端需要slave端进行远程访问需要修改配置文件:
修改redis.conf配置文件中的下列项:
注释默认配置中所有的绑定bind,以允许所有的IP都可以访问 有的博客讲还需要加一条 bind 0.0.0.0 实测不加也可以,只要把原本所有的bind都注释即可
bind 127.0.0.1 <----注释掉这句话
取消注释,设置密码,因为允许任意IP访问,强烈建议配置密码避免redis裸奔
否则马上就有一些挖矿病毒进入迅速占据你的虚拟机
requirepass 你的密码
修改no 为yes,允许redis后台运行
daemonize yes
修改yes为no,关闭保护模式,允许远程任意IP访问
protected-mode no
Scrapy-redis实战
搭建redis分布式,Master端Mac的IP地址为:192.168.2.1
1)Master端按指定配置文件启动 redis-server,示例:
Mac系统:sudo redis-server /usr/local/etc/redis.conf
Windows系统:命令提示符(管理员)模式下执行 redis-server.exe redis.windows.conf读取默认配置即可
2)Master端启动本地redis-cli

3)slave端启动redis-cli -h 192.168.2.1 –a running,-h参数表示连接到指定主机的redis数据库, -a参数表示需要密码

4) 再启动一个slave端查看存入的数据

预告:分布式爬虫之IP代理池和Cookies池
Scrapy整体的系统功能架构图如下图: